
df_0011
균형 잡힌 시스템 vs 불균형한 시스템
(Balanced vs. Unbalanced)
Forkless Snapshot
삶에서 균형은 필수적입니다. 우리의 초점이 삶의 단일한 측면을 개선하는 데만 국한될 때,
우리는 전체 시스템을 약화시킵니다. 그리고 시스템에 안정성을 제공하지 않으면, 결국 자체 무게를 이기지 못하고
무너져 내리거나 부서지게 됩니다.
Redis를 예로 들어보겠습니다. Redis는 비교적 높은 처리량(throughput)을 지원하지만,
데이터를 저장하는 영속성(persistency) 메커니즘은 높은 부하를 감당하도록 설계되지 않았습니다.
즉, Redis의 쓰기 처리량이 높아질수록 시스템은 더욱 취약해집니다.
그 이유를 이해하기 위해 먼저 Redis의 `BGSAVE` 스냅샷이 어떻게 작동하는지 설명해야 합니다.
💡 해설:
이 글의 핵심 주제인 '성능과 안정성의 균형'을 화두로 던집니다.
대표적인 인메모리 DB인 Redis는 엄청나게 빠른 속도를 자랑하지만, 메모리의 데이터를 하드디스크에
백업(영속성 보장)할 때는 그 빠른 속도 때문에 오히려 시스템이 불안정해지는 모순(불균형)을 안고 있다는
점을 지적합니다.
⬜️
Balanced vs. Unbalanced 원문(영어)
📦 Redis Snapshotting (Redis의 스냅샷 방식)]
`BGSAVE` 알고리즘은 백그라운드 프로세스를 통해 Redis가 인메모리 데이터의 특정 시점(point-in-time)
스냅샷을 디스크에 생성하거나 보조 복제본과 동기화할 수 있게 해줍니다.
Redis는 운영체제(Linux)의 `fork()` 함수를 호출하여 부모의 메모리에 접근할 수 있는 자식 프로세스를
생성하는 방식으로 이 작업을 수행합니다. 이 시점부터 두 프로세스는 동일한 내용을 공유하며 물리적 메모리
사용량도 동일하게 유지됩니다. 하지만 둘 중 하나가 메모리에 쓰기(Write) 작업을 하는 순간,
해당 데이터 페이지의 비공개 복사본을 따로 생성하게 됩니다. (이를 Copy-on-Write라고 합니다.)
💡 해설:
Redis가 백업본(스냅샷)을 만드는 원리입니다. 백업을 하려면 잠시 멈춰야 하지만,
서비스 중단을 막기 위해 OS의 `fork()`를 이용해 자신과 똑같은 '자식 프로세스'를 하나 복제합니다.
이때 메모리 공간을 복사하는 것이 아니라 공유만 하다가, 새로운 데이터가 입력(Write)될 때만
그 부분의 메모리를 분리해서 복사(Copy)하는 기법인 `Copy-on-Write(COW)`를 사용합니다.
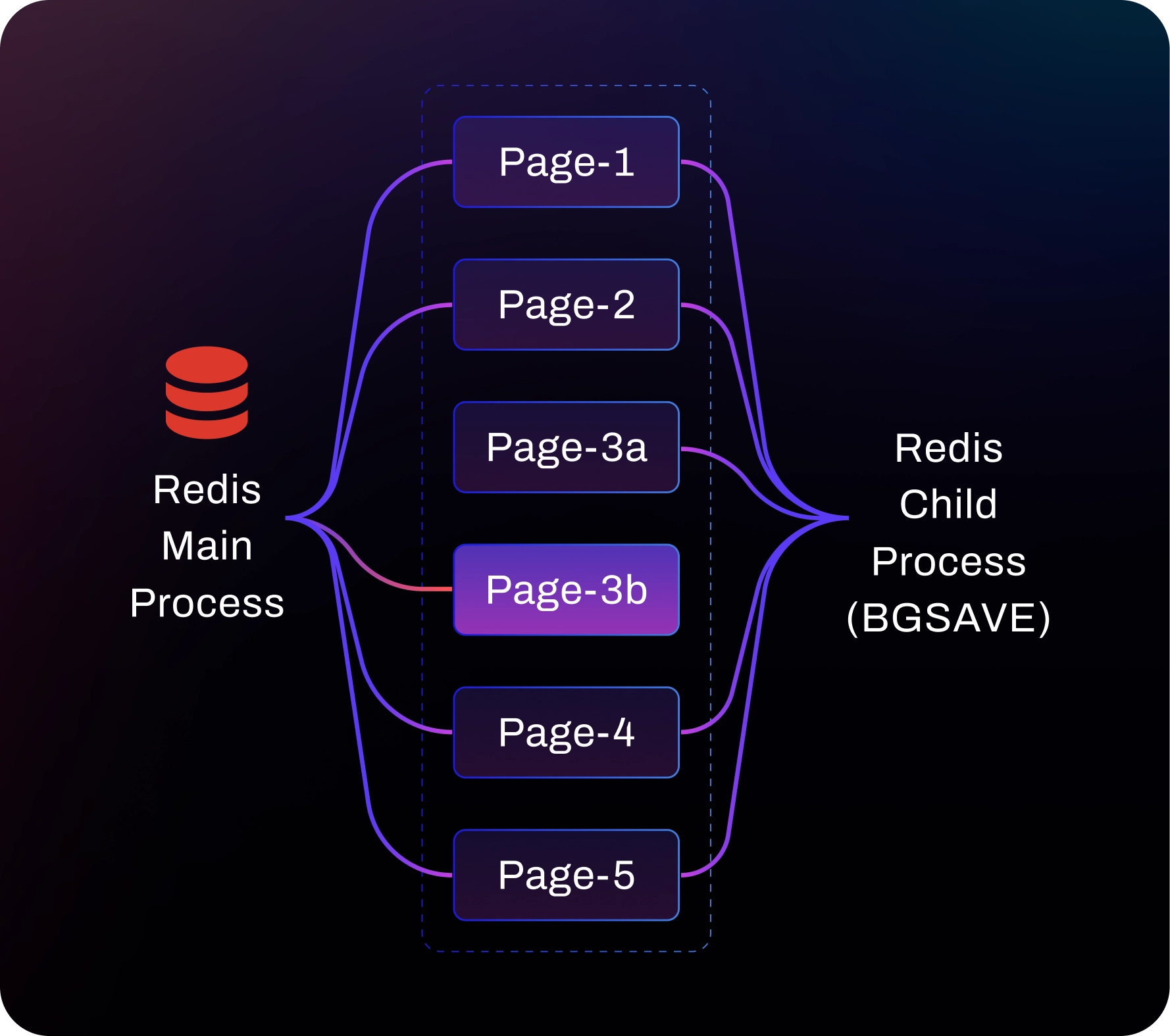
Redis 자식 프로세스는 자신의 메모리 페이지를 변경하지 않습니다.
오직 항목들을 스캔하여 RDB 스냅샷 파일에 기록할 뿐입니다.
한편, 부모 Redis 프로세스는 계속해서 들어오는 쓰기 요청을 처리합니다.
기존 메모리 페이지를 건드리는 새로운 쓰기 작업이 발생할 때마다,
결과적으로 더 많은 물리적 메모리를 할당하게 됩니다.
만약 우리의 Redis 인스턴스가 40GB의 물리적 메모리를 사용한다고 가정해 봅시다.
fork() 이후, 부모 프로세스는 잠재적으로 모든 페이지를 복제할 수 있으며,
이 경우 추가로 40GB의 RAM이 더 필요해져 총 80GB가 필요하게 됩니다.
쓰기 처리량이 충분히 낮다면 모든 페이지를 복제하기 전에 스냅샷 프로세스를 마칠 수도 있습니다.
이 경우 메모리 사용량은 40GB에서 80GB 사이 어딘가에서 정점을 찍게 됩니다.
`BGSAVE` 동안 발생하는 이러한 불확실한 동작은 Redis 배포를 관리하는 팀에게 큰 골칫거리입니다.
이들은 OOM(Out of Memory, 메모리 부족 현상) 위험을 막기 위해 항상 메모리를 과도하게
프로비저닝(초과 할당)해 두어야 합니다.
💡 해설: Redis의 약점을 명확히 보여주는 부분입니다. 백업을 하는 동안 새로운 데이터가 너무 많이 들어오면,
COW 현상으로 인해 메모리가 분리되면서 최악의 경우 원래 데이터 크기(40GB)의 두 배(80GB)까지 메모리가
폭증할 수 있습니다. 운영자 입장에서는 백업 중에 서버가 메모리 부족으로 다운되는 것을 막기 위해 항상
비싼 메모리를 여유 있게 꽂아두어야 하는 비용적/관리적 부담을 지게 됩니다.
Redis를 더 빠르게 만들겠다는 목표로 출시된 Redis 포크 버전인 'KeyDB'는 멀티 스레드 아키텍처 덕분에
더 높은 처리량을 유지할 수 있습니다. 하지만 KeyDB에서 `BGSAVE`가 실행되면 어떻게 될까요?
KeyDB 부모 프로세스는 더 많은 쓰기 트래픽을 처리할 수 있으므로, 스냅샷이 끝나기도 전에 자식 프로세스와
공유하는 메모리 페이지를 훨씬 더 많이 변경해 버립니다.
결과적으로 물리적 메모리 사용량이 급증하여 전체 시스템이 OOM의 훨씬 더 큰 위험에 처하게 됩니다.
이것이 KeyDB의 잘못일까요? 아닙니다. KeyDB가 기본적으로 메모리를 더 먹는 것도 아니고,
`BGSAVE` 알고리즘은 Redis와 똑같기 때문입니다.
하지만 안타깝게도 Redis의 불균형한 아키텍처 내에서 단일 문제(성능)만 해결하려다 보니
다른 문제(안정성 저하)를 유발하고 만 것입니다.
이러한 편협한 접근 방식은 KeyDB에만 국한되지 않습니다.
AWS ElastiCache는 멀티 CPU 환경에서 Redis 인스턴스의 처리량을 높이는 유사한 비공개(closed-source) 기능을
도입했습니다. 제 테스트에 따르면, 이 역시 동일한 문제를 겪습니다.
높은 처리량 상황에서 스냅샷 생성에 아예 실패해 버리거나,
스냅샷을 위해 처리량을 15K QPS(초당 쿼리 수) 미만의 터무니없는 수준으로 스스로 떨어뜨려 버립니다.
💡 해설: 단순히 속도만 끌어올렸을 때 발생하는 부작용입니다. KeyDB나 AWS ElastiCache는 Redis보다 데이터를
훨씬 빠르게 처리합니다. 문제는 데이터 처리 속도가 빠른 만큼, 백업 중에 데이터가 변경되는 속도도 빠르다는 것입니다.
결국 메모리 두 배 팽창이 더 빨리 발생하여 서버가 더 쉽게 죽어버리거나,
이를 막기 위해 스스로 성능에 심각한 제한을 걸어버리는 결과를 낳습니다.
📦 Dragonfly Snapshotting (Dragonfly의 스냅샷 방식)
한 걸음 물러서서 이 문제를 공식화해 보겠습니다. 특정 시점 스냅샷을 수행할 때 가장 큰 과제는 레코드들이
병렬로 변경될 때 '스냅샷 격리(snapshot isolation)' 속성을 유지하는 것입니다.
즉, 스냅샷이 시간 't'에 시작하여 t+u에 끝난다면, 디스크에 저장된 스냅샷은
모든 데이터의 시간 t 시점 상태를 정확히 반영해야 합니다.
따라서 우리는 계속 들어오는 새로운 업데이트로 인해 수정되어야 하지만,
아직 스냅샷에 기록(직렬화)되지 않은 레코드들을 처리할 설계 방식이 필요합니다.
이는 결국 다음 질문으로 귀결됩니다.
"우리의 스냅샷 루틴에서 어떤 항목이 이미 기록되었고, 어떤 항목이 아직 기록되지 않았는지 도대체 어떻게 식별할 것인가?"
💡 해설: Dragonfly 개발팀은 기존 Redis가 쓰던 OS의 fork() 기능(메모리 복사 방식)을 버리기로 합니다.
대신, "백업이 시작된 시간(t)의 데이터 상태를 유지하면서, 새로 들어오는 변경 사항들을 어떻게 분리해 낼 것인가?"라는
데이터베이스 자체의 논리적인 문제로 접근합니다.
Dragonfly는 이를 위해 '버전 관리(versioning)'를 사용합니다.
업데이트가 발생할 때마다 1씩 증가하는 카운터를 유지합니다.
저장소의 각 데이터 항목은 자신의 "마지막 업데이트" 버전을 기록하며,
이 버전은 해당 데이터가 스냅샷에 포함되어야 하는지를 결정하는 데 사용됩니다.
스냅샷이 시작되면, 스냅샷은 자신에게 다음 버전을 할당하여 모든 데이터 항목에 대해
`entry.version < snapshot.version (항목의 버전 < 스냅샷의 버전)`이라는 공식을 성립시킵니다.
📍 DragonflyDB ver 1.34.3: 실제 구현에서 'entry'는 키(key) 데이터가 아니고 버킷(bucket)입니다.
즉, 버킷 단위로 버전을 관리합니다. 버킷 단위로 파일에 저장하거나, 복제서버에 전송합니다.
한 버킷에는 최대 14개의 키가 들어갈 수 있습니다.
🔍 • rdb snapshot: 아래 방법으로 📍"시작 시점 데이터 저장"하고 📍"추가 메모리 사용하지 않습니다".
1) bgsave 시작 시점의 버전을 가져온다. snapshot_version_ = NextVersion(version_++)
--------------------------------------------------------------------------
void SliceSnapshot::Start() snapshot_version_ = db_slice_->RegisterOnChange(std::move(db_cb));
uint64_t DbSlice::RegisterOnChange(ChangeCallback cb)
{ return change_cb_.emplace_back(NextVersion(), std::move(cb)).first; }
uint64_t NextVersion() { return version_++; }
uint64_t version() const { return version_; }
uint64_t version_ = 1;
--------------------------------------------------------------------------
2) 버킷을 순회(scan)하면서 버킷 단위로 파일에 저장한다. 이때 버전을 비교한다.
버킷의 버전이 'snapshot_version_'보다 작으면 저장한다. version < snapshot_version_
순서: 버킷 버전 update(snapshot_version_) -> 버킷 데이터 저장
3) 데이터(키/값) 변경이 발생 시 아직 순회하지 않은 버킷이면 해당 버킷 데이터를 rdb 파일에 저장하고
데이터(키/값)을 변경(update)한다. 해당 버킷은 새 버전이 저장된다.
그런 다음 데이터(딕셔너리)를 쭉 순회하며 디스크에 데이터를 기록(직렬화)하기 시작합니다.
이 작업은 아래 코드의 fiber_yield() 호출이 보여주듯 비동기적으로 수행됩니다.
이 루프는 한 번에 멈춤 없이 실행되는 것(atomic)이 아니며, Dragonfly는 순회 중에도 병렬로 들어오는
새로운 쓰기 요청을 받아들일 수 있습니다. 각 쓰기 요청은 데이터를 수정, 삭제 또는 추가할 수 있습니다.
순회 루프에서 데이터의 버전을 확인(`if entry.version < snapshot.version`)함으로써,
한 항목이 두 번 기록되는 것을 막고, 스냅샷 시작 후에 새로 수정된 항목들이 백업되는 것을 방지합니다.
💡 해설: Dragonfly가 메모리 복사 없이 스냅샷을 뜨는 마법의 핵심입니다.
모든 데이터에 '버전 번호'를 매깁니다. 예를 들어 스냅샷을 100번 버전부터 시작한다고 치면,
시스템은 데이터를 처음부터 끝까지 훑으면서 버전이 100보다 작은(즉, 백업 시작 전에 존재했던 원본)
데이터만 디스크에 저장합니다. 중간에 있는 `fiber_yield()`는 "디스크 저장하다가 잠깐 멈추고 새로 들어오는
클라이언트 요청을 처리해!"라는 의미로 시스템이 멈추는 것을 방지합니다.
위의 루프는 해결책의 절반에 불과합니다. 우리는 병렬로 발생하는 실시간 업데이트도 동시에 처리해야 합니다.
이 방식을 통해 아직 기록되지 않은 항목(`snapshot.version`보다 작은 옛날 버전)이 새로운 데이터로 덮어씌워지기 전에,
원본이 먼저 백업(직렬화)되도록 보장합니다.
메인 순회 루프(main traversal loop)와 데이터 업데이트 직전에 가로채는 `OnPreUpdate` 훅(hook),
이 두 가지만으로도 우리는 기존 데이터를 정확히 한 번만 백업하고,
스냅샷 시작 후 새로 추가된 데이터는 무시하는 완벽한 동작을 구현할 수 있습니다.
Dragonfly는 운영체제(OS)의 범용 메모리 관리(fork)에 의존하지 않습니다.
💡 해설: 해결책의 나머지 절반입니다. 시스템이 순차적으로 버전을 확인하며 백업을 하고 있는데,
하필 아직 백업하지 않은 뒷부분의 데이터를 누군가 수정하려고 하면 어떻게 될까요?
그대로 수정해 버리면 백업 시점(t)의 원본 데이터가 날아갑니다.
따라서 Dragonfly는 어떤 데이터가 업데이트되기 직전(`OnPreUpdate`)에 검사하여,
이 데이터가 아직 백업되지 않은 대상이라면 수정을 허락하기 전에 원본 데이터를 디스크에 먼저 저장(백업)해 버립니다.
이를 통해 OS의 도움 없이 애플리케이션 레벨에서 완벽한 스냅샷을 뜰 수 있습니다.
불균형을 초래하는 fork() 호출을 피하고, 업데이트 발생 시 데이터를 강제로 디스크로 밀어 넣는 방식을
통해 Dragonfly는 자연스러운 '백프레셔(back-pressure, 과부하를 막기 위해 처리 속도를 조절하는 메커니즘)'를
확립했습니다. 이는 신뢰할 수 있는 시스템이 반드시 갖춰야 할 요소입니다.
이러한 모든 설계 덕분에 데이터셋의 크기가 아무리 크더라도 스냅샷을 수행하는 동안 Dragonfly의 메모리 추가
오버헤드는 거의 일정하게 유지(Zero에 가깝게 유지)됩니다.
정말 이렇게 간단할까요? 완전히 그렇지는 않습니다. 여기서 설명한 고수준의 알고리즘은 정확하지만,
여러 스레드에 걸쳐 이 작업을 어떻게 동기화하는지, 또는 각 데이터(버킷)마다 8바이트의 `uint64_t` 버전 정보를
추가하면서도 어떻게 메모리 낭비를 없앴는지에 대한 세부 기술은 생략되어 있습니다.
스냅샷 문제가 언뜻 보기에는 그다지 중요하지 않게 보일 수 있습니다.
하지만 이는 사실 Dragonfly를 신뢰할 수 있고 성능이 뛰어나며 확장 가능한 시스템으로 만드는
'균형 잡힌 기초'의 핵심입니다.
스냅샷과 같은 기능이야말로 단순히 속도만 높이려 했던 다른 인메모리 저장소들과 Dragonfly를 차별화하는 기술이며,
전 세계 개발자 커뮤니티 역시 이 가치를 알아봐 주고 있다고 생각합니다.
💡 해설: 글의 결론입니다. Dragonfly는 자체적인 버전 관리 알고리즘을 도입하여,
메모리 폭증 없이 엄청나게 빠른 속도와 안정적인 백업이라는 두 마리 토끼를 모두 잡았습니다.
즉, 서론에서 언급했던 '불균형'을 해소하고 진정한 의미의 '균형 잡힌 시스템'을 만들어 냈다는
강력한 자부심을 보여주는 마무리입니다.
🖥️ 실무에서 700GB 메모리 사용량을 예상하고 여유분 30%을 더해서 메모리 1TB 물리 서버를 구매했는데,
AOF Rewrite 또는 RDB Save가 약 30분 정도 진행되어, 이 시간 동안 데이터가 많이 변경되어
700GB+700GB(COW용)->1.4TB가 사용된다면, 대부분의 경우 물리 서버 메모리 슬롯에 꽂혀있던 메모리를 빼고
2배 용량의 메모리를 구매해서 꽂아야 합니다. 상당히 많은 비용이 지불됩니다.
이 경우 프로젝트 진행 개발사는 매우 어려워지고, 계약에 따라서 이 비용을 모두 개발사가 부담할 수도 있습니다.
따라서 ① AOF Rewrite, ② RDB Save, ③ 복제 전체 동기화 동안 추가 메모리를
적게 사용하는 것은 매우 큰 이점입니다.
