
df_0020
Dragonflydb Dashtable
Dashtable
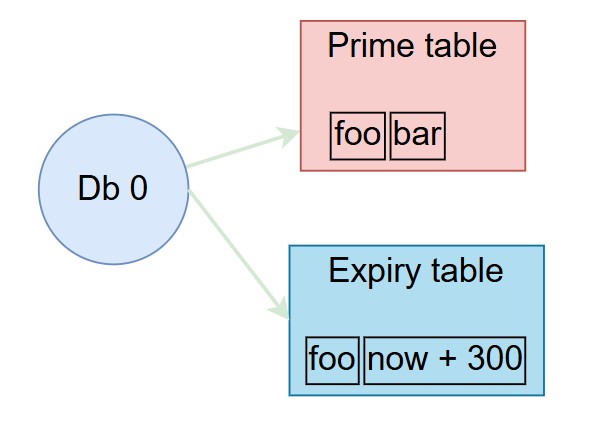
Dashtable은 Dragonfly에서 매우 중요한 데이터 구조입니다.
선택 가능한 각 데이터베이스에는 모든 항목이 포함된 기본 대시 테이블이 있습니다.
Dashtable의 또 다른 인스턴스에는 TTL 만료가 있는 키에 대한 선택적 만료 정보가 포함되어 있습니다.
Dashtable은 Redis 사전과 동일하지만 다양한 상황에서 Dragonfly 메모리를 효율적으로 만드는 몇 가지
훌륭한 속성을 가지고 있습니다.
📦 Redis dictionary
"All problems in computer science can be solved by another level of indirection"
"컴퓨터 과학의 모든 문제는 또 다른 수준의 간접적인 방법으로 해결될 수 있습니다."
이 섹션에서는 Redis Dictionary(RD)가 구현되는 방법을 간략하게 설명합니다.
우리는 아래 블로그 게시물에서 다이어그램을 "사용"했으므로 더 자세히 알고 싶다면 원본 기사를 읽어보세요.
A Closer Look at Redis Dictionary Implementation Internals
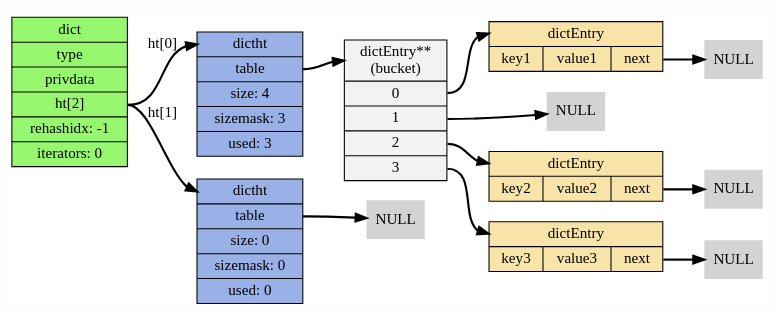
각각은 RD실제로 두 개의 해시 테이블입니다(아래 다이어그램의 ht 필드 참조).
두 번째 인스턴스는 사전(dictionary)의 증가/감소할 때 사용됩니다.
각 해시 테이블은 별도의 체인을 사용하는 클래식 해시 dictht 테이블로 구현됩니다.
테이블 내부의 각 키/값 쌍을 래핑하는 링크 목록 항목입니다.
각 dictEntry에는 3개의 포인터가 있으며 24바이트의 공간을 차지합니다.
dictht의 버킷 배열은 2의 거듭제곱으로 크기가 조정되므로 일반적으로 활용도는 [50, 100] 범위입니다.
RD 내부 dictht 테이블의 오버헤드를 추정해 보겠습니다.
사례 1: 로드율이 100%인 N 항목이 있습니다. 즉, 버킷 수가 항목 수와 같습니다.
각 버킷은 dictEntry에 대한 포인터, 즉 8바이트를 보유합니다. 전체적으로 우리는 다음을 필요로 합니다:
8N + 24N = 32N 레코드당 바이트.
사례 2: N 로드율이 75%인 항목, 즉 버킷 수가 항목 수보다 1.33 더 많습니다.
전체적으로 우리는 다음을 필요로 합니다: N*1.33*8 + 24N = 34N 레코드당 바이트.
사례 3: N로드율이 50%인 항목(예: 테이블 증가 직후) 버킷 수는 항목 수의 두 배이므로 다음이 필요합니다.
N*2*8 + 24N = 40N 레코드당 바이트.
가능한 최선의 경우 키/값 쌍을 테이블에 저장하려면 최소 16바이트가 필요하므로 오버헤드는 dictht 항목당
평균 약 16-24바이트입니다.
이제 점진적인 성장을 고려해 보겠습니다. 가득 차면(즉, RD가 데이터를 더 큰 테이블로 마이그레이션해야 하는 경우)
추가 2*N 버킷을 보유할 ht[0]두 번째 임시 인스턴스를 인스턴스화합니다.
ht[1]모든 데이터가 마이그레이션될 때까지 두 인스턴스 모두 병렬로 유지되며 ht[1]그 후 ht[0]버킷 배열이 삭제됩니다.
이 모든 복잡성은 잘 설계된 RD API를 통해 사용자에게 숨겨져 있습니다.
사례 3과 사례 1을 결합하여 이 시점의 메모리 스파이크를 분석해 보겠습니다.
항목을 ht[0]보유 N하고 완전히 활용됩니다. 버킷 ht[1]으로 할당됩니다 2N.
전반적으로 스파이크 동안 필요한 메모리는 다음과 같습니다.
32N + 16N = 48N 바이트.
요약하면 RD에는 16~32바이트의 오버헤드가 필요합니다.
📦 Dash table
Dashtable is an evolution of an algorithm from 1979 called extendible hashing.
Dashtable은 "확장 가능한 해싱"이라고 불리는 1979년 알고리즘의 진화입니다 .
Dash: Scalable Hashing on Persistent Memory
위키: Extendible hashing
기존 해시테이블과 유사하게 DashTable(DT)도 전(앞)면 포인터 배열을 보유합니다.
그러나 기존 테이블과 달르게, 항목(아이템)의 링크드 리스트를 가리키지 않고, 세그먼트를 가리킵니다.
세그먼트(Segment)는 실제로 일정한 크기의 미니 해시테이블입니다.
세그먼트에 대한 전(앞)면 포인터 배열을 "Segment Directory"라고 합니다.
클래식 테이블과 마찬가지로 항목이 DT에 삽입되면 먼저 항목의 해시 값을 기반으로 대상 세그먼트를 결정합니다.
세그먼트는 공개 주소 해싱 방식을 사용하고 앞서 말했듯이 크기가 일정한 해시 테이블로 구현됩니다.
세그먼트가 결정되면 해당 버킷 중 하나에 항목이 삽입됩니다. 항목이 성공적으로 삽입되면 완료된 것입니다.
그렇지 않으면 세그먼트가 "가득 차서" 분할해야 합니다.
DT는 전체 세그먼트의 내용을 두 개의 세그먼트로 분할하고 추가 세그먼트가 디렉터리에 추가됩니다.
그런 다음 항목을 다시 삽입하려고 시도합니다.
요약하면, 고전적인 체인 해시 테이블은 연결된 목록의 동적 배열을 기반으로 구축되는 반면,
대시테이블은 일정한 크기의 플랫 해시 테이블의 동적 배열과 비슷합니다.

위의 다이어그램에서 대시테이블이 어떻게 보이는지 확인할 수 있습니다.
각 세그먼트는 K개의 버킷으로 구성됩니다.
예를 들어, 구현시 대시 테이블에는 세그먼트당 60개의 버킷이 있습니다(컴파일 시간 매개변수임).
◻️ Segment zoom-in 세그먼트 확대(자세히 보기)
아래에서 세그먼트 다이어그램을 볼 수 있습니다.
일반(regular) 버킷(1~56)과 예비(stash) 버킷(57~60)으로 구성됩니다.
각 버킷에는 k 슬롯이 있으며 각 슬롯은 키-값 레코드를 호스팅할 수 있습니다.
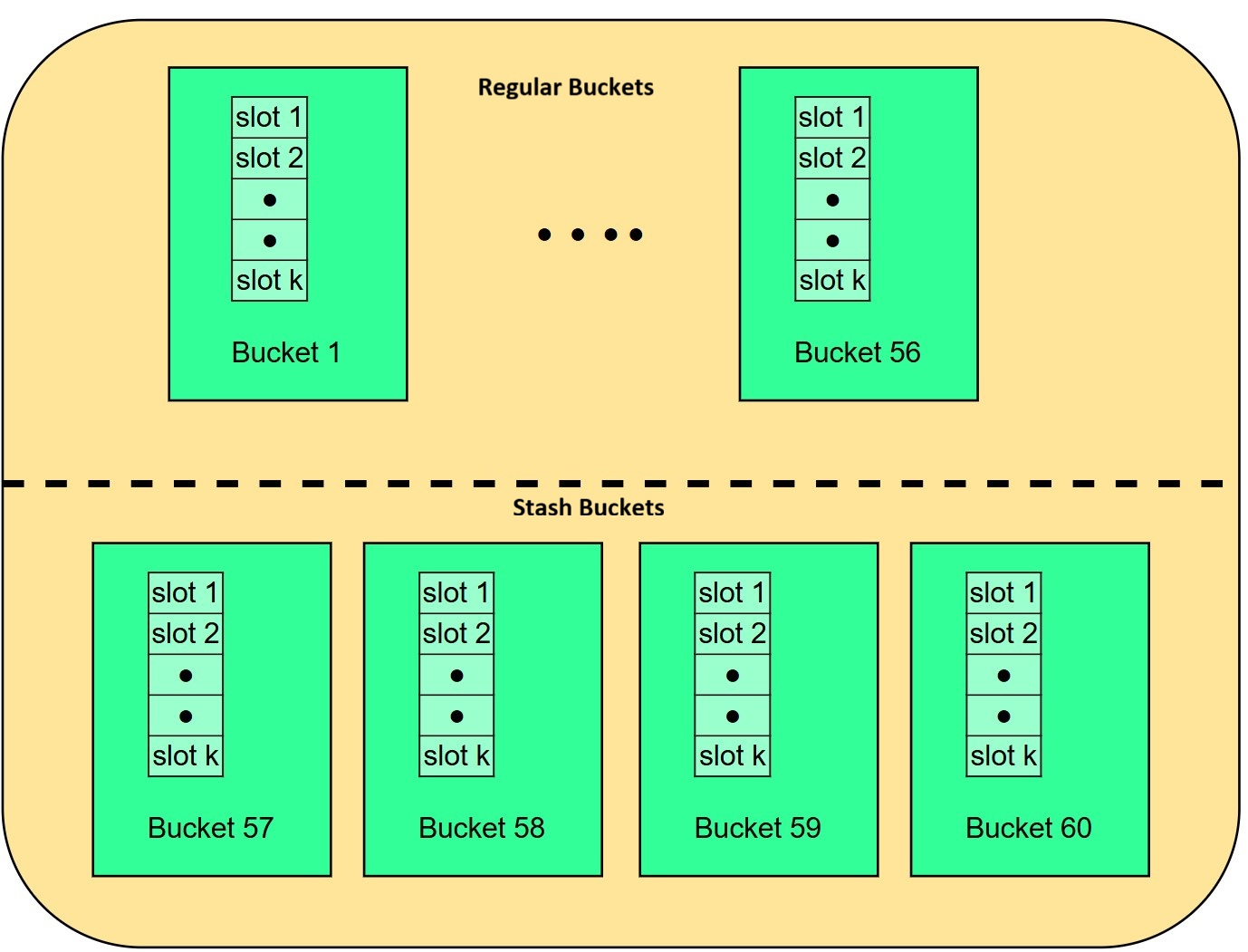
우리 구현에서 각 세그먼트에는 56개의 일반 버킷, 4개의 예비(stash) 버킷이 있고, 각 버킷에는 14개의 슬롯이 있습니다.
전체적으로 각 대시테이블 세그먼트는 840개의 레코드를 호스팅할 수 있는 용량을 갖습니다.
항목(키-값 레코드)이 세그먼트에 삽입되면 DT는 먼저 항목(키)의 해시 값을 기반으로 홈 버킷을 결정합니다.
홈 버킷은 테이블에 있는 56개의 일반 버킷 중 하나입니다.
각 버킷에는 14개의 사용 가능한 슬롯이 있으며 항목은 빈 슬롯에 있을 수 있습니다.
홈 버킷이 가득 차면 DT는 오른쪽의 일반 버킷에 삽입을 시도합니다.
그리고 해당 버킷도 가득 차면 4개의 예비 버킷 중 하나에 삽입을 시도합니다.
이것들은 일반(regular) 버킷에서 유출된 물을 모으기 위해 의도적으로 따로 보관됩니다.
삽입이 실패하면 세그먼트가 "가득 차 있습니다(full)".
즉, 홈 버킷, 이웃 버킷 및 4개의 예비 버킷이 모두 가득 찼습니다.
전체 용량에서는 세그먼트가 필요하지 않으며 다른 버킷이 아직 가득 차지 않을 수 있지만
안타깝게도 해당 항목은 이 6개의 버킷에만 들어갈 수 있으므로 세그먼트를 분할해야 합니다.
분할 이벤트의 경우 DT는 새 세그먼트를 생성하여 디렉터리에 추가하고 이전 세그먼트의 항목을 부분적으로
새 세그먼트로 이동하고 부분적으로 이전 세그먼트 내에서 재조정합니다.
분할 이벤트 중에는 두 개의 세그먼트만 터치됩니다.
이제 우리는 유사해 보이는 데이터 구조가 메모리와 CPU 측면에서 기존 해시테이블에 비해 왜 이점이 있는지 설명할 수 있습니다.
1. 메모리(Memory): 평균적으로 N개 항목을 호스팅하려면 dashtable 디렉터리에 ~N/840항목이나 8N/840 바이트가 필요합니다.
기본적으로 DT에서는 디렉토리의 오버헤드가 거의 사라진다.
1백만개 항목의 경우 기본 배열에 ~1200개의 세그먼트와 9600바이트(Segment Directory)가 필요하다고 가정해 보겠습니다.
이는 무슨 일이 있어도 견고한 8N 버킷 어레이 오버헤드가 필요한 RD(Redis Dictionary)와는 대조적입니다.
1백만개 항목의 경우 당연히 8MB가 필요합니다.
또한 대시 세그먼트는 탐색(probing)과 함께 개방형 주소 지정 충돌 방식을 사용합니다.
즉, 이는 "dictEntry"와 같은 것이 필요하지 않다는 것을 의미합니다.
"Dashtable"은 자체 메타데이터를 작게 만들기 위해 많은 트릭을 사용합니다.
우리 구현에서는 항목당 평균이 tax RD(dictEntry.next)의 64비트에 비해 20비트로 짧습니다.
또한 DT 증분 크기 조정은 더 큰 테이블을 할당하지 않고 대신 분할 이벤트당 단일 세그먼트를 추가합니다.
키/쌍 항목이 RD와 같이 두 개의 8바이트 포인터라고 가정하면 DT에는 다음이 필요합니다.
16N + (8N/840)+2.5N+O(1) = 19N 100% 활용률의 바이트입니다.
이 숫자는 최적의 16바이트에 매우 가깝습니다.
드물지만 모든 세그먼트의 크기가 두 배로 늘어난 경우, 즉 DT가 필요한 활용도의 50%에 도달한 경우 38N 항목당 바이트입니다.
실제로 각 세그먼트는 다른 세그먼트와 독립적으로 증가하므로 테이블은 항목당 22~32바이트의 원활한 메모리 사용량을 가지며, 이는 6~16바이트의 오버헤드를 발생시킵니다.
2. 속도(Speed): RD(Redis Dictionary)에는 삽입당 dictEntry 할당(allocation)과 삭제당 할당 취소(deallocation)가 필요합니다.
또한 RD는 최신 하드웨어에서는 캐시에 적합하지 않은 체인을 사용합니다.
엔지니어링 및 연구 커뮤니티에서는 기존 체인 방식이 개방형 주소 지정 방식보다 속도가 느리다는 데 동의합니다.
하지만 DT(DashTable)는 세그먼트 포인터를 가져올 때 단일 수준의 간접 참조도 거쳐야 합니다.
그러나 DT의 디렉터리 크기는 상대적으로 작습니다. 위의 예에서는 L1 캐시에서 모든 9K의 크기를 조정할 수 있습니다.
그러나 세그먼트가 결정되면 나머지 삽입은 매우 빠르며 대부분 1-3개의 메모리 캐시 라인에서 작동합니다.
마지막으로 크기 조정 중에 RD는 크기가 2N 인 버킷 배열을 할당해야 합니다.
이는 시간이 많이 걸릴 수 있습니다. 예를 들어 1억 버킷 할당을 상상해 보세요.
반면 DT에서는 새 세그먼트마다 일정한 크기를 할당해야 합니다.
DT는 더 빠르고 더 중요한 것은 점진적인 능력이 더 좋다는 것입니다.
이는 지연 시간 급증을 제거하고 위 작업의 꼬리 지연 시간을 줄입니다.
Dashtable의 모든 효율성에도 불구하고 전체 메모리 사용량을 크게 줄일 수는 없습니다.
주요 목표는 사전 관리와 관련된 낭비를 줄이는 것입니다.
즉, 메타데이터 낭비를 줄임으로써 Dragonfly 전용 속성을 테이블의 메타데이터에 삽입하여 포크리스 저장(forkless-save)과 같은
다른 지능형 알고리즘을 구현할 수 있습니다.
📦 Benchmarks
◻️ Populate single-threaded 싱글 스레드 채우기
RD(Redis Dictionary)와 DT(DashTable)를 비교하기 위해 두 데이터 저장소를 데이터로 빠르게 채우는
내부 디버깅 명령 "debug populate"를 자주 사용합니다.
"memtier_benchmark"에 비해 시간을 절약하고 더 일관된 결과를 제공합니다.
또한 네트워킹, 구문 분석 등과 같은 중간 요소 없이 각 사전이 채워지는 원시 속도도 보여줍니다.
저는 의도적으로 작은 데이터로 데이터 세트를 채워 두 데이터 구조 간에 메타데이터 오버헤드가 어떻게 다른지 보여줍니다.
내 가정용 컴퓨터인 "AMD Ryzen 5 3400G with 8 cores"의 두 엔진 모두에서 "debug populate 20,000,000"(2천만건 입력)을 실행합니다.
Redis-6 "info memory" 통계를 보면 used_memory_overhead 필드가 1.0GB.
이는 할당된 1.73GB 바이트 중에서 무려 1.0GB가 메타데이터에 사용된다는 의미입니다.
소규모 데이터 사용 사례의 경우 Redis의 메타데이터 비용은 데이터 자체보다 큽니다.
◻️ Populate multi-threaded 멀티 스레드 채우기
이제 저는 8개 코어 모두에서 Dragonfly를 실행합니다. 물론 Redis도 동일한 결과를 얻습니다.
비공유(shared-nothing) 아키텍처로 인해 Dragonfly는 자체 데이터 조각을 사용하여 스레드당 대시 테이블을 유지 관리합니다.
각 스레드는 자신이 소유한 2천만 범위의 1/8을 채우며 훨씬 더 빠르며 거의 8배 빠릅니다.
이제 각 스레드에서 더 작은 테이블을 유지하기 때문에 총 사용량이 훨씬 더 적다는 것을 알 수 있습니다.
(항상 그런 것은 아닙니다. 싱글 스레드의 경우보다 약간 더 나쁜 메모리 사용량을 얻을 수 있으며,
해시 테이블 활용도와 비교하여 어디에 있는지에 따라 다릅니다)
◻️ Forkless Save - 포크없는 저장
BGSAVE 중에 Redis와 Dragonfly가 사용하는 메모리 양을 비교합니다.
Dragonfly의 BGSAVE 및 SAVE는 특정 시점 스냅샷(point-in-time snapshot) 보장을 유지하는 완전 비동기
알고리즘을 사용하여 구현되므로 동일한 절차입니다.
이 테스트는 3단계로 구성됩니다.
1. 두 서버 모두에서 아래 명령을 실행하여 ~5GB의 데이터를 빠르게 채웁니다.
"debug populate 5000000 key 1024"
2. 지속적인 업데이트 트래픽을 전송하기 위해 위 명령을 실행합니다.
[memtier_benchmark --ratio 1:0 -n 600000 --threads=2 -c 20 --distinct-client-seed --key-prefix="key:" --hide-histogram --key-maximum=5000000 -d 1024]
이 트래픽은 두 서버의 메모리 사용량에 크게 영향을 미치지 않습니다.
3. 마지막으로 두 서버 모두에서 "bgsave" 실행하면서 메모리를 측정합니다.
BGSAVE 중에 Redis의 정확한 메모리 사용량을 측정하는 것은 기술적으로 매우 어렵습니다.
Redis는 상위 메모리를 부분적으로 공유하는 하위 프로세스를 생성하기 때문입니다.
우리는 메모리를 측정하는 도구로 cgroupsv2 선택했습니다.
우리는 각 서버를 별도의 cgroup에 넣고 memory.current 각 cgroup에 대한 속성을 샘플링했습니다.
분기된 Redis 프로세스는 상위 프로세스의 cgroup을 상속하므로 총 메모리 사용량을 정확하게 추정할 수 있습니다.
Dragonfly에는 이것이 필요하지 않았지만 일관성을 위해 동일한 접근 방식을 적용했습니다.

그래프에서 볼 수 있듯이 Redis는 BGSAVE가 시작되기 전에도 50% 더 많은 메모리를 사용합니다.
두 번째 14 초경에 BGSAVE가 두 서버 모두에서 시작됩니다.
시각적으로 Dragonfly 그래프에서는 이 이벤트를 볼 수 없지만 Redis 그래프에서는 매우 잘 보입니다.
Dragonfly가 스냅샷을 완료하는 데는 몇 초밖에 걸리지 않았으며(다시 말하지만 볼 수 없음)
20초경에 Dragonfly는 이미 BGSAVE를 완료했습니다.
Redis가 스냅샷을 완료하는 39초 지점에서 눈에 띄는 절벽을 볼 수 있으며, 최대 메모리 사용량은 거의 3배에 달합니다.
◻️ Expiry of items during writes 쓰기 중 항목 만료
효율적인 만료는 많은 시나리오에서 매우 중요합니다. 예를 들어 "Pelikan 논문(2021)"을 참조하세요.
Twitter 팀은 더 나은 만료 방법을 사용하면 메모리 사용량을 60%까지 줄일 수 있다고 말합니다.
게시물의 작성자는 아래 표에 만료 방법의 장단점을 보여줍니다.
Pelikan 논문(2021)
Source Code(github)

그들은 만료된 항목을 적시에 삭제하려면 선행적(proactive) 만료가 매우 중요하다고 주장합니다.
Dragonfly는 자체 지능형 가비지 수집 절차를 사용합니다.
DashTable의 구획화된 구조를 활용함으로써 실제로 낮은 CPU 오버헤드로 매우 효율적인 수동 만료 알고리즘을 사용할 수 있습니다.
우리의 수동적 절차는 백그라운드에서 테이블을 미리 점진적으로 스캔하는 것으로 보완됩니다.
절차는 다음과 같습니다.
삽입 중에 세그먼트가 가득 차서 분할해야 할 경우 대시 테이블이 커집니다.
이는 가비지 수집을 수행하기에 편리한 지점이지만 해당 세그먼트에만 해당됩니다.
만료된 항목이 있는지 버킷을 검색합니다.
그 중 일부를 삭제하면 테이블이 완전히 커지는 것을 피할 수 있습니다!
잠재적인 분할 전에 세그먼트를 스캔하는 비용은 더 이상 분할 자체가 아니므로 O(1) 같이 추정할 수 있습니다.
Dragonfly와 Redis의 만료 효율성을 비교하기 위해 실험에 memtier_benchmark 사용했습니다.
다음 명령을 로컬로 실행합니다.
memtier_benchmark --ratio 1:0 -n 600000 --threads=2 -c 20 --distinct-client-seed \
--key-prefix="key:" --hide-histogram --expiry-range=30-30 --key-maximum=100000000 -d 256
Dragonfly의 메타데이터 저장으로 인한 영향을 줄이기 위해 더 큰 값(256바이트)을 로드합니다.
Redis는 30% 더 적은 qps를 유지할 수 있습니다.
이는 Dragonfly와 Redis에 대한 최적의 작업 세트가 다르다는 것을 의미합니다.
전자는 20s*131k 특정 시점에 최소한 항목을 호스팅해야 하고 후자는 20s*100K 항목만 유지하면 됩니다.
따라서 30% 더 큰 작업 세트를 위해 Dragonfly는 최대 25% 메모리가 더 적게 필요했습니다.
* 이 테스트에서는 Redis에 비해 Dragonfly의 성능 이점을 무시하십시오. 이는 의미가 없습니다.
내 컴퓨터에서 로컬로 실행했는데 실제 처리량 벤치마크를 나타내지 않습니다.
