
df_0030
Dash: Scalable Hashing on Persistent Memory
대시(Dash): 영구 메모리의 확장 가능한 해싱
이 문서는 논문 "Dash: Scalable Hashing on Persistent Memory" 번역입니다.
그리고 아래에 추가 설명과 컴파일(make), 실행/테스트 결과가 있습니다.
📜
Dash: Scalable Hashing on Persistent Memory - 논문 원본(영어)
논문 목차
- 🟢 ABSTRACT - 요약
- 🟢 1. INTRODUCTION
- 1.1 Hashing on PM: Not What You Assumed! - PM 해싱: 예상했던 것과는 다릅니다!
- 1.2 Dash - 대시
- 1.3 Contributions and Paper Organization - 기여 및 논문 구성
- 🟢 2. BACKGROUND - 배경 지식
- 2.1 Intel Optane DC Persistent Memory - 인텔 Optane DC 영구 메모리
- 2.2 Dynamic Hashing - 동적 해싱
- 2.3 Dynamic Hashing on PM
- 🟢 3. DESIGN PRINCIPLES - 설계 원칙
- 🟢 4. Dash FOR EXTENDIBLE HASHING - 확장 가능한 해싱을 위한 대시(Dash)
- 4.1 Overview - 개요
- 4.2 Fingerprinting - 지문
- 4.3 Bucket Load Balancing - 버킷 로드 밸런싱
- 4.4 Optimistic Concurrency - 낙관적 동시성
- 4.5 Support for Variable-Length Keys - 가변 길이 키 지원
- 4.6 Record Operations - 레코드 작업
- 4.7 Structural Modification Operations - 구조 수정 작업
- 4.8 Instant Recovery - 즉시 복구
- 🟢 5. Dash FOR LINEAR HASHING - 선형 해싱을 위한 Dash(대시)
- 5.1 Overview - 개요
- 5.2 Hybrid Expansion - 하이브리드 확장
- 5.3 Concurrency - 동시성
- 🟢 6. EVALUATION - 평가
- 6.1 Implementation - 구현
- 6.2 Experimental Setup - 실험 설정
- 6.3 Single-thread Performance - 단일 스레드 성능
- 6.4 Scalability - 확장성
- 6.5 Fingerprinting and Overflow Metadata - "핑거프린팅"과 "오버플로 메타데이터"
- 6.6 Load Factor - 부하율
- 6.7 Impact of Concurrency Control - 동시성 제어의 영향
- 6.8 Recovery - 복구
- 6.9 Impact of PM Software Infrastructure - PM 소프트웨어 인프라의 영향
- 🟢 7. RELATED WORK - 관련 논문 소개
- 🟢 8. CONCLUSION - 결론
🟢 ABSTRACT - 요약
바이트 주소 지정(Byte-addressable)이 가능한 영구 메모리(Persistent Memory:PM)의 해시 테이블은 낮은 대기 시간(low latency), 저렴한 지속성(cheap persistence) 및 즉시 복구 가능성(instant recovery)을 제공합니다. 최근 Intel Optane(옵테인) DC(Data Center) 영구 메모리 모듈(Persistent Memory Modules:PMM)의 등장으로 이러한 추세가 더욱 가속화되었습니다. 많은 새로운 해시 테이블 설계가 제안되었지만, 대부분은 에뮬레이션을 기반으로 했으며 실제 PM에서는 최적이 아닌 성능을 발휘했습니다. 또한 이는 특히 우수한 확장성(good scalability), 높은 적재율(high load factor) 및 즉시 복구와 같은 많은 중요한 특성을 비켜나가는(side-step) 단편적이고(piece-wise) 부분적인 솔루션이었습니다. 앞서 언급한 모든 속성을 갖춘 실제 PM 하드웨어에 동적이고 확장 가능한 해시 테이블을 구축하는 전체적인 접근 방식인 Dash(대시)를 소개합니다. Dash를 기반으로 우리는 널리 사용되는 두 가지 동적 해싱 방식(확장형(extendible) 해싱 및 선형(linear) 해싱)을 채택했습니다. Intel Optane DCPMM을 탑재한 24코어 시스템에서 최신 기술에 비해 Dash 지원 해시 테이블이 최대 90% 이상의 적재율과 최대 ~3.9배 더 높은 성능을 달성할 수 있음을 보여줍니다. 즉시 복구 시간은 데이터 크기에 관계없이 57ms입니다.
🟢 1. INTRODUCTION - 도입(소개)
런타임 시 필요에 따라 확장(grow) 및 축소(shrink)할 수 있는 동적 해시 테이블은 데이터베이스 시스템 및
키-값 저장소와 같은 많은 데이터 집약적(data-intensive) 시스템의 기본 구성 요소입니다.
3D XPoint 및 memristor와 같은 영구 메모리(PM)는 메모리 버스에서 바이트 주소 지정 가능성(byte-addressability),
지속성(persistence), 고용량(high capacity), 저비용(low cost) 및 고성능(high performance)을 모두 약속합니다.
이러한 기능으로 인해 영구 메모리(PM)은 고성능 및 즉시 복구 기능을 통해 영구 메모리(PM)에서 직접 지속되고
작동하는 동적 해시 테이블을 구축하는 데 매우 매력적입니다.
Intel Optane DC 영구 메모리 모듈(DCPMM)의 최근 릴리스는 이러한 비전을 현실에 더 가깝게 만듭니다.
PM은 여러 가지 고유한 특성(예: 비대칭 읽기/쓰기 속도 및 더 높은 대기 시간)을 나타내기 때문에
이전 디스크 또는 DRAM 기반 접근 방식을 맹목적으로(blindly) 적용하면 모든 이점을 얻을 수 없으므로
기존 설계에서 벗어나야 합니다.
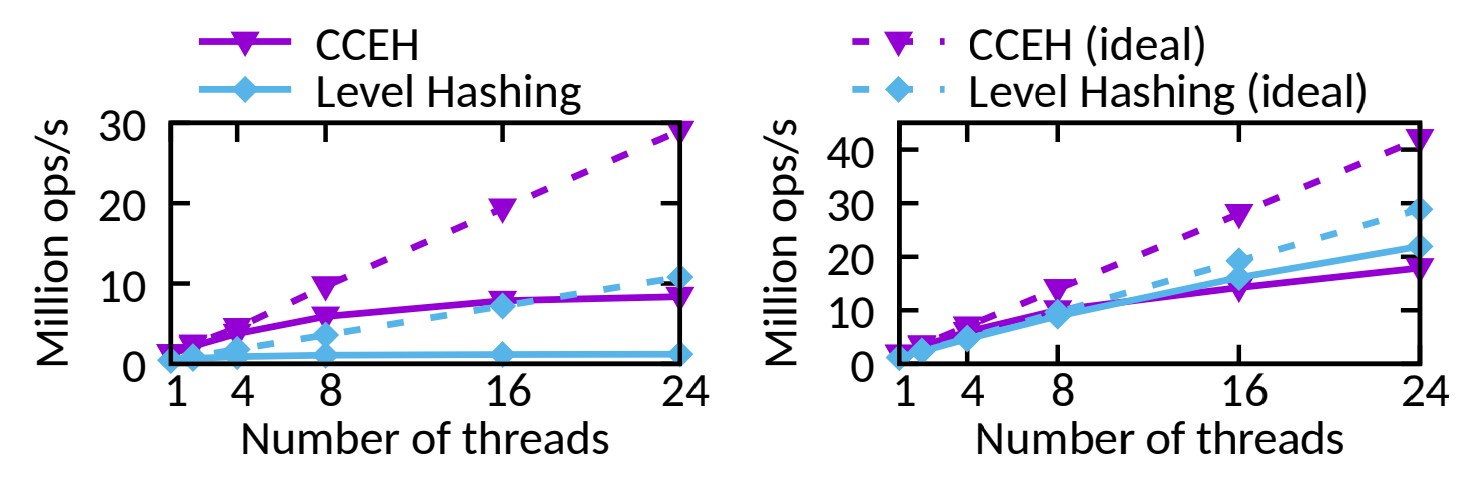
처리량입니다. 둘 다 예상된 확장성과 일치하지 않습니다.
📦 1.1 Hashing on PM: - PM 해싱: 예상했던 것과는 다릅니다!
⬜️ 실제 PM(Persistent Memory)이 제공되기 전에 DRAM 에뮬레이션을 기반으로 PM을 위해 특별히 설계된
새로운 종류의 해시 테이블이 있었습니다.
주요 초점은 확장 가능한 성능을 위해 캐시라인(cacheline) 플러시 및 PM 쓰기를 줄이는 것입니다.
그러나 실제 Optane DCPMM에 배포하면 (1) 확장성이 여전히 주요 문제이고 (2) 바람직한 속성이 종종 상쇄(traded off)되는
경우가 있습니다.
⬜️ 그림 1은 균일한 키 분배 하에서 워크로드를 실행하는 Optane DCPMM을 갖춘 24코어 서버에서
삽입(왼쪽) 및 검색(오른쪽) 작업 시 2개의 최첨단 PM 해시 테이블의 처리량을 보여줍니다(자세한 내용은 섹션 6 참조).
코어 수가 증가함에 따라 삽입에 맞게 방식이 확장되지 않으며 읽기 전용 검색 작업도 마찬가지입니다.
최근 연구를 통해 우리는 DRAM보다 약 3~14배 낮은 Optane DCPMM의 제한된 대역폭이 주요 원인임을 발견했습니다.
가능한 최대 대역폭을 제공하기 위해 서버가 완전히 채워지더라도 과도한 PM 액세스는 여전히 시스템을 쉽게 포화시키고
시스템 확장을 방해할 수 있습니다.
우리는 이전에 충분히 주의를 기울이지 않았던 과도한 PM 액세스의 두 가지 주요 원인을 설명하고,
이전 작업에서 중요하지만 누락된 기능에 대해 논의합니다.
⬜️ Excessive PM Reads. - 과도한 PM 읽기.
이전 작업은 PM에 대한 쓰기를 줄이는 데 중점을 두었지만 PM 읽기를 줄이는 것도 필수적이라는 점을 알고 있습니다.
그러나 많은 기존 솔루션은 더 많은 PM 읽기를 발생시켜 PM 쓰기를 줄입니다.
장치 수준 동작(PM 읽기가 쓰기보다 빠름)과 달리 종단 간(end-to-end) 쓰기 대기 시간
(즉, 메모리 컨트롤러의 CPU 캐시 및 쓰기 버퍼를 포함한 전체 데이터 경로)은 읽기보다 낮은 경우가 많습니다.
그 이유는 PM 쓰기가 쓰기 버퍼를 활용할 수 있는 반면 PM 읽기는 해시 테이블의 고유한 무작위 액세스 패턴으로 인해
대부분 PM 미디어에 닿기 때문입니다.
특히, 레코드 탐색의 존재 확인은 PM 읽기의 큰 부분을 차지합니다.
키가 존재하는지 확인하려면 하나 또는 여러 개의 버킷(예: 선형 탐색(linear probing) 사용)을 검색해야 하며,
키를 비교할 때 많은 캐시 누락과 PM 읽기가 발생합니다.
⬜️ Heavyweight Concurrency Control. - 무거운 동시성 제어.
대부분의 이전 작업은 동시성 제어의 영향을 회피했습니다.
버킷 수준 잠금은 널리 사용되었지만, 읽기 잠금을 획득/해제하기 위해 추가 PM 쓰기가 발생하여
대역폭 소비가 한계에 가까워졌습니다.
잠금 없는(Lock-free) 설계는 읽기 전용 탐색 작업에 대한 PM 쓰기를 방지할 수 있지만 올바르게 수행하기가 매우 어렵습니다.
안전한 지속성을 위해 PM에서는 더욱 그렇습니다.
레코드 탐색이나 동시성 제어는 일반적으로 잘 설계된 해시 테이블이 DRAM에서 확장되는 것을 방해하지 않습니다.
그러나 PM에서는 PM의 제한된 대역폭을 쉽게 소진할 수 있습니다.
이러한 문제에는 탐색 중에 불필요한 PM 읽기를 줄일 수 있는 새로운 설계와 PM 쓰기를 더욱 줄이는 경량 동시성 제어가 필요합니다.
⬜️ Missing Functionality. - 기능 누락.
이전 설계에서 볼 수 있듯이, 필요한 기능이 성능을 위해 희생되는(traded off) 경우가 많습니다
(실제 PM에서는 확장성이 여전히 문제이지만).
(1) 인덱스는 메모리 용량의 50% 이상을 차지할 수 있으므로 적재율(저장된 레코드 대 해시 테이블 용량)를 개선하는 것이 중요합니다.
그러나 더 작은 디렉터리(더 적은 캐시 누락) 대신 더 큰 세그먼트를 사용하여 버킷을 구성하면
높은 적재율이 희생되는 경우가 많습니다.
나중에 설명하겠지만 이로 인해 더 많은 조기 분할이 발생하고 더 많은 PM 액세스가 발생하여 성능에 영향을 줄 수 있습니다.
(2) 가변 길이 키(Variable-length keys)는 실제로 널리 사용되지만 이전 접근 방식에서는 이를 효율적으로 지원하는 방법에 대해 거의 논의되지 않았습니다.
(3) 즉시 복구(Instant recovery)는 PM이 제공할 수 있는 고유하고 바람직한 기능이지만 데이터 크기에 따라 크기가 확장되는
메타데이터의 선형 스캔이 필요한 이전 작업에서는 종종 생략됩니다.
(4) 또한 이전 설계에서는 제안된 솔루션의 확장성과 현실 채택에 영향을 미치는 PM 프로그래밍 문제(예: PM 할당)를
회피하는 경우가 많습니다.
📦 1.2 Dash - 대시
우리는 바람직한(desirable) 속성(properties)을 포기하지 않고 실제 PM에 대한 동적(dynamic)이고
확장 가능(scalable)한 해싱에 대한 전체적인 접근 방식인 Dash(대시)를 소개합니다.
Dash는 이 목표를 달성하기 위해 신중하게 설계된 새로운 기술과 기존 기술을 조합하여 사용합니다.
⬜️ ① fingerprinting - 지문
우리는 레코드 탐색(probing) 중에 불필요한 PM 읽기를 피하기 위해 PM 트리 구조에 사용된 지문(fingerprinting)[43]을 채택했습니다.
아이디어는 키의 지문(1바이트 해시)을 생성하고 이를 압축하여 키의 존재 가능성을 요약하는 것입니다.
이를 통해 스레드는 실제 키보다 훨씬 작은 지문을 스캔하여 키가 존재할 수 있는지 여부를 알 수 있습니다.
📋[43] I. Oukid, J. Lasperas, A. Nica, T. Willhalm, and W. Lehner.
FPTree: A hybrid SCM-DRAM persistent and concurrent B-tree for storage class memory.
스토리지 클래스 메모리를 위한 하이브리드 SCM-DRAM 영구 및 동시 B-트리
In Proceedings of the 2016 International Conference on Management of Data, SIGMOD, pages 371–386, 2016.
⬜️ ② optimistic concurrency - 낙관적 동시성
Dash는 전통적인(traditional) 버킷 수준 잠금 대신, (비싼) 공유 잠금이 아닌, 확인을 통해 충돌을 감지하는 낙관적(optimistic)이고
가벼운(lightweight) 방식을 사용합니다.
이를 통해 Dash는 검색 작업에 대한 PM 쓰기를 피할 수 있습니다.
지문과 낙관적인 동시성을 통해 Dash는 불필요한 읽기와 쓰기를 모두 피하여 PM 대역폭(bandwidth)을 절약하고
Dash의 확장성을 향상시킵니다.
⬜️ ③ Dash retains desirable properties. - Dash는 바람직한 속성을 유지합니다.
공간 활용도를 높여 세그먼트 분할을 연기하는(postpone) 새로운 로드 밸런싱 전략을 제안합니다.
즉시 복구(instant recovery)를 지원하기 위해 복구 시 수행되는 작업량을 작게 제한하고(1바이트 카운터 읽기 및 쓰기 가능)
복구 작업을 런타임으로 분할(상각:amortize)합니다. (amortize: 상각 償却(갚다.물러나다) 보상하여 갚아 줌)
임시적인(ad hoc) 방식으로 PM 프로그래밍 문제를 처리하는 이전 작업과 비교하면,
Dash는 충돌 일관성을 체계적으로(systematically) 처리하기 위해 PM 프로그래밍 모델
(가장 인기 있는 PM 라이브러리 중 하나인 PMDK [20])을 사용해서
PM을 할당하고 즉시 복구를 달성합니다.
📋[20] Intel. PMDK: Persistent Memory Development Kit. 2018. http://pmem.io/pmdk/libpmem/
📦 1.3 Contributions and Paper Organization - 기여 및 논문 구성
우리는 네 가지 기여를 했습니다.
① 첫째, 기존(existing) PM 해싱 접근 방식과 바람직한(desirable) PM 해싱 접근 방식 간의 불일치를 식별하고 새로운 과제를 강조합니다.
② 둘째, 실제(real) PM에 확장 가능한 해시 테이블을 구축하기 위한 전체적인(holistic) 접근 방식인 Dash(대시)를 제안합니다.
Dash는 다양한 해시 테이블 디자인에 적용할 수 있는 유용하고 일반적인 빌딩 블록 세트로 구성됩니다.
③ 셋째, 우리는 두 가지 고전적이고 널리 사용되는 동적 해싱 방식인 Dash 지원(Dash-enabled)
확장형 해싱(extendible hashing:EH)과 선형 해싱(linear hashing:LH)을 제시합니다.
④ 마지막으로, 우리는 중요한 설계 결정을 정확히(pinpoint) 찾아내고 검증하기 위해 Dash와 기존 PM 해시 테이블에 대한
포괄적인(comprehensive) 경험적(empirical) 평가(evaluation)를 제공합니다.
구현된 소스(open-source)는 여기에 있습니다. https://github.com/baotonglu/dash
이 논문에서는
섹션 2에서 필요한 배경 지식을 제공합니다.
섹션 3~5에서는 디자인 원칙과 Dash 지원(Dash-enabled) 확장형 해싱 및 선형 해싱을 제시합니다.
섹션 6에서는 Dash를 평가합니다.
섹션 7에서 참고 논문을 논의하고
섹션 8에서 결론을 내립니다.
🟢 2. BACKGROUND - 배경 지식
먼저 PM(Optane DCPMM) 및 동적 해싱에 대한 필요한 배경 지식을 제공한 다음, 이전 PM 해시 테이블의 문제를 논의합니다.
📦 2.1 Intel Optane DC Persistent Memory - 인텔 Optane DC(Data Center) 영구 메모리
⬜️ Hardware - 하드웨어
우리는 Optane(옵테인) DCPMM(DIMM 폼 팩터)을 목표로 합니다.
바이트 주소 지정 기능과 지속성 외에도 DCPMM은 DRAM보다 저렴한 가격으로 고용량(DIMM당 128/256/512GB)을 제공합니다.
메모리 모드 및 AppDirect(앱다이렉트) 모드를 지원합니다.
메모리 모드는 용량은 크지만 속도가 느린 휘발성 메모리를 제공합니다.
DRAM은 하드웨어 제어 캐싱 정책을 통해 PM의 높은 대기 시간을 숨기기 위한 캐시로 사용됩니다.
AppDirect 모드를 사용하면 소프트웨어는 암시적 캐싱 없이 PM의 지속성을 통해 명시적으로 DRAM 및 PM에 액세스할 수 있습니다.
애플리케이션은 DRAM과 PM을 신중하게(judicious) 사용해야 합니다.
다른 작업과 마찬가지로 더 많은 유연성과 지속성을 보장하는 AppDirect 모드를 활용합니다.
⬜️ System Architecture - 시스템 구조
현재 세대의 DCPMM이 제대로 작동하려면 시스템에 DRAM이 장착되어 있어야 합니다.
또한 여러 수준의 휘발성 CPU 캐시 뒤에 있는 PM 및 DRAM을 사용하여 이러한 설정을 가정합니다.
캐시라인 플러시(cacheline flush) 명령(CLFLUSH, CLFLUSHOPT 또는 CLWB)이 실행되거나 캐시라인 플러시를 암시적으로 발생시키는
다른 이벤트가 발생할 때까지 데이터는 PM에서 지속된다는 보장이 없습니다.
PM에 대한 쓰기도 재정렬(reordered)될 수 있으므로 바람직하지 않은 재정렬을 방지하기 위해 펜스(fences)가 필요합니다.
애플리케이션(우리의 경우 해시 테이블)은 정확성을 보장하기 위해 명시적으로 펜스와 캐시라인 플러시를 실행해야 합니다.
CLFLUSH 및 CLFLUSHOPT는 플러시되는 캐시라인을 제거하지만 CLWB는 그렇지 않습니다(따라서 더 나은 성능을 제공할 수 있음).
데이터의 캐시라인이 플러시된 후 쓰기 버퍼와 정전 시 지속성을 보장하는 쓰기 보류 큐를 포함하는
비동기 DRAM 새로 고침(Asynchronous DRAM Refresh:ADR) 도메인에 도달합니다.
데이터가 ADR 도메인에 있으면 지속되는 것으로 간주됩니다.
DCPMM은 8바이트 원자 쓰기를 지원하지만 내부적으로는 256바이트 블록을 사용합니다.
그러나 소프트웨어는 향후 세대에서 변경될 수 있는 하드웨어의 내부 매개변수이므로 이에 의존(하드코딩)해서는 안 됩니다.
⬜️ Performance Characteristics - 성능 특성
이전의 많은 연구에서 알 수 있듯이, 장치 수준(device level)에서 PM은 비대칭(asymmetric) 읽기 및 쓰기 대기 시간을
나타내며 읽기에 비해 쓰기 속도가 느립니다.
읽기 지연 시간은 ~300ns로 DRAM보다 ~4배 더 깁니다.
그러나 최근 연구에 따르면 Optane DCPMM에서 소프트웨어에 표시되는 읽기 대기 시간은 쓰기 대기 시간보다 더 높은 경우가 많습니다(더 느리다).
이는 데이터가 DCPMM 미디어에 도달할 때가 아니라 메모리 컨트롤러의 비동기 DRAM 새로 고침(Asynchronous DRAM Refresh:ADR) 도메인에
도달한 후에 쓰기(저장 명령)가 커밋된다는 사실에 기인합니다.
반대로 읽기 작업은 액세스되는 데이터가 캐시에 상주하지 않는 한 실제 미디어에 접근해야 하는 경우가 많습니다
(해시 테이블과 같이 고유한 무작위성을 갖는 데이터 구조에서는 특히 드뭅니다).
또한 테스트 결과 DCPMM의 대역폭은 워크로드의 여러 요소에 따라 달라지는 것으로 나타났습니다.
일반적으로 DRAM에 비해 ~3배/∼8배 더 느린 순차(sequential)/무작위(random) 읽기 대역폭을 나타냅니다.
순차/무작위 쓰기는 ∼11배/∼14배 더 느립니다.
특히, 소규모 무작위 저장소의 성능은 심각하게 제한되고 확장이 불가능합니다. 이는 해시 테이블의 고유한 액세스 패턴입니다.
이러한 특성은 PM 성능에 대한 이전 추정치와 뚜렷한 대조를 나타내며 원래 보고된 것보다 DCPMM에 대한 많은 이전 설계의 성능이 크게 저하됩니다.
따라서 성능 향상을 위해서는 PM 읽기 및 쓰기를 모두 줄이는 것이 중요합니다.
원시(raw) DCPMM 장치 성능에 대한 자세한 내용은 다른 곳에서 찾을 수 있습니다[22].
우리는 PM에서 해시 테이블의 종단 간(end-to-end) 성능에 중점을 둡니다.
📋[22] DCPMM: J. Izraelevitz, J. Yang, L. Zhang, J. Kim, X. Liu, A. Memaripour, Y. J. Soh, Z. Wang, Y. Xu, S. R. Dulloor, J. Zhao, and S. Swanson.
Basic performance measurements of the Intel Optane DC Persistent Memory Module, 2019.
Intel Optane DC 영구 메모리 모듈의 기본 성능 측정
📦 2.2 Dynamic Hashing - 동적 해싱
이제 확장 가능한 해싱(extendible hashing) 및 선형 해싱(linear hashing)에 대한 개요를 제공합니다.
우리는 PM 적응 해시 테이블의 기반이 되는 메모리 친화적인(memory-friendly) 버전에 중점을 둡니다.
대시는 향후 작업으로 미루는 다른 접근 방식에도 적용될 수 있습니다.
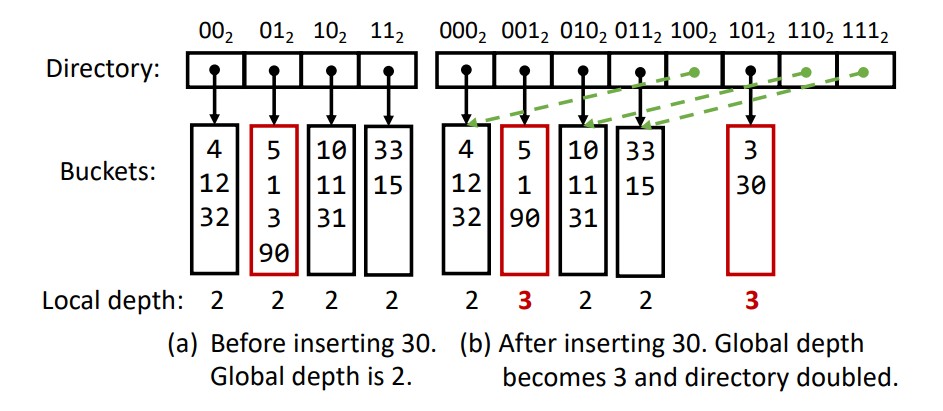
(a) 해시 테이블이 가득 찼습니다.
(b) 분할되지 않은 버킷의 로컬 깊이는 2입니다.
로컬 깊이가 글로벌 깊이보다 작은 버킷을 분할해도 디렉터리가 두 배가 되지 않습니다.
⬜️ Extendible Hashing - 확장 가능한 해싱
확장 가능한 해싱의 핵심은 버킷을 색인화하기(index) 위해 디렉토리를 사용하여 버킷이 런타임에 동적으로 추가 및 제거될 수 있다는 것입니다.
버킷이 가득 차면 키가 재배포된 두 개의 새 버킷으로 분할됩니다.
새 버킷에 대한 포인터를 저장할 공간이 충분하지 않으면 디렉터리가 확장(두 배)될 수 있습니다.
그림 2(a)는 4개의 버킷이 있는 예를 보여주며, 각 버킷은 디렉토리 항목으로 지정됩니다.
버킷은 최대 4개의 레코드(키-값 쌍)를 저장할 수 있습니다.
그림에서 디렉터리 항목의 인덱스는 이진수로 표시됩니다.
해시 값의 두 최하위 비트(least significant bits:LSBs)는 버킷을 선택하는 데 사용됩니다.
여기서 사용되는 접미사(suffix) 비트 수를 전역 깊이(the global depth)라고 부릅니다.
해시 테이블은 최대 2개의 전역 깊이 디렉터리 항목(버킷)을 가질 수 있습니다.
검색 작업은 해당 디렉터리 항목의 포인터를 따라 버킷을 탐색합니다.
각 버킷에는 지역 깊이(local depth)도 있습니다. 그림 2(a)에서 각 버킷의 지역 깊이는 전역 깊이와 동일한 2입니다.
버킷 01(2)에 해시된 키 30을 삽입하려고 한다고 가정해 보겠습니다.
이 버킷은 가득 차서 새 키를 수용하기 위해 분할해야 합니다.
버킷을 분할하려면 더 많은 디렉터리 항목이 필요합니다.
확장 가능한 해싱에서는 디렉터리가 항상 현재 크기의 두 배로 늘어납니다.
결과는 그림 2(b)에 나와 있습니다.
여기서 그림 2(a)의 버킷 01는 두 개의 새 버킷(001 및 101)으로 분할되어 하나는 원래 디렉터리 항목을 차지하고
다른 하나는 새로 추가된 디렉터리 절반의 두 번째 항목을 차지합니다.
다른 새 항목은 여전히 해당 원래 버킷을 가리킵니다.
검색 작업에서는 3비트를 사용하여 디렉터리 항목 인덱스를 결정합니다(이제 전역 깊이는 3입니다).
(1) 키를 모든 버킷에 균등하게 분배하는 적절한 해시 함수를 선택하는 것은 중요하지만 우리 작업에서 직교하는 문제입니다.
• orthogonal problem: 우리 연구와 직접적인 관련은 없지만, 중요한 문제라는 의미를 나타냅니다.
• 중요한 문제: 하지만 두 문제는 서로 영향을 미칠 수 있습니다.
예를 들어, 해시 함수를 잘 선택하지 않으면 해시 테이블 성능이 저하될 수 있으며, 이는 우리 연구 결과에 영향을 미칠 수 있습니다.
최하위 비트(least significant bit:LSB): 이진수(binary number)에서 가장 낮은 자리의 비트를 의미합니다.
LSB는 이진수의 가장 오른쪽 끝에 위치하며, 그 값은 숫자의 크기에 가장 적게 기여합니다.
예를 들어, 이진수 1010에서 LSB는 0입니다.
⬜️ 버킷이 분할된 후에는 지역 깊이(local depth)를 1씩 늘리고 새 버킷의 지역 깊이를 동일하게(이 예에서는 3) 업데이트합니다.
분할되지 않은 다른 버킷의 지역 깊이는 2로 유지됩니다.
이를 통해 디렉토리 배가(doubling)가 필요한지 여부를 결정할 수 있습니다.
지역 깊이가 전역 깊이(global depth)와 동일한 버킷이 분할되는 경우(예: 버킷 001 또는 101) 새 버킷을 수용하기 위해 디렉터리를 두 배로 늘려야 합니다.
그렇지 않은 경우(지역 깊이 < 전역 깊이) 디렉터리에는 새 버킷을 수용하는 데 사용할 수 있는 해당 버킷을 가리키는 2(전역 깊이 - 지역 깊이)
디렉터리 항목이 있어야 합니다.
예를 들어, 버킷 000를 분할해야 하는 경우 디렉터리 항목 100(버킷 000를 가리킴)가 새 버킷을 가리키도록 업데이트될 수 있습니다.
⬜️ Linear Hashing - 선형 해싱
인메모리 선형 해싱(linear hashing)은 개별 버킷을 가리키는 항목이 있는 디렉터리를 사용하여 버킷을 구성하는 것과 유사한 접근 방식을 취합니다.
확장 가능한(extendible) 해싱과의 주요 차이점은 선형 해싱에서는 분할(split)할 버킷이 "선형(linearly)"으로 선택된다는 것입니다.
즉, 다음에 분할될 버킷에 대한 포인터(페이지 ID 또는 주소)를 유지하고 각 라운드(round)에서 해당 버킷만 분할되며,
현재 버킷의 분할이 완료되면 포인터를 다음 버킷으로 이동시킵니다.
따라서 분할되는 버킷은 삽입 결과로 가득 찬 버킷과 반드시 동일할 필요는 없으며 결국 오버플로된 버킷은 분할되어 해당 키가 재분배됩니다.
버킷이 가득 차고 삽입이 요청되면 더 많은 오버플로 버킷이 생성되어 원래의 전체 버킷과 함께 연결됩니다.
올바른 주소 지정 및 조회를 위해 선형 해싱은 해시 함수 그룹 h1...hn을 사용합니다. 여기서 hn은 h(n−1) 범위의 두 배를 포함합니다.
이미 분할된 버킷의 경우 hn을 사용하여 새 해시 테이블 용량 범위의 버킷을 처리할 수 있으며,
분할되지 않은 다른 버킷의 경우 h(n−1)을 사용하여 원하는 버킷을 찾습니다.
모든 버킷이 분할된 후(분할 라운드가 완료됨) 해시 테이블의 용량은 두 배가 됩니다.
다음 분할 버킷(the next-to-be-split bucket)에 대한 포인터는 다음 분할 라운드의 첫 번째 버킷으로 재설정됩니다.
분할을 트리거할 시기를 결정하는 것은 선형 해싱에서 중요한 문제입니다.
일반적인 접근 방식은 적재율를 제한하여 모니터링하고 유지하는 것입니다.
적절한 분할 전략의 선택은 워크로드(workloads)에 따라 다를 수 있으며 Dash의 설계와 직교(orthogonal)합니다.
📦 2.3 Dynamic Hashing on PM - PM에서 동적 해싱
이제 동적 해싱이 PM에서 작동하도록 조정되는 방법에 대해 논의합니다.
우리는 확장 가능한 해싱에 중점을 두고 최근 대표적인 디자인인 CCEH [38]부터 시작합니다. 섹션 5에서는 PM의 선형 해싱을 다룹니다.
PM 액세스를 줄이기 위해 CCEH는 인메모리 선형 해싱과 유사하게 버킷을 세그먼트로 그룹화합니다.
그런 다음 각 디렉터리 항목은 해시 값의 추가 비트로 인덱싱된 고정된 수의 버킷으로 구성된 세그먼트를 가리킵니다.
여러 버킷을 더 큰 세그먼트로 결합하면 세그먼트를 처리하는 데 더 적은 비트가 필요하므로 디렉토리가 상당히 작아질 수 있으며
CPU에 의해 완전히 캐시될 가능성이 높아져 PM에 대한 액세스를 줄이는 데 도움이 됩니다.
이제 분할은 (버킷 대신) 세그먼트 수준에서 발생합니다.
세그먼트의 다른 버킷에 아직 사용 가능한 슬롯이 있더라도 세그먼트의 버킷이 가득 차면 세그먼트가 분할됩니다.
이로 인해 적재율이 낮아지고 PM 액세스가 더 많아집니다.
이러한 조기(pre-mature) 분할을 줄이기 위해 선형 탐색을 사용하여 레코드를 인접 버킷에 삽입할 수 있습니다.
그러나 이는 더 많은 캐시 누락 및 PM 액세스 비용으로 적재율을 향상시킵니다.
따라서 대부분의 접근 방식은 탐색 거리를 고정된 수로 제한합니다. 예를 들어 CCEH는 4개 이하의 캐시라인을 탐색합니다.
그러나 우리의 평가(섹션 6)에서는 선형 탐색만으로는 높은 적재율을 달성하는 데 충분하지 않음을 보여줍니다.
[38] M. Nam, H. Cha, Y. ri Choi, S. H. Noh, and B. Nam.
Write-optimized dynamic hashing for persistent memory.
영구 메모리를 위한 쓰기 최적화 동적 해싱.
In 17th USENIX Conference on File and Storage Technologies (FAST 19), pages 31–44, Feb. 2019.
⬜️ 동적 PM 해싱의 또 다른 중요한 측면은 특히 3단계 프로세스인 세그먼트 분할 중에 실패 원자성(failure atomicity)을 보장하는 것입니다.
(1) PM에 새 세그먼트를 할당하고,
(2) 이전(old) 세그먼트의 레코드를 새 세그먼트로 다시 해시하고
(3) 디렉토리에 새 세그먼트를 등록하고 로컬 깊이를 업데이트합니다.
CCEH와 같은 기존 접근 방식은 3단계에만 초점을 맞추고 1~2단계를 둘러싼 PM 관리 문제를 회피했습니다(side-stepping).
1단계 또는 2단계 중에 시스템이 충돌하는 경우 영구적인 메모리 누수를 방지하기 위해 다시 시작할 때 새 세그먼트가 회수되도록 보장해야 합니다.
섹션 4와 6.1에서는 Dash의 솔루션과 기존 접근 방식에 대한 솔루션을 설명합니다.
🟢 3. DESIGN PRINCIPLES - 설계 원칙
앞서 언급한 Optane DCPMM의 문제와 성능 특성은 다음과 같은 Dash 설계 원칙으로 이어집니다.
⬜️ 불필요한 PM 읽기 및 쓰기를 모두 피합니다.
탐색(Probing) 성능은 검색 작업(operations)뿐만 아니라 다른 모든 작업에도 영향을 미칩니다.
따라서 Dash는 PM 쓰기를 줄이는 것 외에도 불필요한 PM 읽기를 제거하여 대역폭을 보존하고
긴 종단 간(end-to-end) 읽기 대기 시간의 영향을 완화해야 합니다.
⬜️ Lightweight Concurrency. - 경량 동시성.
Dash는 지속성이 보장되는 멀티코어 시스템에서 잘 확장되어야 합니다.
제한된 대역폭을 고려할 때 동시성 제어는 많은 오버헤드를 발생시키지 않도록 가벼워야 합니다.
(즉, 읽기 잠금과 같은 검색 작업에 대한 PM 쓰기를 피해야 합니다)
이상적으로는 구현하기가 상대적으로 쉬워야 합니다.
⬜️ Full Functionality. - 전체 기능.
대시는 해시 테이블을 실제로 유용하게 만드는 중요한 기능을 희생(sacrifice)하거나 절충(trade off)해서는 안 됩니다.
특히, 거의 즉각적인(near-instantaneous) 복구와 가변 길이(variable-length) 키를 지원하고 높은 공간 활용도를 달성해야 합니다.
🟢 4. Dash FOR EXTENDIBLE HASHING - 확장 가능한 해싱을 위한 대시
섹션 3의 원칙을 기반으로 Dash-EH(Dash-Extendible Hashing)의 맥락에서 대시를 설명합니다.
섹션 5에서는 대시가 선형 해싱에 어떻게 적용되는지 논의합니다.
📦 4.1 Overview - 개요
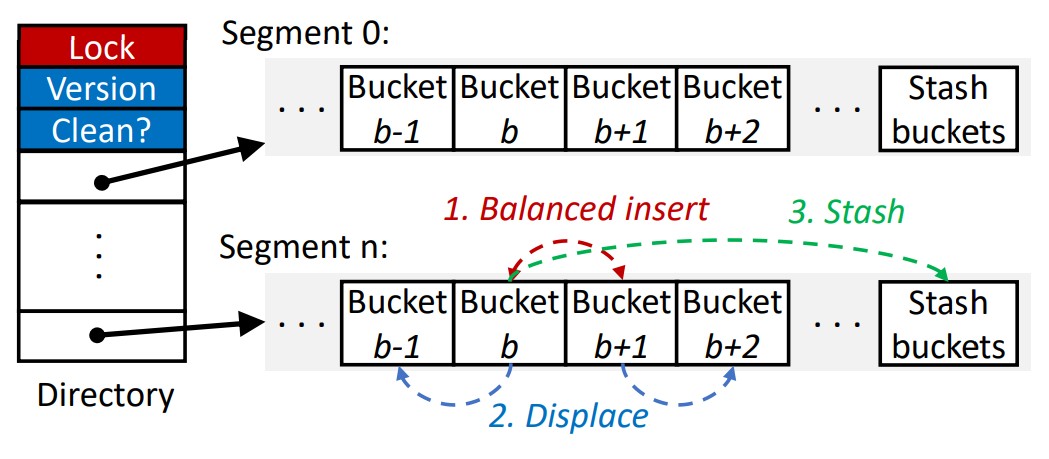
⬜️ 이전 접근 방식과 유사하게 Dash-EH는 세그먼트(segmentation)을 사용합니다.
그림 3에 표시된 것처럼 각 디렉토리 항목은 삽입을 위한 공간이 충분하지 않은 일반 버킷의 오버플로 레코드에 대한
고정된 수의 일반(normal) 버킷과 숨김(stash) 버킷으로 구성된 세그먼트를 가리킵니다.
잠금(Lock), 버전 번호(Version) 및 정리 표시(Clean?)는 나중에 설명하는 동시성 제어 및 복구를 위한 것입니다.
⬜️ 그림 4는 버킷의 내부를 보여줍니다.
버킷 탐색(probing)에 사용되는 메타데이터를 처음 32바이트에 배치하고,
그 뒤에 여러 16바이트 레코드(키-값 쌍) 슬롯을 배치합니다.
각 슬롯의 처음 8바이트는 키(또는 8바이트보다 긴 키에 대한 포인터)를 저장합니다.
나머지 8바이트는 Dash에 불투명(opaque)한 페이로드를 저장합니다.
불투명(opaque)한 페이로드는 애플리케이션의 필요에 따라 인라인 값 또는 포인터가 될 수 있습니다.
버킷의 크기는 조정 가능합니다.
현재 구현에서는 더 나은 집약성을 위해 256바이트(Optane DCPMM [22]의 블록 크기)로 설정되어 있습니다.
이를 통해 버킷당 14개의 레코드(각각 16바이트)를 저장할 수 있습니다.
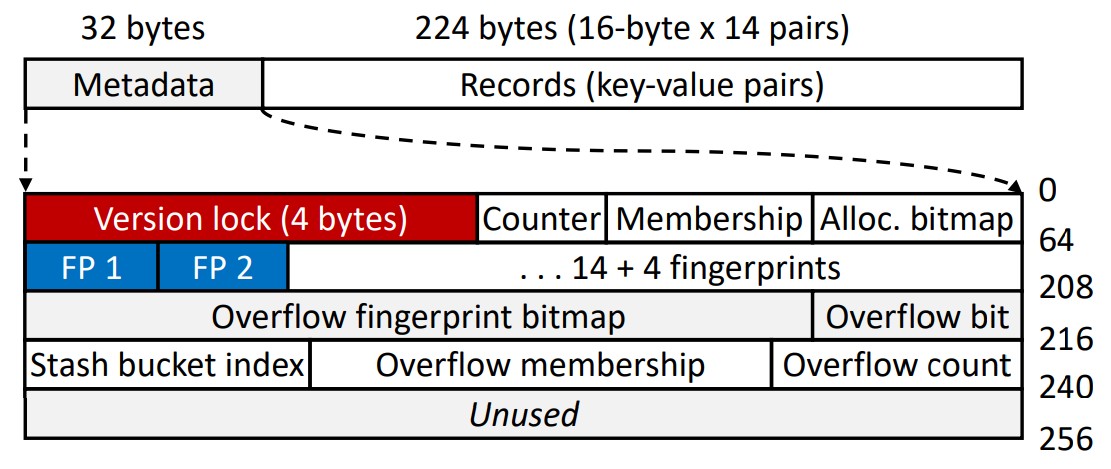
처음 32바이트는 탐색 및 적재율를 최적화하는 메타데이터에 할당되고, 그 뒤에 레코드가 할당됩니다.
일반 버킷과 숨김 버킷은 동일한 레이아웃을 공유합니다.
[22] DCPMM: J. Izraelevitz, J. Yang, L. Zhang, J. Kim, X. Liu, A. Memaripour, Y. J. Soh, Z. Wang, Y. Xu, S. R. Dulloor, J. Zhao, and S. Swanson.
Basic performance measurements of the Intel Optane DC Persistent Memory Module, 2019.
Intel Optane DC 영구 메모리 모듈의 기본 성능 측정
⬜️
32바이트 메타데이터(Metadata)에는 해시 테이블 작업을 처리하고 설계 원칙을 실현하기 위한 Dash-EH의 주요 데이터 구조가 포함되어 있습니다.
(1) 낙관적 동시성 제어(optimistic concurrency control)를 위해 4바이트 버전 잠금으로 시작합니다(섹션 4.4).
(2) 4비트 카운터(Counter)는 버킷에 저장된 레코드 수를 기록합니다. -> 4비트 GET_COUNT(var)
(3) 멤버십 비트맵(Membership)은 나중에 설명할 버킷 로드 밸런싱을 위해 예약되어 있습니다(섹션 4.3). -> 14비트 GET_MEMBER(var)
(4) 할당 비트맵(Alloc. bitmap)은 슬롯당 1비트를 예약하여 해당 슬롯이 유효한 레코드를 저장하는지 여부를 나타냅니다. -> 14비트 GET_BITMAP(var)
다음은 탐색(probing)을 가속화하고 적재율을 향상시키는 지문 및 카운터와 같은 구조입니다.
지문 영역을 스캔하면 대부분의 불필요한 탐색을 피할 수 있습니다.
소스를 보면 그림 4와는 다르게 메타데이터의 순서는 allocation bitmap:14bit + pointer bitmap:14bit + counter:4bit 입니다.
uint32_t bitmap; // allocation bitmap:14bit + pointer bitmap:14bit + counter:4bit
ex_finger.h constexpr int allocMask = (1 << kNumPairPerBucket) - 1; // 16384-1=16383 '0011 1111 1111 1111'
📦 4.2 Fingerprinting - 지문
⬜️ 버킷 탐색(즉, 하나의 버킷에서 검색)은 키 존재 여부를 확인하기 위해 해시 테이블에서 지원하는 모든 작업(검색, 삽입 및 삭제)에
필요한 기본 작업(operation)입니다.
버킷을 검색(Searching)하려면 일반적으로 슬롯에 대한 선형 스캔이 필요합니다.
이로 인해 많은 캐시(cache) 누락이 발생할 수 있으며 특히 포인터로 저장된 긴 키의 경우 PM 읽기의 주요 소스입니다.
PM의 해시 테이블이 낮은 성능을 보이는 주요 이유입니다.
더욱이, 부정(negative) 검색 작업(즉, 대상 키가 존재하지 않는 경우)에 대한 스캔은 완전히 불필요합니다.
⬜️ 불필요한 스캔을 줄이기 위해 지문(fingerprinting)[43]를 사용합니다.
이는 상각된(amortized) 키 로드 수 1로 PM 액세스를 줄이기 위해 트리에서 사용되었습니다.
캐시 누락을 줄이고 탐색 속도를 높이기 위해 해시 테이블에 이를 채택했습니다.
지문은 키가 존재할 수 있는지 예측하기 위한 1바이트 키 해시입니다.
키 해시 값의 최하위(the least significant) 바이트를 사용합니다.
키를 탐색하기 위해 탐색 스레드는 먼저 검색 키의 지문과 일치하는 지문이 있는지 확인합니다.
그런 다음 지문이 일치하는 슬롯에만 액세스하고 다른 모든 슬롯은 건너뜁니다.
일치하는 항목이 없으면 키가 버킷에 존재하지 않는 것입니다.
이 프로세스는 SIMD 명령어를 사용하여 더욱 가속화될 수 있습니다. [21]
[43] I. Oukid, J. Lasperas, A. Nica, T. Willhalm, and W. Lehner.
FPTree: A hybrid SCM-DRAM persistent and concurrent B-tree for storage class memory.
스토리지 클래스 메모리를 위한 하이브리드 SCM-DRAM 영구 및 동시 B-트리
In Proceedings of the 2016 International Conference on Management of Data, SIGMOD, pages 371–386, 2016.
[21] Intel Corporation. Intel 64 and IA-32 architectures software developer’s manual. 2015.
⚛ SIMD (Single Instruction, Multiple Data)는 Intel 64 및 IA-32 아키텍처의 중요한 특징 중 하나로,
벡터 프로세싱을 통해 병렬 처리를 지원하는 기술입니다.
SIMD 명령어는 단일 명령어로 여러 데이터 요소를 동시에 처리할 수 있어,
대규모 데이터 연산이 필요한 작업에서 성능을 크게 향상시킵니다.
Intel의 SIMD 기술은 주로 다음과 같은 두 가지 주요 명령어 세트를 포함합니다:
1. MMX (MultiMedia eXtensions): 1996년에 도입된 MMX는 최초의 SIMD 명령어 세트로, 멀티미디어 및 통신 애플리케이션에서의
성능을 향상시키기 위해 설계되었습니다.
MMX는 64비트 레지스터를 사용하여 8비트, 16비트, 또는 32비트 정수 데이터의 병렬 처리를 지원합니다.
2. SSE (Streaming SIMD Extensions) 및 그 후속 버전 (SSE2, SSE3, SSSE3, SSE4, AVX 등): SSE는 1999년에 도입된
확장된 SIMD 명령어 세트로, MMX의 기능을 넘어 부동 소수점 연산을 포함한 다양한 데이터 타입에 대한 병렬 처리를 지원합니다.
SSE2, SSE3, SSSE3, SSE4, 그리고 AVX (Advanced Vector Extensions) 등은 SIMD 명령어 세트의 후속 버전들로,
각각 추가된 명령어와 더 넓어진 레지스터 폭 (최대 256비트)을 통해 성능을 더욱 향상시킵니다.
◎ SIMD 명령어의 주요 특징:
- 병렬 처리: 동일한 명령어가 여러 데이터 요소에 동시에 적용되어, 데이터 처리 속도가 크게 증가합니다.
- 특화된 레지스터: SIMD 명령어는 일반적으로 넓은 레지스터(예: XMM, YMM, ZMM 레지스터)를 사용하여
더 많은 데이터를 한 번에 처리할 수 있습니다.
- 다양한 데이터 타입 지원: 정수, 부동 소수점, 논리 연산 등 다양한 데이터 타입에 대한 병렬 연산을 지원합니다.
◎ 사용 예:
SIMD는 주로 이미지 및 비디오 처리, 신호 처리, 과학적 시뮬레이션, 금융 모델링 등에서 활용됩니다.
예를 들어, 이미지 처리에서는 각 픽셀에 동일한 연산(밝기 조정 등)을 병렬로 적용하여 처리 속도를 높일 수 있습니다.
◎ SIMD 프로그래밍:
SIMD 명령어는 일반적으로 저수준 어셈블리 언어로 사용되지만, 현대의 컴파일러들은 고수준 언어에서도 SIMD 명령어를
자동으로 활용할 수 있는 기능을 제공하여, 개발자가 벡터라이제이션(vectorization) 등의 최적화 기법을 통해
SIMD의 이점을 쉽게 활용할 수 있도록 합니다.
Intel의 64 및 IA-32 아키텍처에서 SIMD에 대한 자세한 설명과 명령어 세트에 대한 구체적인 정보는
"Intel 64 and IA-32 Architectures Software Developer’s Manual"에서 확인할 수 있습니다.
이 매뉴얼은 SIMD 명령어의 구조, 사용 방법, 그리고 성능 최적화에 대한 심도 있는 내용을 포함하고 있습니다.
⬜️ 지문은 특히 부정 검색(검색 키가 존재하지 않는 경우)과 삽입에 대한 고유성 확인에 도움이 됩니다.
또한 Dash는 더 큰 버킷을 사용하여 많은 캐시 누락을 발생시키지 않으면서 더 많은 충돌을 허용하고 적재율을 향상시킬 수 있습니다.
대부분의 불필요한 탐색은 지문으로 방지됩니다.
이 디자인은 1-2개의 캐시라인으로 구성된 작은 버킷을 가짐으로써 성능을 위해 적재율을 교환하는 많은 이전 디자인과 대조됩니다.
⬜️ 그림 4에 표시된 것처럼 각 버킷에는 14개의 슬롯이 포함되어 있지만 지문은 18개(비트 64~208)입니다.
14개는 버킷의 슬롯용이고, 나머지 4개는 숨김(stash) 버킷에 배치되었지만 원래는 현재 버킷에 해시된 키를 나타냅니다.
숨김(stash) 버킷에 대한 액세스를 조기에 방지하여 PM 대역폭을 절약할 수 있습니다.
적재율을 향상시키는 버킷 부하 분산 전략의 일부로 다음 세부 사항을 설명합니다.
📦 4.3 Bucket Load Balancing - 버킷 균형 적재
⬜️ 분할(Segmentation)은 크기를 줄여 디렉터리의 캐시 누락을 줄입니다.
그러나 섹션 2.3과 6에서 설명했듯이 이는 적재율(load factor)을 희생합니다.
단순한(naive) 구현에서는 버킷이 가득 차면 전체 세그먼트를 분할해야 하지만,
세그먼트의 다른 버킷에는 여전히 많은 여유 공간이 있을 수 있습니다.
주요 원인은 새 레코드를 삽입하기 위해 버킷이 선택되는 (유연하지 않은) 방식으로 인해 발생하는 로드 불균형(imbalance)입니다.
즉, 키는 단일 버킷에만 매핑됩니다.
Dash는 필요한 PM 읽기를 제한하면서 버킷 간의 로드 균형을 조정하기 위해 새로운 삽입에 대한 기술 조합을 사용합니다.
알고리즘 1은 아래에 설명된 세 가지 핵심 기술을 사용하여 Dash-EH에서 삽입 작업이 높은 수준에서 작동하는 방식을 보여줍니다.
🟡 Algorithm 1 Dash-EH insert algorithm with bucket load balancing.
알고리즘 1 버킷 로드 밸런싱이 포함된 Dash-EH 삽입 알고리즘.
⬜️ Balanced Insert.
키가 버킷 b에 해시된 레코드를 삽입하기 위해(hash(key) = b) Dash는 버킷 b와 b+1을 모두 조사하고
덜 꽉 찬 버킷에 레코드를 삽입합니다(그림 3 1단계).
알고리즘 1의 17~21행은 아이디어를 보여줍니다. 나중에 레코드가 버킷에 삽입되는 방법에 대해 논의합니다.
그 이유는 PM 액세스(최대 2개의 버킷)를 제한하면서 핫 버킷의 로드를 분할하여 적재율을 향상시키는 것입니다.
균형 잡힌 삽입과 비교하여 선형 탐색을 사용하면 버킷 b...b+n−1이 가득 찬 경우 n > 1인 버킷 b+n에 레코드를 삽입할 수 있습니다.
여러 버킷을 탐색하면 더 많은 PM 읽기 및 캐시 누락이 발생하여 성능이 저하될 수 있습니다.
탐색할 버킷 수를 조정하는 것도 어렵습니다.
⬜️ Displacement. 치환
대상 버킷 b와 탐색 버킷 b+1이 모두 가득 차면 Dash-EH는 새 레코드를 위한 공간을 만들기 위해
버킷 b 또는 b+1에서 레코드를 치환(이동)하려고 시도합니다(알고리즘 1 라인 23-26).
균형 삽입을 사용하면 버킷 n+1의 레코드를 n+2로 이동할 수 있습니다.
(1) 버킷 중 하나에 삽입될 수 있고(즉, n+2는 이동 중인 레코드의 탐색 버킷임),
(2) 버킷 n + 2에는 여유 슬롯이 있습니다.
따라서 hash(key) = b이고 b와 b + 1이 모두 꽉 찬 레코드의 경우,
먼저 b + 1에서 hash(key) = b+1인 레코드를 찾아 b+2로 이동하려고 합니다.
그러한 레코드가 존재하지 않으면 버킷 b에 대해 반복하지만 hash(key) = b−1(대상 버킷)로 레코드를 이동합니다.
본질적으로 치환은 균형 삽입과 유사한 전략을 따르지만 기존 레코드에 대한 것입니다.
우리는 치환를 가속화하기 위해 버킷당(per-bucket) 멤버십 비트맵(그림 4)을 사용합니다.
비트가 설정되면 해당 키가 원래 이 버킷에 해시되지 않은 것입니다.
균형 잡힌 삽입 또는 치환 때문에 여기에 배치되었습니다.
버킷 b(b+1)를 확인할 때 멤버십 비트가 설정된(설정 해제) 레코드가 대체될 수 있습니다.
그런 다음 Dash는 실제 키를 검사할 필요 없이 비트맵을 스캔하여 이동할 레코드를 직접 선택하기만 하면 됩니다.
이는 불필요한 PM 액세스를 줄이고 인라인이 아니지만 포인터로 표시되는 가변 길이 키에 특히 유용합니다.
⬜️ Stashing. 숨겨놓은 버킷
균형 잡힌 삽입 및 치환 후에 레코드를 버킷 b 또는 b+1에 삽입할 수 없는 경우,
세그먼트 분할이 발생하기 전에 숨김 버킷이 최후의 수단이 됩니다.
그림 3에서는 조정 가능한 숨김 버킷 수가 각 세그먼트의 일반 버킷 뒤에 있습니다.
레코드를 대상 버킷이나 탐색 버킷에 삽입할 수 없는 경우 해당 레코드를 숨김 버킷에 삽입합니다.
우리는 이러한 레코드를 오버플로 레코드(overflow records)라고 부릅니다.
숨김 버킷은 일반 버킷과 동일한 레이아웃을 사용합니다.
숨김 버킷 검색은 일반 버킷 탐색과 동일한 절차를 따릅니다(섹션 4.2 참조).
숨김은 적재율을 개선하는 데 효과적일 수 있지만 적지 않은 오버헤드가 발생할 수 있습니다.
더 많은 숨김 버킷을 사용할수록 이를 조사하는 데 더 많은 CPU 주기와 PM 읽기가 필요합니다.
이는 삽입 작업의 부정 검색 및 고유성 검사에 특히 바람직하지 않습니다.
왜냐하면 둘 다 완전히 불필요할 수 있음에도 불구하고 모든 숨김 버킷을 조사해야 하기 때문입니다.
이 문제를 해결하기 위해 우리는 일반 버킷에 지문을 포함한 레코드 메타데이터를 설정하고
숨김 버킷에 대한 실제 레코드 액세스만 참조하려고 합니다.
그림 4에 표시된 것처럼 버킷당 4개의 추가 지문이 숨김 버킷에 저장된 오버플로 레코드용으로 예약되어 있습니다.
4비트 오버플로 지문 비트맵(Overflow fingerprint bitmap:7비트)은 해당 지문 슬롯이 점유되어 있는지 여부를 기록합니다.
또 다른 오버플로 비트(Overflow bit:1비트)는 버킷이 숨김 버킷에 대한 레코드를 오버플로했는지 여부를 나타냅니다.
알고리즘 1(27~29행)은 이 프로세스를 보여줍니다.
일반 버킷에 레코드를 삽입하는 것과 마찬가지로 오버플로 레코드의 지문은 오버플로 지문이
원래 이 버킷에 속하는지 여부를 나타내는 오버플로 멤버십 비트맵(Overflow membership bitmap)을 사용하여
버킷 검색을 한 번 더 허용합니다.
오버플로 레코드당 2비트 숨김 버킷 인덱스(Stash bucket index)는 더 빠른 조회를 위해 레코드가 삽입되는 4개의
숨김 버킷 중 하나를 나타냅니다.
오버플로 지문을 대상 버킷과 탐색 버킷 모두에 삽입할 수 없는 경우 대상 버킷의 오버플로 카운터(Overflow count)를 늘립니다.
카운터가 양수이면 탬색 스레드는 숨김 영역을 확인하여 키가 존재하는지 여부를 확인해야 합니다.
따라서 오버플로 카운터가 거의 양수가 되지 않도록 각 버킷에 충분한 오버플로 지문 슬롯을 예약하는 것이 바람직합니다.
섹션 6에서 볼 수 있듯이 세그먼트당 2-4개의 숨김 버킷을 사용하면 상당한 오버헤드를 부과하지 않고
적재율을 90% 이상으로 향상시킬 수 있습니다.
📦 4.4 Optimistic Concurrency - 낙관적 동시성
⬜️ Dash는 낙관적 동시성 제어에서 영감을 받은 낙관적 버킷 수준 잠금인 낙관적 잠금을 사용합니다.
삽입 작업은 전통적인 버킷 수준 잠금(bucket-level locking)을 따라 영향을 받는 버킷을 잠급니다.
검색 작업은 잠금을 유지하지 않고(따라서 PM에 쓰기 방지) 진행할 수 있지만 읽기 레코드를 확인해야 합니다.
이것이 작동하기 위해 Dash에서 잠금은 다음과 같이 구성됩니다.
(1) "잠금(the lock)" 역할을 하는 단일 비트와
(2) 충돌을 감지하기 위한 버전 번호(그림 3의 즉시 복구 버전 번호와 혼동하지 마십시오)
알고리즘 1의 7행에 표시된 것처럼 삽입 스레드는 대상 및 탐색 버킷에 대한 버킷 수준(bucket-level) 잠금을 획득합니다.
이는 성공할 때까지 CAS(compare-and-swap, 비교 및 교체) 명령을 시도하여 각 버킷에 잠금 비트를
원자적으로 설정함으로써 수행됩니다.
그런 다음 스레드는 임계 섹션에 들어가 작업을 계속합니다.
삽입이 완료된 후 스레드는
(1) 잠금 비트를 재설정하고
(2) 원자 쓰기를 사용하여 한 단계로 버전 번호를 1씩 증가시켜 잠금을 해제합니다.
⬜️ 버킷에서 키를 탐색하기 위해, Dash는 먼저 잠금 단어의 스냅샷을 찍고 동시 작성자(concurrent writer)가
잠금을 보유하고 있는지(잠금 비트가 설정되어 있는지) 확인합니다.
잠금 비트가 설정되어 있다면, 잠금이 해제될 때까지 기다렸다가 반복합니다.
그런 다음, 잠금을 유지하지 않고도 버킷을 읽을 수 있습니다.
작업(operations)이 완료되면 읽기 스레드는 잠금 단어(lock word)를 다시 읽어 버전 번호가 변경되지 않았는지 확인하고,
버전 번호가 변경되었다면, 동시 쓰기로 인해 레코드가 수정되었을 수 있으므로 레코드가 유효하지 않을 수 있으므로 전체 작업을 다시 시도합니다.
이 잠금 없는(lock-free) 읽기 설계에서는 세그먼트 할당 해제(병합으로 인해)가 읽기(readers)가 세그먼트를 사용하지 않거나
사용하지 않을 경우에만 발생해야 합니다.
우리는 많은 오버헤드를 발생시키지 않고 이를 달성하기 위해 시대 기반 회수(epoch-based reclamation)[14]를 사용합니다.
[14] K. Fraser. Practical lock-freedom. PhD thesis, University of Cambridge, UK, 2004.
⬜️ Dash는 세그먼트 수준(segment-level) 잠금을 사용하지 않으므로 세그먼트 수준에서 PM 액세스를 저장합니다.
결과적으로 구조 수정 작업(Structural Modification Operations 세그먼트 분할과 같은 SMO)은 각 세그먼트의 모든 버킷을 잠가야 합니다.
디렉터리를 두 배로 늘리거나 반으로 줄이는 것도 비슷하게 처리됩니다.
디렉터리 잠금은 디렉터리가 두 배로 또는 반으로 줄어들 때만 유지됩니다.
디렉터리에 대한 다른 작업(예: 새 세그먼트를 가리키도록 디렉터리 항목 업데이트)의 경우 잠금이 적용되지 않습니다.
대신 디렉터리 잠금을 사용하지 않고 검색 작업으로 처리됩니다.
이는 세그먼트 수준에서 격리를 보장하기 때문에 안전합니다.
삽입(inserting) 스레드는 영향을 받는 버킷을 보호하기 위해 먼저 잠금을 획득해야 합니다.
"실제(Real)" 탐색(검색/삽입)은 디렉터리 잠금을 읽지 않고 진행되지만, 이 두 읽기 결과가 일치하는지 테스트하기 위해
디렉터리를 다시 읽어 올바른 세그먼트를 입력했는지 다시 확인해야 합니다.
그렇지 않은 경우 스레드는 전체 작업을 중단하고 다시 시도합니다.
📦 4.5 Support for Variable-Length Keys - 가변 길이 키 지원
Dash는 일반적인 접근 방식인 가변 길이 키에 대한 포인터를 저장합니다.
인라인(최대 8바이트의 고정 길이 키)과 포인터 모드 사이를 전환할 수 있는 손잡이(knob)가 제공됩니다.
포인터 역참조로 인해 추가 오버헤드가 발생할 수 있지만 지문을 사용하면 이 문제가 크게 완화됩니다.
대상 키가 존재하지 않는 부정 검색의 경우 일치하는 지문이 없으므로 키 탐색이 전혀 발생하지 않습니다.
긍정 검색의 경우 섹션 4.2에서 논의한 대로 상각된(amortized) 키 로드 수(따라서 키 포인터를 따라가면서
발생하는 캐시 누락 수)는 1입니다[43].
[2] J. Arulraj, J. J. Levandoski, U. F. Minhas, and P. Larson.
Bztree: A high-performance latch-free range index for non-volatile memory. PVLDB, 11(5):553–565, 2018.
Bztree: 비휘발성 메모리를 위한 고성능 래치 없는 범위 인덱스
[38] M. Nam, H. Cha, Y. ri Choi, S. H. Noh, and B. Nam.
Write-optimized dynamic hashing for persistent memory.
영구 메모리를 위한 쓰기 최적화 동적 해싱
In 17th USENIX Conference on File and Storage Technologies (FAST 19), pages 31–44, Feb. 2019.
[43] I. Oukid, J. Lasperas, A. Nica, T. Willhalm, and W. Lehner.
FPTree: A hybrid SCM-DRAM persistent and concurrent B-tree for storage class memory.
FPTree: 스토리지 클래스 메모리를 위한 하이브리드 SCM-DRAM 영구 및 동시 B-트리
In Proceedings of the 2016 International Conference on Management of Data, SIGMOD, pages 371–386, 2016.
[68] P. Zuo, Y. Hua, and J. Wu.
Write-optimized and high-performance hashing index scheme for persistent memory.
영구 메모리를 위한 쓰기 최적화 및 고성능 해싱 인덱스 체계
In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 461–476, Oct. 2018.
📦 4.6 Record Operations - 레코드 작업
이제 Dash-EH가 지속성을 보장하면서 PM에서 삽입, 검색 및 삭제 작업을 수행하는 방법에 대해 자세히 설명합니다.
🟡 Algorithm 2 Bucket insert and displacement in Dash-EH.
⬜️ Insert.
섹션 4.3에서는 삽입을 위한 상위 수준 단계를 제시했습니다. (4.3 Bucket Load Balancing)
여기서는 버킷 수준(bucket-level)에 중점을 둡니다.
알고리즘 2의 bucket::insert 함수에서 볼 수 있듯이, 먼저 새 레코드를 작성하고 유지한 다음(3~4행)
메타데이터(지문, 할당 비트맵, 카운터 및 멤버십, 6~12행)를 설정합니다.
할당 비트맵(Alloc. bitmap), 멤버쉽 비트맵(Membership) 및 카운터(Counter)는 한 단어에 있어서,
한 번의 원자 쓰기로 업데이트됩니다.
그런 다음 모든 메타데이터를 유지하기 위해 CLWB 및 펜스가 발행됩니다.
(라인 16 CLWB+FENCE(alloc_bitmap, membership, counter, FP)
비트맵의 해당 비트가 설정되면 해당 레코드는 다른 스레드에서 볼 수 있습니다.
비트맵이 유지되기 전에 충돌이 발생하면 새 레코드는 유효하지 않은 것으로 간주됩니다.
그렇지 않으면 레코드가 성공적으로 삽입됩니다.
이를 통해 일관성을 유지하면서 비용이 많이 드는 로깅(logging)을 피할 수 있습니다.
⬜️ Displacing a record needs two steps:
레코드를 바꾸려면(Displacing)
(1) 새 버킷에 레코드를 삽입하고
(2) 원래 버킷에서 삭제하는 두 단계가 필요합니다.
알고리즘 2의 치환 함수에서 볼 수 있듯이 데이터 이동 없이 할당 비트맵의 해당 비트를 재설정하여 2단계가 수행됩니다.
2단계가 완료되기 전에 충돌이 발생하는 경우 두 버킷 모두에 레코드가 나타납니다.
이를 위해서는 복구 시 중복 감지 메커니즘이 필요하며, 이는 런타임에 걸쳐 상각(amortized)됩니다(섹션 4.8 참조).
삽입이 숨김 버킷에서 발생해야 하는 경우 일반 버킷에 오버플로 메타데이터를 설정합니다.
이는 8바이트 쓰기로는 원자적으로 수행할 수 없으며 충돌 일관성을 위해 (복잡한) 프로토콜이 필요할 수 있습니다.
오버플로 메타데이터는 최적화이며 정확성에 영향을 주지 않습니다.
메타데이터 없이도 레코드를 올바르게 찾을 수 있습니다.
따라서 우리는 이를 명시적으로 유지하지 않고 지연 복구 메커니즘을 사용하여 점진적으로 구축합니다(나중에 설명).
🟡 Algorithm 3 Dash-EH search algorithm.
⬜️ Search. 검색
균형 잡힌 삽입 및 치환를 사용하면 레코드를 대상 버킷 b(여기서 b = 해시(키)) 또는 탐색 버킷 b+1에 삽입할 수 있습니다.
그런 다음 검색 작업에서는 레코드가 b에서 발견되지 않으면 두 가지를 모두 확인해야 합니다.
알고리즘 3에서 볼 수 있듯이 탐색 스레드는 먼저 디렉터리를 읽어 해당 세그먼트와 버킷에 대한 참조를 얻습니다(4~5행).
그런 다음 나중에 확인하기 위해 두 버킷(라인 6~7)의 버전 번호 스냅샷을 찍습니다.
10행에서 세그먼트가 변경되지 않았는지(즉, 디렉토리 항목이 여전히 이를 가리키고 있는지) 확인하고
필요한 경우 다시 시도합니다.
세그먼트 확인이 통과되면 14~15행에서 대상/탐색 버킷이 수정(즉, 잠김)되고 있는지 확인합니다.
그렇지 않은 경우에는 bucket::search 함수(표시되지 않음)를 사용하여 대상 및 탐색 버킷(17~27행)을 계속 검색합니다.
bucket::search가 반환된 후(라인 18 및 24) 잠금 버전이 변경되지 않았는지 확인해야 합니다.
두 버킷 모두 레코드를 포함하지 않는 경우 숨김 버킷(31~37행)에 저장될 수 있습니다.
오버플로 횟수(Overflow count) > 0인 경우 오버플로 지문 영역에 버킷의 모든 오버플로 레코드에 대한 공간이 충분하지 않으므로
숨김 버킷을 검색합니다.
그렇지 않으면 일치하는 지문이 있는 경우에만 숨김 액세스가 필요합니다(31~35행).
⬜️ Delete. 삭제
일반 버킷에서 레코드를 삭제하려면, 할당 비트맵(Alloc bitmap)에서 해당 비트를 재설정하고 카운터(Counter)를 감소시키며
이러한 변경 사항을 유지합니다.
그러면 해당 슬롯은 나중에 다시 사용할 수 있게 됩니다.
숨김 버킷에서 레코드를 삭제하려면, 할당 비트맵(Alloc bitmap)의 비트를 지우는 것 외에도 이 레코드가 오버플로된 대상 버킷의
오버플로 지문(존재하는 경우)도 지웁니다.
오버플로 지문이 존재하지 않으면 대상 버킷의 오버플로 카운터(Overflow counter)만 감소합니다.
📦 4.7 Structural Modification Operations - SMO, 구조 수정 작업
⬜️ 스레드가 버킷에 레코드를 삽입하는 모든 옵션을 소진하면, 세그먼트 분할과 디렉터리 확장이 트리거됩니다.
반대로 적재율이 임계값 아래로 떨어지면 세그먼트를 병합하여 공간을 절약할 수 있습니다.
높은 수준에서 세그먼트 S를 분할하려면 세 단계가 필요합니다.
(1) 새 세그먼트 N을 할당하고,
(2) S의 키를 재해시해서 S와 N에 레코드를 재배포(redistribute)하고,
(3) N을 디렉터리에 연결하고 N과 S의 로컬 깊이를 설정합니다.
이러한 작업으로 인해 해시 테이블의 구조가 변경되므로 높은 성능을 유지하면서 PM에서 충돌 일관성을 유지해야 합니다.
⬜️ 충돌 일관성을 위해 Dash-EH는 측면 링크를 사용하여 모든 세그먼트를 오른쪽 이웃에 연결합니다.
각 세그먼트에는 해당 세그먼트가 SMO에 있는지, 분할 중인 세그먼트인지 새 세그먼트인지를 나타내는 상태 변수가 있습니다.
초기 값 0은 세그먼트가 SMO가 진행중이 아님을 나타냅니다.
그림에서 볼 수 있듯이 Dash-EH는 다른 최근 연구와 유사하게 해시 값의 MSB(최상위 비트,Most Significant Bits)를 사용하여
세그먼트와 버킷을 처리(address)하고 구성(organize)합니다(즉, 디렉터리는 해시 값의 MSB로 인덱싱됩니다).
이는 버킷 주소를 지정하기 위해 해시 값의 LSB를 사용하는 섹션 2.2에 설명된 전통적인(traditional) 확장 가능한 해싱과 다릅니다.
LSB를 사용하는 것은 디스크 시대에 I/O를 줄이기 위한 선택이었습니다.
단순히 원래 디렉터리를 복사하고 디렉터리 파일에 추가하면 디렉터리를 두 배로 늘릴 수 있습니다.
PM에서는 디렉터리를 두 배로 늘리는 이점이 무시됩(marginalized)니다.
따라서 디렉터리를 연속 주소 공간에 유지하려면 PM에서 두 배 크기의 디렉터리를 할당하고 유지해야 합니다.
또한 MSB를 사용하면 동일한 세그먼트를 가리키는 디렉터리 항목을 같은 위치에 배치할(co-located) 수 있으므로
분할 중에 캐시라인 플러시가 줄어듭니다[38].
[38] M. Nam, H. Cha, Y. ri Choi, S. H. Noh, and B. Nam.
Write-optimized dynamic hashing for persistent memory.
영구 메모리를 위한 쓰기 최적화 동적 해싱
In 17th USENIX Conference on File and Storage Technologies (FAST 19), pages 31–44, Feb. 2019.
⬜️ 세그먼트 S를 분할하려면, 먼저 해당 상태를 'SPLITTING'으로 표시하고 주소가 S의 사이드 링크에 저장된 새 세그먼트 N을 할당합니다.
그런 다음 N은 S의 사이드 링크를 자체적으로 전달하도록 초기화됩니다.
지역 깊이는 S에 1을 더한 지역 깊이로 설정됩니다.
그런 다음 N의 상태를 'NEW'로 변경하여 이 새 세그먼트가 복구 목적으로 분할된 SMO의 일부임을 나타냅니다(섹션 4.8 참조).
우리는 PM 프로그래밍 라이브러리(PMDK[20])를 사용하여 새 세그먼트를 원자적으로 할당하고 초기화합니다.
충돌이 발생하는 경우 할당된 PM 블록은 Dash 또는 할당자의 소유가 보장되며 영구적으로 유출되지(leaked) 않습니다.
초기화 후 N과 S 간에 레코드를 재배포하여(redistributing) 2단계를 마무리합니다.
S에서 N으로 이동한 레코드는 N에 삽입된 후 S에서 삭제됩니다.
재해싱/재배포 프로세스는 원자적으로 수행될 필요가 없습니다.
재해싱 도중에 충돌이 발생하면 (지연 lazy) 복구 시 고유성 검사를 통해 재해싱 프로세스를 다시 실행하여
충돌 전에 이미 N에 삽입된 레코드에 대한 작업 반복을 방지합니다.
자세한 내용은 나중에 섹션 4.8에서 설명합니다.
그림 5(b)는 2단계 이후의 해시 테이블 상태를 보여준다.
그런 다음 N에 대한 디렉토리 항목과 S의 지역 깊이가 그림 5(c)와 같이 업데이트됩니다.
마찬가지로 이러한 업데이트는 경량 로깅과 같은 접근 방식을 사용할 수 있는 원자 PMDK 트랜잭션을 사용하여 수행됩니다.
다른 많은 시스템에서는 조기(pre-mature) 분할이 자주 발생하기 때문에 높은 성능을 유지하기 위해 로깅 사용을 피합니다.
그러나 높은 적재율을 제공하는 버킷 로드 밸런싱 덕분에 Dash에서는 분할이 훨씬 더 드뭅니다(rarer)(섹션 4.3).
이를 통해 Dash-EH는 많은 세부 정보를 추상화하고 구현을 용이하게 하는 로깅 기반 PMDK 트랜잭션을 사용할 수 있습니다.
[20] Intel. PMDK: Persistent Memory Development Kit. 2018. http://pmem.io/pmdk/libpmem/.
영구 메모리 개발 키트
📦 4.8 Instant Recovery - 즉시 복구
⬜️ Dash는 시스템이 사용자 요청을 수락할 준비가 되기 전에 일정한 양의 작업(1바이트 카운터 읽기 및 쓰기 가능)을
요구함으로써 진정한 즉시 복구를 제공합니다.
그림 3에 표시된 글로벌 버전 번호 V와 확인(clean) 마커, 그리고 세그먼트별 버전 번호를 추가합니다.
확인(clean)은 시스템이 완전히(이상없이) 종료되었는지 여부를 나타내는 부울입니다.
V는 복구(런타임 중)가 필요한지 여부를 알려줍니다.
완전히 종료되면 clean이 true로 설정되고 지속됩니다.
다시 시작할 때 clean이 true이면, clean을 false로 설정하고 요청 처리를 시작합니다.
그렇지 않으면(clean이 false이면) V를 1씩 증가시키고 요청 처리를 시작합니다.
완전한 종료 및 충돌 사례 모두에서 "복구(recovery)"에는 깨끗한 읽기 및 V 범핑(bumping)만 포함됩니다.
실제 복구 작업은 세그먼트 액세스를 통해 상각(amortized)됩니다.
⬜️ 세그먼트에 액세스하기 위해 액세스하는 스레드는 먼저 세그먼트 버전이 V와 일치하는지 확인합니다.
그렇지 않은 경우 스레드는
(1) 원래 작업(예: 삽입 또는 검색)을 수행하기 전에 세그먼트를 일관된 상태로 복구하고
(2) 향후 액세스가 복구 단계를 건너뛸 수 있도록 세그먼트의 버전 번호를 V로 설정합니다.
이러한 지연 복구 접근 방식(lazy recovery approach)을 사용하면 세그먼트에 액세스할 때까지 세그먼트가 복구되지 않습니다.
여러 스레드가 복구해야 하는 세그먼트에 액세스할 수 있습니다.
우리는 복구 목적으로만 세그먼트 수준 잠금을 사용하지만, 스레드는 세그먼트의 버전 번호가 V와 일치하지 않는 경우에만
잠금을 획득하려고 시도합니다.
현재 구현에서는 1바이트 버전 번호를 사용합니다.
버전 번호가 초과(wraps around)되어 복구가 필요한 경우 V를 0으로 재설정하고 각 세그먼트의 버전 번호를 1로 설정합니다.
충돌 및 반복적인 충돌은 드문 사건이므로 이러한 초과(wrap-around) 사례는 매우 드뭅니다.
⬜️ 세그먼트를 복구하려면 네 단계가 필요합니다.
(1) 버킷 잠금 지우기,
(2) 중복 레코드 제거,
(3) 오버플로 메타데이터 재구축,
(4) 진행 중인 SMO 계속
일부 잠금은 충돌(crash) 시 잠금 상태가 될 수 있으므로 각 버킷의 모든 잠금을 재설정해야 합니다.
인접한 버킷의 지문을 확인하여 중복된 레코드를 감지합니다.
실제 키 비교는 지문이 일치하는 경우에만 필요하므로 이는 가볍습니다.
성능상의 이유로 충돌 일관성을 보장하지 않으므로, 일반 버킷의 오버플로 메타데이터도 숨김 버킷의 레코드를 기반으로
삭제하고(cleared) 다시 작성해야 합니다.
마지막으로 세그먼트가 'SPLITTING' 상태인 경우 액세스하는 스레드는 세그먼트의 사이드 링크를 따라 이웃 세그먼트가
'NEW' 상태인지 테스트합니다.
그렇다면 재해싱-재분배 프로세스를 다시 시작하고 분할을 완료합니다.
그렇지 않으면 사실상 분할을 롤백하는 상태 변수를 재설정합니다.
🟢 5. Dash FOR LINEAR HASHING - 선형 해싱을 위한 Dash(대시)
우리는 이전에 논의한, 빌딩 블록(균형 삽입(balanced insert), 치환(displacement), 지문(fingerprinting) 및 낙관적 동시성(optimistic concurrency))을 사용하는 Dash 지원(Dash-enabled) 선형 해싱인 Dash-LH를 제시합니다. 여기서는 반복하지 않고 선형 해싱과 관련된 설계 결정에 중점을 둡니다.
📦 5.1 Overview - 개요
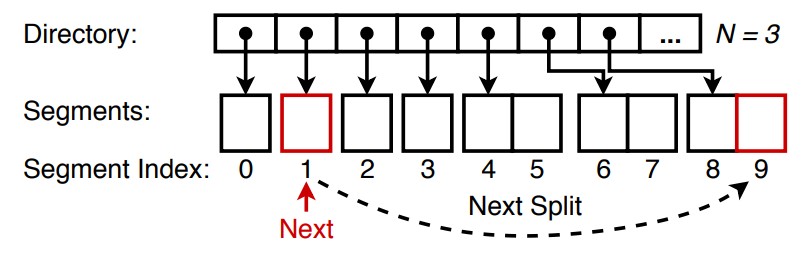
⬜️ 그림 6(지금은 세그먼트 0~3에 중점을 둡니다)은 Dash-LH의 전체 구조를 보여줍니다. Dash-EH와 마찬가지로 Dash-LH도 세그먼트 수준에서 세분화(segmentation) 및 분할을 사용합니다. 그러나 우리는 세그먼트가 분할된 후 진행되는 Next 포인터가 가리키는 세그먼트를 항상 분할하기 위해 선형 해싱 접근 방식을 따릅니다. 분할할 세그먼트가 반드시 전체 세그먼트는 아니기 때문에 연결 목록 등을 사용하여 오버플로 레코드를 수용할 수 있어야 합니다. 그러나 연결된 목록 탐색은 많은 캐시 누락을 발생시키며 이는 PM 해시 테이블에 크게 불리합니다. 대신, Dash의 숨김 디자인을 활용하고 조절 가능한 숨김 버킷 수를 사용합니다. 각 세그먼트의 고정된 수의 숨김 버킷(예: 2개의 숨김 버킷) 외에도 숨김 버킷의 연결된 목록을 저장합니다. 오버플로 레코드를 수용하기 위해 숨김 버킷이 할당될 때마다 세그먼트 분할이 트리거됩니다. 이는 높은 삽입률에서 긴 오버플로 체인에 취약한 버킷을 한 번에 분할하는 전통적인(classic) 선형 해싱과 대조됩니다. Dash-LH는 더 큰 분할 단위(세그먼트)와 체인 단위(개별 레코드가 아닌 숨김 버킷)를 사용하여 체인 길이를 줄입니다 (따라서 포인터 추적 및 캐시 누락). 오버플로 메타데이터와 지문은 숨김 버킷 검색으로 인해 발생하는 성능 저하를 완화하는 데 더욱 도움이 됩니다. 전반적으로 섹션 6에서 볼 수 있듯이 Dash-LH는 현실적인 워크로드에서 거의 선형적인 확장성을 달성할 수도 있습니다.
📦 5.2 Hybrid Expansion - 하이브리드 확장
Dash-EH와 마찬가지로 더 나은 캐시 지역성을 위해 디렉터리 크기를 줄이는 것도 중요합니다.
어떤 디자인에서는 세그먼트 크기를 기하급수적으로 늘리는 이중 확장[17]을 사용합니다.
새 세그먼트를 할당하면 해시 테이블의 버킷 수가 두 배로 늘어납니다.
예를 들어 할당된 두 번째 세그먼트는 첫 번째 세그먼트 크기의 1배이고, 세 번째 세그먼트는 첫 번째 세그먼트보다 2배 더 큽니다.
이점은 디렉터리 크기가 매우 작아질 수 있고 종종 L1 캐시에도 적합하다는 것입니다.
그러나 새 세그먼트가 할당될 때마다 적재율이 절반으로 감소합니다.
공간 낭비를 줄이기 위해 이중 확장을 연기하고 이중 확장을 트리거하기 전에 먼저 여러 고정 크기 세그먼트로
해시 테이블을 확장합니다.
우리는 그러한 고정된 확장의 수를 보폭(stride)이라고 부릅니다. 그림 6은 예를 보여줍니다(보폭 = 4).
디렉터리 항목은 세그먼트 배열을 가리킬 수 있습니다.
처음 4개의 항목은 1개의 세그먼트 배열을 가리키고, 다음 4개의 항목은 2개의 세그먼트 배열을 가리키는 식입니다.
보폭이 클수록 더 큰 세그먼트 배열을 할당해도 적재율에 미치는 영향이 줄어듭니다.
그 결과 일반적으로 L1에 상주하는 디렉터리 크기가 매우 작습니다.
16KB 세그먼트를 사용하면 첫 번째 세그먼트 배열에는 64개의 세그먼트가 포함되며 보폭은 4이므로
1KB 미만의 디렉터리로 TB 수준 데이터를 인덱싱할 수 있습니다.
[17] Joshi, A.: Adaptive locking strategies in a multi-node data sharing environment. In: VLDB (1991)
다중 노드 데이터 공유 환경의 적응형 잠금 전략.
📦 5.3 Concurrency - 동시성
선형 해싱은 한 방향으로 확장되므로, 기본적으로 'Next' 포인터를 잠그면 분할이 직렬화됩니다.
임계 섹션(critical section)의 길이를 줄이기 위해, 우리는 실제로 세그먼트를 분할하지 않고 확장이 원자적으로 'Next'로
진행되는 LHlf [65]가 제안한 확장 전략을 채택합니다.
그런 다음 분할되어야 하는 세그먼트(세그먼트 메타데이터 영역에 표시됨)에 액세스하는 모든 스레드는 먼저 실제 분할 작업을 수행합니다.
결과적으로 여러 세그먼트 분할이 여러 스레드에 의해 병렬로 실행될 수 있습니다.
'Next' 포인터를 진행하기 전에, 액세스하는 스레드는 먼저 새 세그먼트에 대한 디렉토리 항목을 조사하여(probes)
해당 세그먼트 배열이 할당되었는지 확인합니다.
그렇지 않은 경우 세그먼트 배열을 할당하고 이를 디렉터리 항목에 저장합니다.
따라서 섹션 6에서 볼 수 있듯이 PM 할당자의 성능은 전체 성능에 영향을 미칠 수 있습니다.
Dash-LH는 변수 N을 사용하여 기본 테이블의 버킷 수를 계산합니다.
각 분할 라운드 후에 Next는 0으로 재설정되고 N은 증가하여 버킷 수가 두 배가 됨을 나타냅니다.
일관성 보장을 위해 N(32비트) 및 'Next'(32비트)를 원자적으로 업데이트할 수 있는 64비트 워드에 저장합니다.
[65] D. Zhang and P.-A. Larson. Lhlf: Lock-free linear hashing (poster paper).
잠금이 없는 선형 해싱(포스터 논문).
In Proceedings of the 17th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming,
병렬 프로그래밍의 원리와 실습 심포지엄
PPoPP ’12, pages 307–308, New York, NY, USA, 2012. ACM.
🟢 6. EVALUATION - 평가
이 섹션에서는 Dash를 평가하고 이를 두 가지 다른 최첨단 PM 해시 테이블인 CCEH[38] 및 레벨 해싱[68]과 비교합니다.
구체적으로 실험을 통해 다음 사항을 확인합니다.
• Dash 지원(Dash-enabled) 해시 테이블(Dash-EH 및 Dash-LH)은 실제 Optane DCPMM을 갖춘 멀티코어 서버에서 잘 확장됩니다.
• 버킷 로드 밸런싱 기술을 통해 Dash는 고성능을 유지하면서 높은 적재율을 달성할 수 있습니다.
• Dash는 재시작 시 필요한 최소한의 지속적인 작업량으로 즉시 복구를 제공하여 서비스 중단 시간을 줄입니다.
[38] M. Nam, H. Cha, Y. ri Choi, S. H. Noh, and B. Nam.
Write-optimized dynamic hashing for persistent memory.
영구 메모리를 위한 쓰기 최적화 동적 해싱
In 17th USENIX Conference on File and Storage Technologies (FAST 19), pages 31–44, Feb. 2019.
[68] P. Zuo, Y. Hua, and J. Wu.
Write-optimized and high-performance hashing index scheme for persistent memory.
영구 메모리를 위한 쓰기 최적화 및 고성능 해싱 인덱스 체계
In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 461–476, Oct. 2018.
📦 6.1 Implementation - 구현
우리는 충돌로부터 안전한(crash-safe) PM 관리 및 동기화를 위한 기본 요소를 제공하는 PMDK[20]를 사용하여 Dash-EH/LH를 구현했습니다.
이러한 기본 요소는 PM 데이터 구조를 구축하는 데 필수적이지만 오버헤드도 발생합니다.
예를 들어 PMDK 할당자는 확장성 문제를 나타내며 DRAM 할당자보다 훨씬 느립니다[31].
이러한 오버헤드는 이전 에뮬레이션 기반 작업에서는 무시되었지만 실제로는 무시할 수 없는 수준입니다.
우리는 평가 시 이를 고려합니다.
비교 대상인 다른 해시 테이블(CCEH [38] 및 레벨 해싱 [68])은 모두 DRAM 에뮬레이션을 기반으로 제안되었습니다.
원본 코드(2)와 PMDK를 사용하여 Optane DCPMM에서 실행되도록 포팅했습니다.
이전 작업[38]과 마찬가지로 캐시 누락을 줄이기 위해 작고 연속적인 메모리 영역(잠금 스트라이핑)[18]에 모든 잠금을 동일 위치에 배치하여
레벨 해싱을 최적화합니다.
이제 주요 구현 문제와 솔루션을 요약합니다.
💻 (2) Code downloaded from
1) https://github.com/DICL/CCEH (CCEH:Cacheline-Concious Extendible Hashing)
2) https://github.com/Pfzuo/Level-Hashing.
[20] Intel. PMDK: Persistent Memory Development Kit. 2018.
http://pmem.io/pmdk/libpmem/ (영구 메모리 개발 키트)
[31] Shute, J., Vingralek, R., Samwel, B., Handy, B., Whipkey, C., Rollins, E., Oancea, M.
a distributed sql database that scales. In: VLDB (2013)
확장 가능한 분산 SQL 데이터베이스
⬜️ Crash Consistency - 충돌 일관성
Dash는 세그먼트 분할을 위해 PMDK(Persistent Memory Development Kit) 트랜잭션을 사용합니다.
이를 통해 Dash는 안전한 원자 할당을 보장하면서 낮은 수준의 세부 정보를 처리할 필요가 없습니다.
세그먼트 분할 중 정전으로 인해 PM이 누출(leak)될 수 있는 CCEH 코드의 일관성 문제를 발견했습니다.
PMDK 트랜잭션을 사용하여 이 문제를 해결했습니다.
또한 복구 시 자동으로 잠금 해제되는 PMDK 읽기-쓰기(reader-writer) 잠금을 사용하도록 CCEH 및 레벨 해싱을 조정했습니다.
⬜️ Persistent Pointers - 영구 포인터
CCEH와 레벨 해싱은 모두 DRAM 에뮬레이션을 기반으로 하는 표준 8바이트 포인터를 가정하는 반면,
일부 시스템은 PM에 16바이트 포인터를 사용합니다.
긴(Long) 포인터는 메모리 레이아웃을 깨고 원자 명령을 사용하기 어렵게 만듭니다.
PM에서 8바이트 포인터를 사용하기 위해 PMDK를 확장하여 PM이 여러 실행에서 동일한 가상 주소 범위에 매핑되도록 했습니다
(mmap에서 MAP_FIXED_NOREPLACE(3)를 사용하고 커널에서 mmap_min_addr 설정).
여기에서 실험된 모든 해시 테이블은 이 접근 방식을 사용합니다.
(3) 또한 MAP_FIXED_NOREPLACE가 작동하려면 MAP_SHARED_VALIDATE를 MAP_SHARED로 바꿔야 했습니다.
자세한 내용은 코드 저장소(ur code repository)에 나와 있습니다.
⬜️ Garbage Collection - 메모리 회수
우리는 Dash를 위한 범용(general-purpose) 시대 기반(epoch-based) PM 회수(reclamation) 메커니즘을 구현했습니다.
또한 CCEH의 오픈 소스 구현을 통해 스레드가 잠금을 획득하지 않고도 디렉터리에 액세스할 수 있으며,
이는 (디렉터리 두 배 또는 절반으로 인해) 해제된 메모리에 대한 액세스를 허용할 수 있다는 점을 관찰했습니다.
우리는 동일한 시대 기반 회수 접근 방식으로 이 문제를 해결했습니다.
📦 6.2 Experimental Setup - 실험 설정
우리는 Intel Xeon Gold 6252 2.1GHz, AppDirect 모드의 768GB Optane DCPMM
(6개 채널 모두에 6×128GB DIMM), 192GB DRAM(6×32GB DIMM)을 갖춘 서버에서 실험을 실행했습니다.
CPU에는 24개 코어(48개 하이퍼스레드 hyperthreads)와 35.75MB의 L3 캐시가 있습니다.
서버는 커널 5.5.3 및 PMDK 1.7이 포함된 Arch Linux를 실행합니다.
모든 코드는 모든 최적화가 활성화된 GCC 9.2를 사용하여 컴파일됩니다.
스레드는 물리적 코어에 고정되어 있습니다.
![]()
Rocky Linux version - Linux kernel version 비교 (Update: 2025년 10월 18일)
✅ Rocky Linux 8.4 ~ 8.10 - kernel ver 4.19.0
✅ Rocky Linux 9.0 ~ 9.6 - kernel ver 5.14.0
✅ Rocky Linux 10.0 - kernel ver 6.12.0
⬜️ Parameters - 매개변수
공정한 비교를 위해 우리는 CCEH와 레벨 해싱이 원본 논문과 동일한 매개변수를 사용하도록 설정했습니다.
자체 테스트에서는 이러한 매개변수가 전반적으로 최고의 성능과 적재율을 제공하는 것으로 나타났습니다.
레벨 해싱은 128바이트(캐시라인 2개) 버킷을 사용합니다.
CCEH는 16KB 세그먼트와 64바이트(캐시라인 1개) 버킷을 사용하며 탐색 길이는 4입니다.
Dash-EH와 Dash-LH는 256바이트(캐시라인 4개) 버킷과 16KB 세그먼트를 사용합니다.
각 세그먼트에는 2개의 숨김 버킷이 있으므로 버킷당 4개의 오버플로 지문 슬롯이 있으면 충분하므로
오버플로 카운터가 양수인 경우가 거의 없습니다.
Dash-LH는 보폭 8의 하이브리드 확장을 사용하며 첫 번째 세그먼트 배열에는 64개의 세그먼트가 포함됩니다.
⬜️ Benchmarks- 벤치마크
우리는 마이크로벤치마크(microbenchmark)를 사용하여 각 해시 테이블을 스트레스 테스트합니다.
검색 작업을 위해 긍정 검색과 부정 검색을 실행합니다.
후자는 존재하지 않는 키를 구체적으로 탐색합니다.
달리 지정하지 않는 한 모든 실행에 대해 1천만 개의 레코드가 있는 해시 테이블을 미리 로드한 다음
1억 9천만 개의 삽입(삽입 전용 벤치마크로)을 하고,
2억 레코드 해시 테이블에 1억 9천만 번의 "긍정적 검색"/"부정 검색"/"삭제 작업"을 연속적으로 실행합니다.
모든 해시 인덱스에 대해 우리는 빠르고 고품질 해시를 제공하는 것으로 알려진 GCC의 std::_Hash_bytes(Murmur 해시 기반)를
해시 함수로 사용합니다.
다른 작업과 유사하게 작업 부하에 균일하게 분산된 임의 키를 사용합니다.
또한 Zipfian 배포(다양한 왜곡 포함)에서 편향된 작업 부하를 테스트한 결과 모든 작업이 바로 가기 키의 더 높은 캐시 적중률을 통해
더 나은 성능을 달성했으며 해시 값이 대체로 균일하게 분포되기 때문에 경합이 거의 없음을 확인했습니다.
공간 제한으로 인해 편향된 작업 부하에 대한 자세한 결과는 생략합니다.
고정 길이 키 실험의 경우 키와 값은 모두 8바이트 정수입니다.
가변 길이 키 실험의 경우 16바이트 키와 8바이트 값(포인터)을 사용합니다.
가변 길이 키는 테스트 전에 벤치마크에 의해 사전 생성됩니다.
✅ std::_Hash_bytes는 C++ 표준 라이브러리 구현에서 내부적으로 사용되는 함수 또는 유틸리티입니다.
이는 사용자가 직접 사용하는 것이 아니라, 표준 라이브러리의 일부로서 해시 관련 작업을 수행하기 위해 존재합니다.
std::_Hash_bytes는 주어진 바이트 배열의 해시 값을 계산하는 기능을 합니다.
이는 다양한 타입의 데이터를 동일한 방식으로 해싱하기 위해 사용됩니다.
📦 6.3 Single-thread Performance - 단일 스레드 성능
각 해시 테이블의 기본 동작을 이해하기 위해 단일 스레드 성능부터 시작합니다.
✅ fixed-length keys - 고정 길이 키
We first consider a read-only workload with fixed-length keys.
Read-only results provide an upper bound performance on the hash tables since
no modification is done to the data structure.
They directly reflect the underlying design’s cache efficiency and concurrency control overhead.
먼저 고정 길이 키를 사용하는 읽기 전용 워크로드를 고려합니다.
읽기 전용 결과는 데이터 구조가 수정되지 않으므로 해시 테이블에 대한 상한(上限,upper bound) 성능을 제공합니다.
이는 기본 설계의 캐시 효율성과 동시성 제어 오버헤드를 직접적으로 반영합니다.
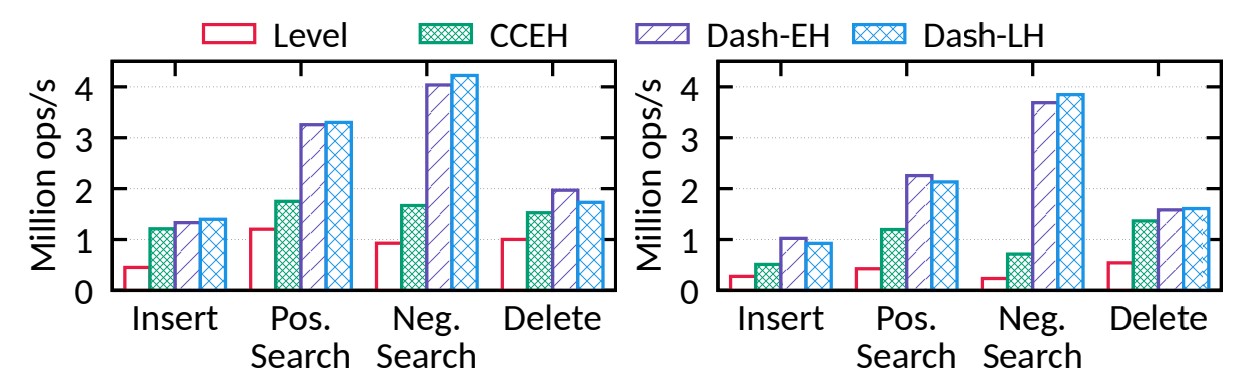
• Positive search - 긍정 검색
그림 7에서 볼 수 있듯이 Dash-EH는 긍정적 검색에서 CCEH/레벨 해싱을 1.9배/2.6배 능가할 수 있습니다.
Dash-LH와 Dash-EH는 PM 쓰기를 줄이는 제한된(with bounded) PM 액세스 및 경량 동시성 제어(lightweight concurrency control)와
함께 동일한 빌딩 블록을 사용하기 때문에 유사한 성능을 달성했습니다.
• Negative search - 부정 검색
부정 검색의 경우 Dash 변형은 CCEH/레벨 해싱보다 2.4배/4.4배 더 빠른 속도로 더 큰 개선을 이루었습니다.
섹션 6.5에서 볼 수 있듯이 이는 PM 액세스를 크게 줄이는 지문(fingerprint) 및 오버플로 메타데이터(overflow metadata)에 기인합니다.
• Insert - 삽입
삽입의 경우 Dash와 CCEH는 비슷한 성능(수준(level) 해싱의 ~2.5배)을 달성합니다.
CCEH는 Dash보다 삽입당 캐시라인 플러시가 하나 더 적지만 Dash의 버킷 로드 밸런싱 전략은
세그먼트 분할을 줄여 성능을 높이고 적재율을 개선합니다.
할당 비트맵이 없으면 CCEH는 빈 슬롯을 나타내기 위해 예약된 값(예: '0')이 필요합니다.
이 디자인은 애플리케이션에 추가적인 제한을 부과합니다.
Dash는 메타데이터를 사용하여 이를 방지합니다.
레벨 해싱은 더 많은 PM 읽기와 빈번한 "잠금(lock)"/"잠금 해제(unlock)" 작업으로 인해 훨씬 낮은 성능을 나타냈습니다.
또한 많은 캐시라인 플러시를 발생시키는 전체 테이블 재해싱이 필요합니다.
• Delete - 삭제
For deletes, Dash outperforms CCEH/level hashing by 1.2×/1.9× because of reduced cache misses.
삭제의 경우 Dash는 캐시 누락이 줄어들기 때문에 CCEH/레벨 해싱보다 1.2×/1.9× 성능이 뛰어납니다.
✅ variable-length keys - 가변 길이 키
Dash의 이점은 가변 길이 키에서 더욱 두드러집니다.
• Positive/Negative search - 긍정/부정 검색
그림 7에서 볼 수 있듯이 Dash-EH/LH는 긍정적 검색에 대한 CCEH/레벨 해싱보다 2배/5배 빠릅니다.
부정 검색의 차이는 훨씬 더 극적입니다(5배/15배).
이번에도 이 결과는 지문의 효율성을 보여줍니다.
모든 해시 테이블은 더 긴(> 8바이트) 키에 대한 포인터를 저장하므로 액세스하는 스레드는 키를 로드하기 위해
포인터를 역참조(dereference)해야 하며, 이는 캐시 누락의 주요 원인입니다.
지문은 이러한 간접 참조를 효과적으로 줄입니다.
키를 직접 쿼리(검색/삭제)하거나 고유성(uniqueness) 확인(삽입)이 필요하기 때문에 모든 작업(operations)은 이 기술의 이점을 누릴 수 있습니다.
• Insert/Delete - 삽입/삭제
For the same reason, Dash-EH outperforms CCEH/level hashing by 2.0×/3.7× for insert, and 1.2×/2.9× for delete.
같은 이유로 Dash-EH는 삽입 시 2.0배/3.7배, 삭제 시 1.2배/2.9배만큼 CCEH/레벨 해싱보다 성능이 뛰어납니다.
📦 6.4 Scalability - 확장성
우리는 개별 작업과 20%의 삽입 작업과 80%의 검색 작업으로 구성된 혼합 작업 부하를 모두 테스트합니다.
혼합 워크로드의 경우 검색 작업에서 실제 데이터에 액세스할 수 있도록 6천만 개의 레코드가 포함된 해시 테이블을 미리 로드합니다.
그림 8은 다양한 스레드 수와 고정 길이 키에 따라 각 해시 테이블이 어떻게 확장되는지 보여줍니다.
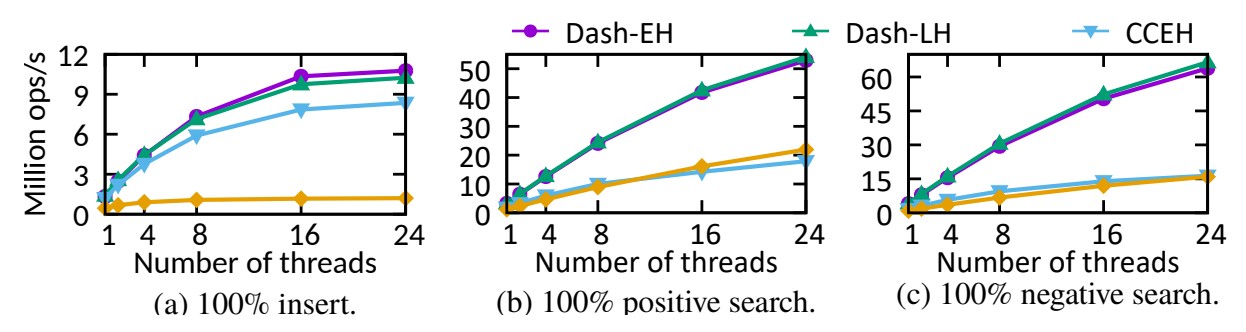
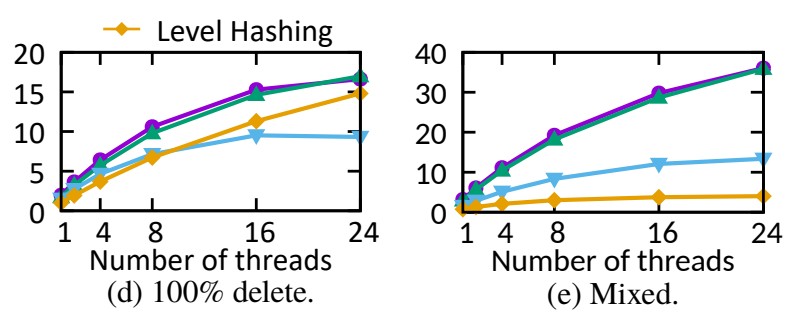
그림 8: 다양한 스레드 수, 8바이트 키 및 8바이트 값을 사용하여 다양한 워크로드에서 성능(처리량)
• Insert - 삽입
삽입의 경우 레벨 해싱은 주로 전체 테이블 재해싱으로 인해 최악의 확장성을 나타냅니다.
이는 PM에서 시간이 많이 걸리고 동시 작업을 차단합니다.
지문 및 버킷 로드 밸런싱을 통해 Dash는 고유성 검사를 신속하게 완료하고 PM 액세스 및 PM 할당자와의
상호 작용을 줄여 더 적은 수의 SMO를 트리거합니다.
삽입이 본질적으로 많은 무작위 PM 쓰기를 나타내기 때문에 Dash-EH나 Dash-LH는 선형적으로 확장되지 않지만
Dash는 삽입 작업에 대한 CCEH/레벨 해싱보다 최대 1.3배/8.9배 더 빠른 확장 가능한 솔루션입니다.
• Search - 검색
검색 작업의 경우 그림 8(b–c)는 Dash-EH/LH에 대한 선형에 가까운 확장성을 보여줍니다.
CCEH는 주로 읽기 전용 워크로드(읽기 잠금 획득/해제)에 대해서도 대량의 PM 쓰기를 발생시키는 비관적 잠금을
사용하기 때문에 뒤쳐집니다.
레벨 해싱은 비슷한 디자인을 사용하지만 잠금 스트라이핑[18]은 모든 잠금을 CPU 캐시에 맞출 수 있게 만듭니다.
따라서 레벨 해싱은 CCEH보다 단일 스레드 성능이 낮지만 다중 스레드에서는 여전히 CCEH와 유사한 성능을 달성합니다.
• Delete - 삭제
24개 스레드 규모의 Dash-EH, Dash-LH, CCEH 및 레벨 해싱에서 작업을 삭제하고
단일 스레드 버전에 비해 각각 8.4배, 9.8배, 6.1배 및 14.7배 향상됩니다.
• 24개 스레드의 혼합 워크로드(mixed workload)
Dash는 CCEH/레벨 해싱보다 2.7배/9.0배 더 뛰어납니다.
• variable-length key - 가변 길이 키
가변 길이 키를 사용하는 워크로드에
대해 유사한 경향(그러나 Dash-EH/LH와 CCEH/레벨 해싱 간의 간격이 넓어짐)을 관찰했습니다.
(그래프틑 표시하지 않았음)
다음 섹션에서는 Dash의 각 디자인이 성능에 어떤 영향을 미치는지 논의합니다.
📦 6.5 Fingerprinting and Overflow Metadata - 지문과 오버플로 메타데이터
✅ Effect of fingerprinting - 지문 효과
지문은 PM 액세스를 크게 줄여 Dash가 PM에서 좋은 성능을 발휘하고 확장할 수 있는 주요 이유입니다.
우리는 지문 유무에 따른 Dash-EH를 비교하여 그 효과를 정량화합니다.
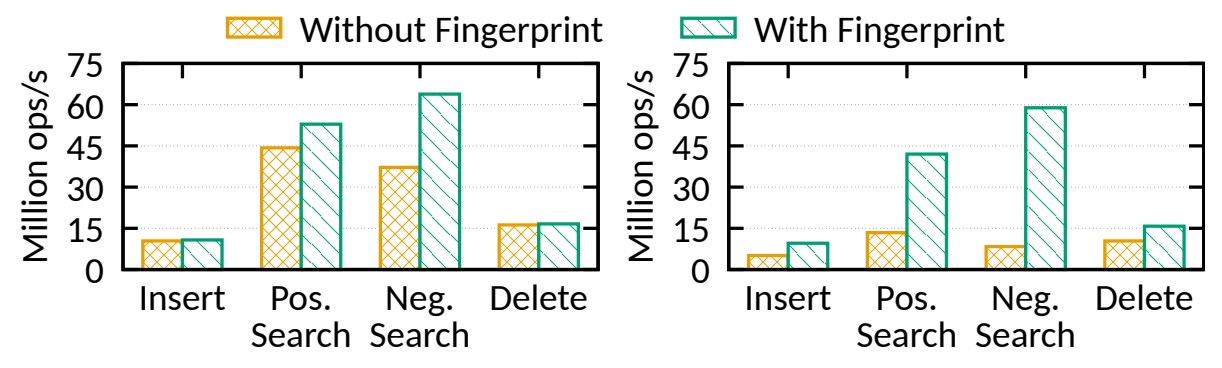
그림 9: 버킷의 지문 효과: 고정 키(왼쪽) 및 가변 길이 키(오른쪽)
그림 9는 24개 스레드에서의 "삽입"/"긍정 검색"/"부정 검색"/"삭제"에 처리량 결과를 보여줍니다.
• 고정 길이 키(지문 사용): 1.04/1.19/1.72/1.02배 향상됩니다.
• 가변 길이 키(지문 사용): 1.88/3.13/7.04/1.52배 향상됩니다.
✅ Effect of overflow metadata - 오버플로 메타데이터 효과
섹션 4.3에서 소개된 것처럼 Dash는 오버플로 메타데이터를 사용하여 검색 작업을 조기에 중지하여(early-stop)
PM 액세스를 절약할 수 있습니다.
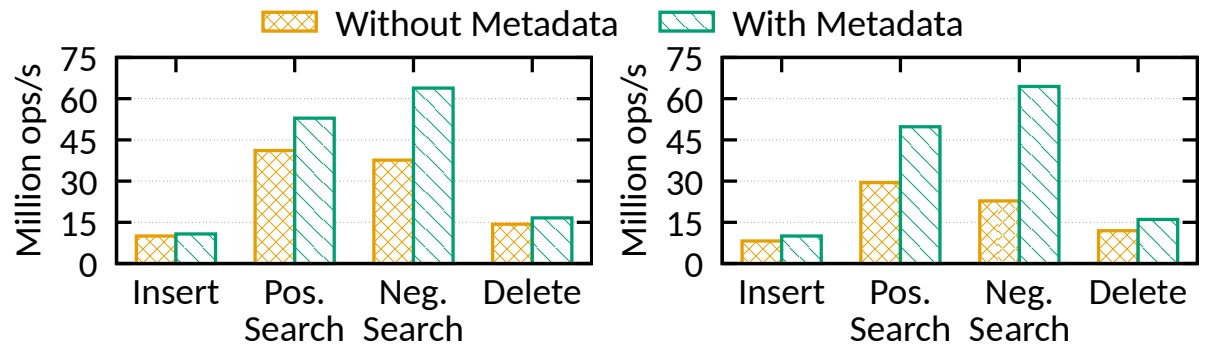
그림 10: 오버플로 메타데이터(24개 스레드)의 효과: 고정 길이 키이고 숨김 버킷이 세그먼트당 2개(왼쪽) 및 4개(오른쪽)
그림 10은 다양한 수의 숨김 버킷이 있는 24개 스레드에서의 효율성을 보여줍니다.
2개의 숨김 버킷이 있는 Dash-EH는 "삽입"/"긍정 검색"/"부정 검색"/"삭제"에 대해 기준(메타데이터 없음)보다
1.07/1.29/1.70/1.16배 성능이 뛰어납니다.
더 많은 숨김 버킷을 추가하면 오버플로 메타데이터 없이 검색 성능이 약 25% 감소합니다.
그러나 오버플로 메타데이터를 사용하면 숨김 버킷을 실제로 검색하지 않고도 오버플로 메타데이터를 확인한 후
부정 검색 작업을 조기에 중지할 수 있으므로 성능이 안정적으로 유지됩니다.
📦 6.6 Load Factor - 적재율
⬜️ 이제 선형 탐색(linear probing), 균형 잡힌 삽입(balanced insert), 치환(displacement) 및 예비(stashing)거 적재율를
어떻게 향상시키는지 연구합니다.
먼저 크기가 다른 한 세그먼트의 최대 적재율을 측정합니다.
더 큰 세그먼트를 사용하면 적재율이 줄어들 수 있지만, 디렉터리 크기를 줄여 성능을 향상시킬 수 있습니다.
실제 시스템은 이러한 균형을 유지해야 합니다.
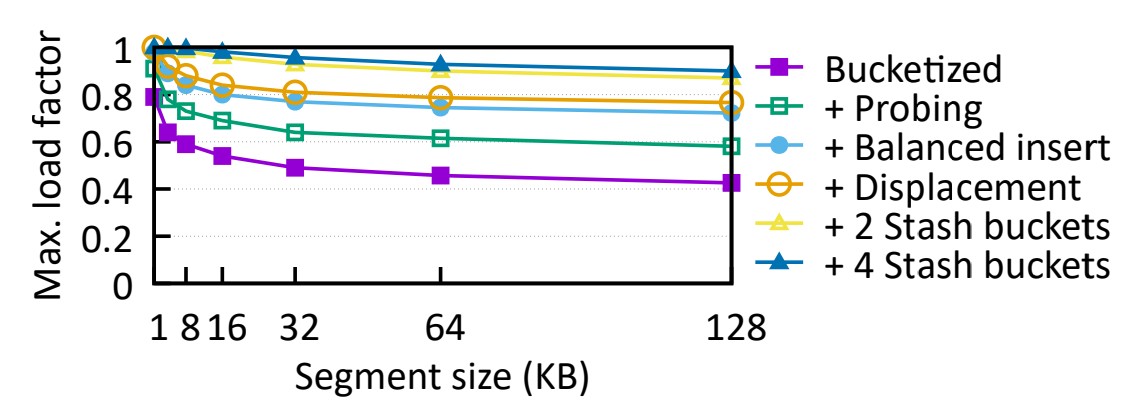
그림 11: 다른 기술을 추가한 후 최대 적재율(세그먼트가 채워지는 비율)
⬜️ 그림에서 "Bucketized"는 다른 기술이 없는 가장 간단한 세분화(segmentation) 설계를 나타냅니다.
세그먼트는 1KB 세그먼트에서 최대 80%까지 채워질 수 있지만 세그먼트 크기가 128KB로 증가함에 따라
점차적으로 최대 약 40%까지 채워집니다.
버킷 탐색을 하나만 추가하면("+Probing") 128KB 세그먼트 미만의 로드율이 ~20% 증가합니다.
균형 잡힌 삽입과 치환은 적재율을 약 20% 더 향상시킬 수 있습니다.
예비(stashing) 버킷를 사용하면 1~16KB 세그먼트에 대해 적재율을 100%에 가깝게 유지합니다.
Dash는 이러한 모든 기술을 결합하여 대규모 세그먼트를 사용하는 바닐라(vanilla) 세분화보다 두 배 이상의 적재율을 달성합니다.
⬜️ 다양한 설계를 보다 현실적으로 비교하기 위해, 일련의 삽입 후 적재율이 어떻게 변하는지 관찰합니다.
빈 해시 테이블(적재율 0)로 시작하여 해시 테이블에 다양한 수의 레코드가 추가된 후 로드 계수를 측정합니다.
그림 12에서 볼 수 있듯이 CCEH의 적재율(y축)은 35%에서 43% 사이에서 변동합니다.
왜냐하면 CCEH는 분할을 트리거하기 전에 4번의 캐시라인 탐색만 수행하기 때문입니다.
섹션 4.3에서 언급한 것처럼 긴 탐색 길이는 성능을 희생하면서 적재율을 증가시키지만 짧은 탐색 길이는 조기 분할로 이어집니다.
CCEH에 비해 대시 및 레벨 해싱은 효과적인 적재율 개선 기술로 인해 높은 적재율을 달성할 수 있습니다.
"디핑(dipping)"은 "세그먼트 분할"/"테이블 재해싱"이 발생하고 있음을 나타냅니다.
또한 Dash-EH/LH(2)로 표시된 2개의 숨김 버킷을 사용하면 최대 80%의 적재율을 달성하는 반면
Dash-EH(4)에서 4개의 숨김 버킷을 사용하는 수치는 90%로 레벨 해싱과 일치합니다.
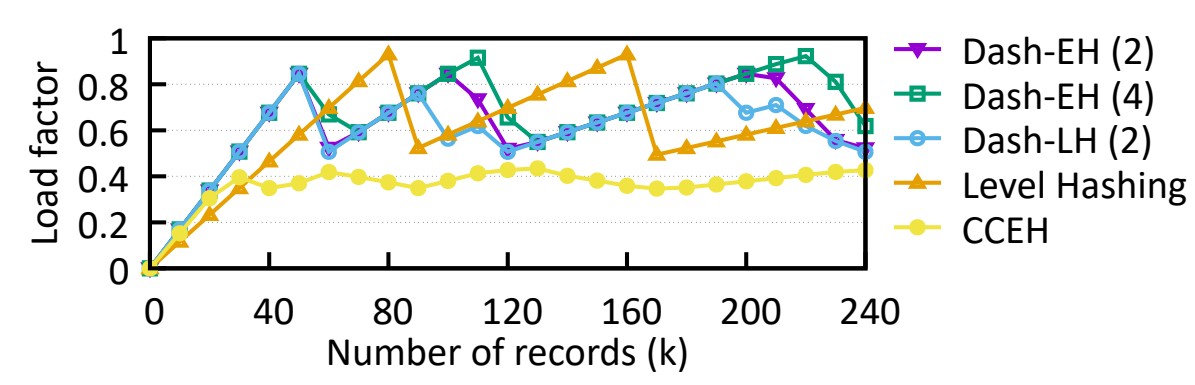
그림 12: 해시 테이블에 삽입된 항목 수에 대한 다양한 해싱 방식의 적재율입니다.
디핑(dipping): 세그먼트 분할 후 적재율이 뚝 떨어졌다가, 재해싱과 삽입이 되면서 적재율이 다시 올라가는 현상.
📦 6.7 Impact of Concurrency Control - 동시성 제어의 영향
섹션 4.4에서 설명한 것처럼 PM 데이터 구조는 전통적인 비관적 잠금보다 Dash의 낙관적 잠금과 같은 경량 접근 방식을 선호합니다.
그림 13은 (부정적 및 긍정적) 검색 워크로드에서 Dash-EH의 비관적 잠금(읽기-쓰기 스핀잠금)과 낙관적 잠금을 비교하여
이 점을 실험적으로 검증합니다.
스핀록 기반 버전은 읽기 잠금을 조작하는 데 필요한 추가 PM 쓰기로 인해 확장이 잘 되지 않습니다.
우리는 DRAM에 대해 동일한 실험을 반복한 결과 둘 다 잘 확장될 수 있음을 발견했습니다.
이는 이전 에뮬레이션 기반 연구에서 생략되었거나 발견하기 쉽지 않았던 또 다른 중요한 발견을 포착합니다.
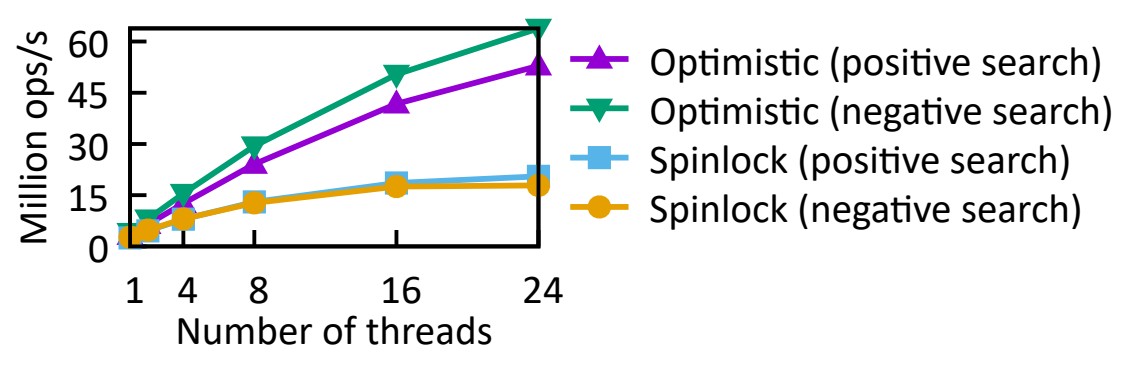
그림 13: Scalability under different concurrency control strategies
(reader-writer spinlocks vs. optimistic locking in Dash-EH).
다양한 동시성 제어 전략(읽기-쓰기 스핀록(회전잠금) 대 Dash-EH의 낙관적 잠금)에 따른 확장성.
📦 6.8 Recovery - 복구
⬜️ 복구 시간(ms)과 데이터 크기 설명
서비스 중단 시간(downtime)을 줄이기 위해 충돌(crash) 또는 완전 종료(clean shutdown) 후 영구 해시 테이블을 즉시 복구하는 것이 바람직합니다.
먼저 특정 수의 레코드를 로드한 다음 프로세스를 종료하고 시스템이 들어오는 요청을 처리하는 데 필요한 시간을 측정하여
복구 시간을 테스트합니다.
표 1은 각 해시 테이블이 다양한 데이터 크기로 들어오는 요청을 처리할 준비를 하는 데 필요한 시간을 보여줍니다.
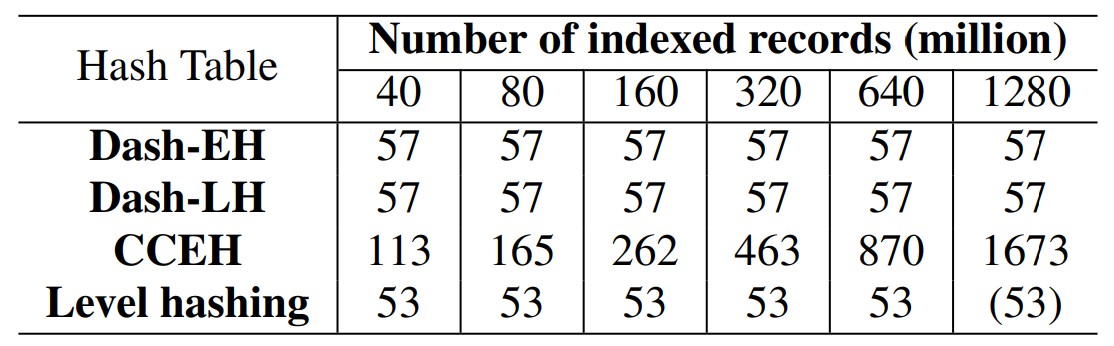
표 1: 복구 시간(ms)과 데이터 크기 비교. CCEH의 복구 시간은 데이터 크기에 따라 달라집니다.
레벨 해싱과 대시의 경우 둘 다 다시 시작할 때 고정된 양의 작업이 필요하기 때문에 일정하게 유지됩니다.
Dash-EH/LH 및 레벨 해싱의 복구 시간은 1초 미만 수준이며 데이터 크기 증가에 따라 확장되지 않아 효과적으로 즉시 복구가 가능합니다. ;
Dash-EH/LH의 경우 필요한 유일한 작업은 해시 테이블을 뒷받침하는 PM 풀을 연 다음 두 변수의 값을 읽고 설정하는 것입니다. ;
1280M 데이터의 경우 레벨 해싱에는 PMDK 할당자에서 허용하는 최대값(15.998GB)보다 큰 할당 크기가 필요합니다. ;
그러나 복구 중에 PM 풀을 여는 데에도 고정된 양의 작업만 필요하므로 더 큰 데이터 크기에서도 복구 시간은 동일하게(53ms)
유지될 것으로 예상됩니다. ;
CCEH의 복구 시간은 복구 시 전체 디렉터리를 검색해야 하므로 인덱싱된 데이터의 크기에 선형적으로 비례합니다. ;
데이터 크기가 증가하면 디렉터리 크기도 늘어나 복구에 더 많은 시간이 필요합니다.
⬜️ 스레드 개수에 따른 복구 시간 설명
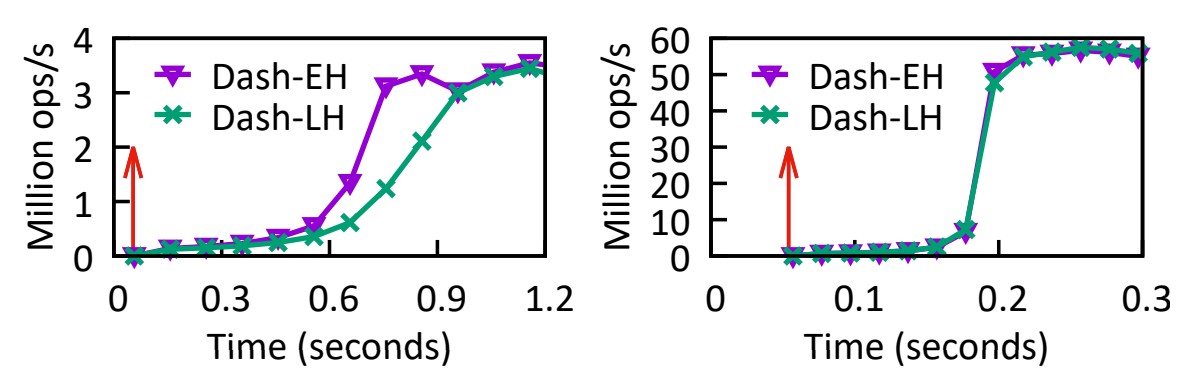
그림 14: 1개의 스레드(왼쪽)와 24개의 스레드(오른쪽)로 재시작할 때의 다른 시간대의 처리량입니다.
Dash의 지연 복구는 런타임 성능에 영향을 미칠 수 있습니다.
우리는 DashEH/LH가 즉시 복구된 후 시간 경과에 따른 처리량을 기록하여 이 효과를 측정합니다.
해시 테이블에는 4천만 개의 레코드가 미리 로드되어 있습니다.
그런 다음 순수 삽입 워크로드를 실행하는 동안 프로세스를 종료하고 해시 테이블을 다시 시작한 다음
긍정적인 검색 작업을 실행하여 시간에 따른 처리량 변화를 관찰합니다.
결과는 그림 14에 나타나 있습니다. 빨간색 화살표는 Dash가 다시 온라인 상태가 되어 새로운 요청을 처리할 수 있는 시점을 나타냅니다.
처음에는 처리량이 상대적으로 낮습니다.
그림 14(왼쪽)의 스레드 하나에서 0.1–0.3 Mops/s,
그림 14(오른쪽)의 24개 스레드에서 0.6 Mops/s입니다.
더 많은 스레드를 사용하면 여러 스레드가 서로 다른 세그먼트에 도달하고 메타데이터 재구축 작업을 수행하거나
SMO를 병렬로 완료할 수 있으므로 처리량을 더 일찍 정상으로 되돌리는 데 도움이 될 수 있습니다.
처리량은 24개 스레드에서 0.2초 만에 정상으로 돌아오는데, 1개 스레드 미만에서는 0.9초가 걸립니다.
📦 6.9 Impact of PM Software Infrastructure - PM 소프트웨어 인프라의 영향
PM 프로그래밍 인프라는 페이지 오류 및 캐시라인 플러시와 같은 이유로 인해 큰 오버헤드가 될 수 있는 것으로 나타났습니다.
두 개의 할당자(PMDK 대 사용자 정의 할당자)와 두 개의 Linux 커널 버전(5.2.11 대 5.5.3)에서
섹션 6.4의 동일한 삽입 벤치마크를 실행하여 그 영향을 수량화합니다.
우리의 맞춤형 할당자는 PM을 사전 할당하고 사전 오류를 발생시켜 런타임 시 페이지 오류를 제거합니다.
실용적이지는 않지만 PM 할당자의 영향을 정량화할 수 있습니다. 다른 실험에서는 사용되지 않습니다.
그림 15(왼쪽)에서 볼 수 있듯이 Dash-EH는 할당 크기(단일 세그먼트, 16KB)가 고정되어 있고 크지 않기 때문에
다양한 커널 버전에서 할당자 성능에 크게 민감하지 않습니다.
그러나 그림 15(오른쪽)의 Dash-LH는 커널 5.2.11에서 PMDK 할당자를 사용하여 매우 낮은 성능을 나타냈습니다(5.5.3 미만 수치의 약 25%).
그 이유는 대규모 PM 할당이 2MB 대용량(huge) 페이지(PMDK 기본값) 대신 4KB 페이지를 사용하도록 대체할 수 있는
커널 5.2.11의 버그(4) 때문이었습니다.
선형 해싱은 본질적으로 분할 작업 중에 여러 스레드가 PM 할당을 위해 경쟁해야 하고
느린 PM 할당은 동시 요청을 차단할 수 있기 때문에 이로 인해 Dash-LH에 가장 큰 영향을 미치는
더 많은 페이지 오류 및 OS 스케줄러 활동이 발생했습니다.
페이지 결함 수가 증가하면 복구 성능에도 영향을 미쳤습니다.
예를 들어, 1억 6천만 개의 레코드 미만에서는 복구하는 데 표 1의 숫자보다 커널 5.2.11에서 CCEH ~10배 더 오래 걸렸습니다.
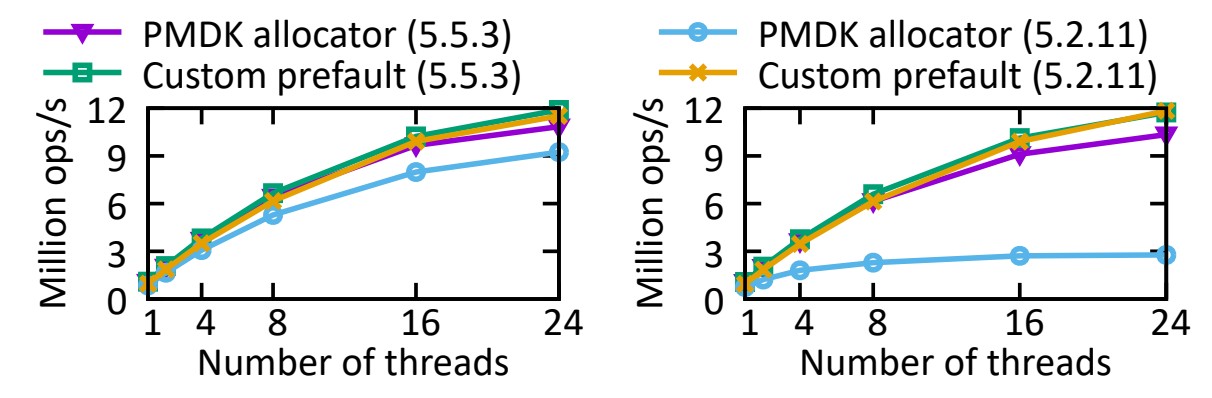
그림 15: PM 할당자와 OS 지원이 Dash-EH(왼쪽) 및 Dash-LH(오른쪽)에 미치는 영향.
이러한 결과는 PM 프로그래밍의 복잡성을 강조하며 사용자 공간(예: 할당자) 및 OS 지원을 모두 포함하는
신중한 설계 및 테스트를 요구합니다.
실무자와 연구자들이 PM 데이터 구조를 구축하기 위해 PM 프로그래밍 스택에 의존하기 시작하면서
PM 프로그래밍 스택이 빠르게 발전하고 있기 때문에 우리는 이것이 필요하다고 믿습니다.
(4) Caused by a patch discussed at lkml.org/lkml/2019/7/3/95,
fixed by patch at lkml.org/lkml/2019/10/19/135 (5.3.8 and newer).
More details are available in our code repository
lkml.org/lkml/2019/7/3/95에서 논의된 패치로 인해 발생하고
lkml.org/lkml/2019/10/19/135(5.3.8 이상)의 패치로 수정되었습니다.
자세한 내용은 코드 저장소에서 확인할 수 있습니다.
🟢 7. RELATED WORK - 관련 논문 소개
Dash는 이전의 인메모리 및 PM 기반 해시 테이블, 트리 구조 및 PM 프로그래밍 도구의 많은 기술을 기반으로 구축되었습니다.
⬜️ In-Memory Hash Indexes - 인메모리 해시 인덱스
섹션 2.2에서는 확장 가능한 해싱과 선형 해싱을 다루었으므로 여기서는 반복하지 않습니다.
Cuckoo(뻐꾸기) 해싱은 치환을 통해 높은 메모리 효율성을 달성합니다.
레코드는 두 개의 독립적인 해시 함수를 사용하여 계산된 두 버킷 중 하나에 삽입될 수 있습니다.
두 버킷이 모두 가득 차면 무작위로 선택된 레코드가 대체(alternative) 버킷으로 제거되어(evicted)
새 레코드를 위한 공간을 확보합니다.
제거된 레코드도 같은 방식으로 삽입됩니다.
MemC3은 전역 잠금이 있는 버전 카운터를 사용하는 단일 작성자, 다중 읽기 낙관적 동시 뻐꾸기(cuckoo) 해싱 체계를 제안합니다.
MemC3은 또한 가변 길이 키에 대한 포인터 액세스 오버헤드를 줄이기 위해 지문과 유사한 태깅 기술을 사용합니다.
FASTER는 각 포인터의 사용되지 않은 상위 16비트에 태그를 저장하여 이를 더욱 최적화합니다.
libcuckoo는 MemC3을 확장하여 멀티쓰기(multi-writer)를 지원합니다.
뻐꾸기 해싱 접근 방식은 연속적인 뻐꾸기 치환로 인해 많은 메모리 쓰기가 발생할 수 있습니다.
Dash는 탐색 횟수를 제한하고 낙관적 잠금을 사용하여 PM 쓰기를 줄입니다.
⬜️ Static Hashing on PM - PM의 정적 해싱
대부분의 작업은 PM 쓰기를 줄이고 적재율을 개선하며 전체 테이블 재해싱 비용을 줄이는 것을 목표로 합니다.
일부 제안에서는 기본 테이블에 삽입할 수 없는 레코드를 저장하기 위해 기본 테이블과 추가 수준의 숨김으로 구성된
다단계 디자인을 사용합니다.
PFHT[10]는 쓰기를 줄이기 위해 단 한 번의 치환만 허용하는 2단계 방식입니다.
연결된 목록을 사용하여 숨김(stash)의 충돌을 해결합니다. 이로 인해 검색 중에 많은 캐시 누락이 발생할 수 있습니다.
Path hashing[67]은 검색 비용을 낮추기 위해 숨김을 반전된 완전한 이진 트리로 구성합니다.
Level hashing[68]은 검색 비용을 최대 4개의 버킷으로 제한하는 2레벨 체계입니다.
크기를 조정하면 하위 수준이 상위 수준 테이블의 4배 크기로 다시 해시되고 이전 최상위 수준이 새로운 하위 수준이 됩니다.
뻐꾸기 해싱에 비해 조회 중에 탐색에 필요한 버킷 수가 두 배로 늘어납니다.
Dash는 또한 적재율을 향상시키기 위해 숨김를 사용하지만, 대부분의 검색 작업은 오버플로 메타데이터 덕분에 두 개의
버킷에만 액세스하면 됩니다.
⬜️ Dynamic Hashing on PM - PM의 동적 해싱
CCEH[38]는 전체 테이블 재해싱을 방지하는 충돌 일관성 확장형 해싱 체계입니다[12].
검색 효율성을 높이기 위해 탐색 길이를 4개의 캐시라인으로 제한하지만 이로 인해 적재율이 낮아지고
세그먼트 분할이 자주 발생할 수 있습니다.
CCEH의 복구 프로세스에서는 다시 시작할 때 디렉터리를 검색해야 하므로 즉시 복구가 희생됩니다.
이전 제안에서는 잠금을 조작할 때 과도한 PM 쓰기로 인해 쉽게 병목 현상이 발생할 수 있는 비관적 잠금 [38, 68]을
사용하는 경우가 많습니다.
결과적으로 충돌 없는 검색 작업도 확장할 수 없습니다.
NVC-hashmap[51]은 분할 순서 목록[52]을 기반으로 하는 잠금이 없는 영구 해시 테이블입니다.
잠금 없는 설계로 PM 쓰기를 줄일 수 있지만 구현하기는 어렵습니다.
연결된 목록 디자인에서는 많은 캐시 누락이 발생할 수도 있습니다.
Dash는 PM 쓰기를 줄이고 검색 작업을 위한 선형에 가까운 확장성을 허용하는 낙관적 잠금을 통해 이러한 문제를 해결합니다.
[38] M. Nam, H. Cha, Y. ri Choi, S. H. Noh, and B. Nam.
Write-optimized dynamic hashing for persistent memory.
영구 메모리를 위한 쓰기 최적화 동적 해싱
In 17th USENIX Conference on File and Storage Technologies (FAST 19), pages 31–44, Feb. 2019.
Cacheline-Concious Extendible Hashing (CCEH) -> https://github.com/DICL/CCEH
캐시라인을 고려한 확장형 해싱(CCEH)
Write-Optimized Dynamic Hashing for Persistent Memory: https://www.usenix.org/conference/fast19/presentation/nam
Presentation Video -> https://youtu.be/wI4bEI7aghQ
LICENSE
Copyright (c) 2018, Sungkyunkwan University. All rights reserved.
The license is a free non-exclusive, non-transferable license to reproduce, use, modify and display the source code version of the Software,
with or without modifications solely for non-commercial research, educational or evaluation purposes.
The license does not entitle Licensee to technical support, telephone assistance, enhancements or updates to the Software.
All rights, title to and ownership interest in the Software, including all intellectual property rights therein shall remain in Sungkyunkwan University.
Copyright (c) 2018, 성균관대학교. 판권 소유.
라이센스는 비상업적 연구, 교육 또는 평가 목적으로만 수정 여부에 관계없이
소프트웨어의 소스 코드 버전을 복제, 사용, 수정 및 표시할 수 있는 무료 비독점, 양도 불가능한 라이센스입니다.
라이센스는 라이센스 사용자에게 소프트웨어에 대한 기술 지원, 전화 지원, 개선 또는 업데이트를 받을 자격을 부여하지 않습니다.
모든 지적재산권을 포함하여 소프트웨어에 대한 모든 권리, 소유권 및 소유권은 성균관대학교에 있습니다.
[68] P. Zuo, Y. Hua, and J. Wu.
Write-optimized and high-performance hashing index scheme for persistent memory.
영구 메모리를 위한 쓰기 최적화 및 고성능 해싱 인덱스 체계
In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 461–476, Oct. 2018.
⬜️ Range Indexes - 범위 인덱스
PM에 대한 대부분의 범위 인덱스는 B+-트리 또는 트리 변형이며 PM 쓰기를 줄이는 것을 목표로 합니다[2, 6, 7, 19, 30, 43, 59, 60, 64].
효과적인 기술은 선형 스캔 비용으로 정렬되지 않은 리프 노드[6, 7, 43, 64]이며,
해시 인덱스는 주로 연속 치환를 피하여 PM 쓰기를 줄입니다.
FP-tree[43]는 PM 액세스를 줄이기 위해 리프 노드의 지문을 제안합니다.
Dash는 불필요한 버킷 검색을 줄이고 가변 길이 키를 효율적으로 지원하기 위해 이를 채택했습니다.
일부 연구[43, 60]에서는 성능 향상을 위해 인덱스의 일부를 DRAM(예: 내부 노드)에 배치합니다.
이는 재시작 시 DRAM 부품을 재구성해야 하므로 즉시 복구와 상쇄(trades off)됩니다[31].
DRAM에 디렉터리를 배치하면 해시 테이블에서도 동일한 절충안(tradeoff)을 볼 수 있습니다.
버킷 로드 밸런싱 기술을 사용하면 Dash는 더 큰 세그먼트를 사용하고 디렉터리를 PM에 배치하여 이러한 절충안을 피할 수 있습니다.
⬜️ PM Programming
PM 데이터 구조는 PM 할당 및 공간 관리와 같은 문제를 쉽게 처리하기 위해 사용자 공간 라이브러리 및 OS 지원에 크게 의존합니다.
PMDK[20]는 지금까지 가장 인기 있고 포괄적인 라이브러리입니다.
이러한 라이브러리에서 중요한 문제는 PM이 영구적으로 누출되는 것을 방지하는 것입니다.
일반적인 솔루션[4, 20, 42, 50]은 할당-활성화(allocate-activate) 접근 방식을 사용하여 할당된 PM이 충돌 시
애플리케이션이나 할당자에 의해 소유되도록 하는 것입니다.
OS 수준에서 PM 파일 시스템은 캐시를 우회하고 포인터 기반 액세스를 허용하기 위해 DAX(직접 액세스)를 제공합니다[35].
일부 기존 파일 시스템(예: ext4 및 XFS)은 DAX를 지원하도록 조정되었습니다.
오버헤드를 더욱 줄이기 위해 PM 특정 파일 시스템도 제안되고 있습니다 [8, 23, 28, 47, 57, 61].
PM 프로그래밍에 대한 지원은 아직 초기 단계에 있으며 섹션 6.9에서 볼 수 있듯이 버그와
비효율성 가능성이 있어 빠르게 발전하고 있습니다.
이를 위해서는 향후 PM 데이터 구조를 설계할 때 신중한 통합과 테스트가 필요합니다.
🟢 8. CONCLUSION - 결론
영구 메모리는 성능(확장성)과 기능 모두에서 영구 해시 테이블에 새로운 과제를 안겨줍니다.
이전 작업에서는 PM 쓰기를 줄이는 데에만 초점을 맞추고 PM 관리 및 동시성 제어와 같은 많은 실제 문제를 무시하고
즉시 복구 기능을 절충한 반면, 불필요한 PM 읽기 및 쓰기를 모두 줄이는 것이 핵심이라는 것을 확인했습니다.
우리의 솔루션은 확장 가능한 PM 해싱에 대한 전체적인 접근 방식인 Dash입니다.
Dash는 (1) PM 액세스를 줄이기 위한 지문, (2) 낙관적 잠금, (3) 새로운 버킷 로드 밸런싱 기술을 포함한
새로운 기술과 기존 기술을 모두 결합합니다.
Dash를 사용하여 확장 가능한 해싱과 선형 해싱을 PM에서 작동하도록 조정했습니다.
실제 Intel Optane DCPMM에서 Dash는 이전 최첨단 성능보다 최대 3.9배 향상된 성능으로 확장하는 동시에
높은 부하율 및 1초 미만 수준의 즉시 복구를 포함한 바람직한 특성을 유지합니다.
Acknowledgements.
We thank Lucas Lersch (TU Dresden & SAP) and Eric Munson (University of Toronto) for helping us isolate bugs in the Linux kernel.
We also thank the anonymous reviewers and shepherd for their constructive feedback, and the PC chair’s coordination in the shepherding process.
This work is partially supported by an NSERC Discovery Grant, Hong Kong General Research Fund (14200817, 15200715, 15204116), Hong Kong AoE/P-404/18, Innovation and Technology Fund ITS/310/18.
감사의 말씀.
Linux 커널에서 버그를 격리하는 데 도움을 준 Lucas Lersch(Dresden 공대 및 SAP)와 Eric Munson(토론토 대학)에게 감사드립니다.
또한 건설적인 피드백을 주신 익명의 검토자와 심사위원들, 심사 과정에서 PC 의장의 조정에 감사드립니다.
이 작업은 NSERC 디스커버리 보조금, 홍콩 일반 연구 기금(14200817, 15200715, 15204116),
홍콩 AoE/P-404/18, 혁신 및 기술 기금 ITS/310/18에서 부분적으로 지원되었습니다.
📜 Dash: Scalable Hashing on Persistent Memory - 논문 원본
용어
🟡 단어 번역 기준
- deterministic 결정론적(決定論的)
- nondeterministic 비결정론적(非決定論的)
- optimistic 낙관적(樂觀的)
- pessimistic 비관적(悲觀的)
- positive search 긍정 검색(肯定 檢索)
- negative search 부정 검색(否定 檢索)
- Probing(프로빙) 탐색 探索 찾다/엿보다, 찾다. 드러나지 않은 사물이나 현상 따위를 찾아내거나 밝히기 위하여 살피어 찾음.
- Search 검색(檢索)
(1) 범죄나 사건을 밝히기 위한 단서나 증거를 찾기 위하여 살펴 조사함.
(2) 책이나 컴퓨터에서, 목적에 따라 필요한 자료들을 찾아내는 일. - load factor 적재율(O) 부하율(X)
- traditional 전통적인
- existing 기존의
- the most significant bits (MSBs)
- LSBs
- rehashing 재해싱
- redistributing 재배포
- Instant Recovery 즉시 복구
- segmentation 세분화
- stride 보폭
- reclamation 회수/재확보
- displacement 치환(置換) 바꾸어 놓음. 변위(變位)
키 중심으로 보면 변위가 맞고, 슬롯(버킷) 중심으로 보면 치환이 맞다. displacement는 키를 다른 버킷으로 이동하는 것이므로 변위를 사용하는 것이 더 맞다고 보지만, 변위는 일반적으로 사용하지 않아 어려우므로 치환을 사용한다. - dipping 디핑: 세그먼트 분할 후 부하율이 뚝 떨어졌다가 재해싱과 삽입이 되면서 부하율이 다시 올라가는 현상.
- spinlock 회전잠금
- persistent memory PM
- latency 대기 시간
- traded off 상쇄(相殺) 상반되는 것이 서로 영향을 주어 효과가 없어지는 일.
상충 相沖 사물이 서로 어울리지 아니하고 마주침. - fingerprinting 키의 지문(1바이트 해시)을 생성하고 이를 압축하여 키의 존재 가능성을 요약하는 것입니다.
- DIMM: dual in-line memory module
- SIMM (싱글 인라인 메모리 모듈:Single Inline Memory Module)에 비해 2배 이상의 데이터 버스 너비를 가지고 있는 것부터 DIMM로 불린다. 64비트(8바이트)+오류정정부호(8비트)=72 비트 데이터의 DIMM이 사용된다.
- 버킷 탐색: 하나의 버킷에서 검색 - Bucket probing: search in one bucket
- fingerprinting 키의 지문(1바이트 해시)을 생성하고 이를 압축하여 키의 존재 가능성을 요약하는 것입니다.
- ADR: Asynchronous DRAM Refresh
- random 무작위/랜덤
- end-to-end 종단 간
- global depth 전역 깊이
- local depth 지역 깊이
- Extendible Hashing 확장 가능한 해싱
- atomicity 원자성
- atomically 원자적
- atomic 원자 atomic write 원자 쓰기
- segmentation 세분화/세그먼트
🟡 비관적 잠금(Pessimistic Locking)과 낙관적 잠금(Optimistic Locking) 비교
✅ 1. 비관적 잠금 (Pessimistic Locking)
비관적 잠금은 데이터에 접근하기 전에 항상 잠금을 취득하는 방식입니다.
마치 다중 사용자 환경에서 화장실을 이용하기 전에 문을 잠그는 것과 비슷하다고 생각하면 됩니다.
잠금을 취득하면 해당 데이터에 대한 독점적 접근 권한을 얻게 되므로 다른 사용자가 데이터를 변경하지 못하게 됩니다.
⦿ 장점:
- 데이터 무결성을 철저하게 보장합니다. 다른 사용자가 데이터를 변경할 가능성이 없기 때문에 항상 일관된 데이터를 사용할 수 있습니다.
- 충돌 발생 가능성이 낮습니다. 데이터에 접근하기 전에 잠금을 취득하기 때문에 다른 사용자와의 충돌이 발생할 가능성이 매우 낮습니다.
⦿ 단점:
- 성능 저하를 초래할 수 있습니다. 모든 사용자가 데이터에 접근하기 전에 잠금을 취득해야 하기 때문에 시스템 성능이 저하될 수 있습니다.
- 리소스 낭비가 발생할 수 있습니다. 사용하지 않는 데이터라도 잠금을 취득하고 있으면 다른 사용자가 사용할 수 없어 리소스 낭비가 발생할 수 있습니다.
⦿ 사용 상황:
- 데이터 무결성이 매우 중요한 경우
- 충돌 발생 가능성이 높은 경우
- 데이터 양이 적은 경우
- 데이터베이스 트랜잭션에서 특정 레코드를 수정할 때, 해당 레코드에 대해 잠금을 걸어 다른 트랜잭션이 접근하지 못하게 합니다.
✅ 2. 낙관적 잠금 (Optimistic Locking)
낙관적 잠금은 데이터를 실제로 변경하기 전까지는 잠금을 취득하지 않고, 변경 후에 데이터 버전을 비교하여 충돌을 감지하는 방식입니다.
마치 여러 사람이 동시에 도서관에서 같은 책을 빌려보려는 경우, 먼저 책을 예약한 사람이 빌려갈 수 있다는 방식과 비슷하다고 생각하면 됩니다.
⦿ 장점:
- 성능 향상을 기대할 수 있습니다. 잠금을 취득하지 않기 때문에 시스템 성능이 향상될 수 있습니다.
- 리소스 활용도를 높일 수 있습니다. 사용하지 않는 데이터라도 다른 사용자가 사용할 수 있어 리소스 활용도를 높일 수 있습니다.
⦿ 단점:
- 데이터 무결성 위험이 있습니다. 다른 사용자가 동시에 같은 데이터를 변경할 경우 충돌이 발생하여 데이터 무결성이 손상될 수 있습니다.
- 충돌 발생 시 추가 처리가 필요합니다. 충돌이 발생하면 롤백 등의 추가 처리가 필요하기 때문에 시스템 오버헤드가 발생할 수 있습니다.
⦿ 사용 상황:
- 데이터 무결성이 중요하지만 성능 또한 중요한 경우
- 충돌 발생 가능성이 낮은 경우
- 데이터 양이 많은 경우
- 데이터베이스에서 버전 번호나 타임스탬프를 사용하여 업데이트할 때, 자원 접근 시점의 버전과 업데이트 시점의 버전을 비교하여 충돌을 감지합니다. 만약 버전이 변경되었으면 충돌이 발생한 것으로 간주하고 재시도합니다.
🟡 스핀록(spinlocks) 회전잠금
컴퓨터 공학에서 스핀록은 여러 스레드가 공유 자원에 동시에 액세스하는 것을 방지하는 동기화 도구입니다.
뮤텍스(mutex)와 유사하지만, 스핀록은 잠금을 얻기 위해 CPU 시간을 소비하는 반면,
뮤텍스는 잠금을 얻을 수 없을 때 블록됩니다.
⦿ 스핀록의 작동 방식:
• 스레드는 잠금을 얻기 위해 스핀록 변수를 반복적으로 확인합니다.
• 잠금이 사용 가능하면 스레드는 잠금을 설정하고 자원에 액세스합니다.
• 자원에 액세스가 완료되면 스레드는 잠금을 해제합니다.
⦿ 스핀록의 장점:
• 간단하고 구현하기 쉬움
• 뮤텍스보다 오버헤드가 적음
• 짧은 임계 구역(critical section)에 적합
⦿ 스핀록의 단점:
• CPU 사용량이 증가할 수 있음
• 긴 임계 구역에는 적합하지 않음
• 우선권 역전(priority inversion) 문제 발생 가능성
⦿ 스핀록 사용 시 주의 사항:
• 임계 구역이 짧은지 확인
• CPU 사용량을 모니터링
• 우선권 역전 문제를 방지하기 위한 추가적인 메커니즘 필요
Linux Documentation:
• Spinlocks
• Wound/Wait Deadlock-Proof Mutex Design
• Proper Locking Under a Preemptible Kernel: Keeping Kernel Code Preempt-Safe
• Lightweight PI-futexes
🟡 컴퓨터 공학에서 Cuckoo hashing(뻐꾸기 해싱)에 대한 설명
Cuckoo hashing은 해시 테이블에서 데이터 저장 및 검색을 위한 효율적인 알고리즘입니다.
이 알고리즘은 데이터를 해시 테이블에 저장하는 두 개의 해시 함수를 사용하여 충돌을 해결합니다.
⬜️ Cuckoo hashing의 주요 특징은 다음과 같습니다.
⦿ 두 개의 해시 함수 사용: Cuckoo hashing은 데이터를 해시 테이블에 저장하는 두 개의 해시 함수를 사용합니다.
이 두 함수는 서로 독립적이어야 하며, 충돌을 최소화하도록 설계되어야 합니다.
⦿ 충돌 해결: 두 해시 함수가 동일한 버킷을 가리키는 경우 충돌이 발생합니다.
Cuckoo hashing은 충돌을 해결하기 위해 다음 두 가지 전략을 사용합니다.
o 재해시: 충돌하는 데이터를 다른 버킷으로 재해시합니다. 재해시에는 두 가지 방법이 있습니다.
• Simple cuckoo: 데이터를 다른 버킷으로 재해시하고, 그 자리에 있던 데이터를 재해시합니다.
• Lazy cuckoo: 충돌하는 데이터만 재해시하고, 그 자리에 있던 데이터는 그대로 둡니다.
o 쿠쿠 교환: 두 개의 충돌하는 데이터를 서로 교환합니다.
⦿ 사이클 검출: Cuckoo hashing은 무한한 재해시 루프를 방지하기 위해 사이클 검출 메커니즘을 사용합니다.
일반적인 사이클 검출 메커니즘으로는 다음과 같은 것들이 있습니다.
o 플래그 비트: 각 버킷에 플래그 비트를 사용하여 방문 여부를 표시합니다. 버킷을 방문할 때마다 플래그 비트를 설정하고,
사이클이 감지되면 해당 버킷에 있는 모든 데이터를 삭제합니다.
o 시간 제한: 재해시를 수행할 때 시간 제한을 설정하고, 제한 시간 내에 충돌을 해결하지 못하면 해당 버킷에 있는 모든 데이터를 삭제합니다.
⬜️ Cuckoo hashing은 다음과 같은 장점을 가지고 있습니다.
• 높은 효율성: Cuckoo hashing은 높은 충돌 해결률을 가지고 있어, 데이터 검색 및 저장 작업을 빠르게 수행할 수 있습니다.
• 간단한 구현: Cuckoo hashing은 비교적 간단하게 구현할 수 있습니다.
• 적은 메모리 사용: Cuckoo hashing은 다른 해시 알고리즘에 비해 적은 메모리를 사용합니다.
⬜️ 하지만 Cuckoo hashing은 다음과 같은 단점도 가지고 있습니다.
• 무작위 해시 함수 필요: Cuckoo hashing은 효율적인 작동을 위해 무작위 해시 함수를 필요로 합니다.
• 사이클 검출 오버헤드: Cuckoo hashing은 무한한 재해시 루프를 방지하기 위해 사이클 검출 메커니즘을 사용하는데,
이는 추가적인 오버헤드를 발생시킬 수 있습니다.
Cuckoo hashing은 데이터 저장 및 검색 작업이 중요한 애플리케이션에서 많이 사용됩니다.
예를 들어, 웹 캐싱, 라우터 테이블 관리, 데이터베이스 인덱싱 등에 사용됩니다.
⬜️ Cuckoo hashing 관련 자료
• Cuckoo hashing Wikipedia
• Cuckoo hashing GeeksforGeeks
⬜️ 추가 정보
• Cuckoo hashing은 다른 해시 알고리즘, 예를 들어 선형 탐색 해싱, 이중 해싱 등과 비교할 수 있습니다.
• Cuckoo hashing은 다양한 변형이 존재합니다. 예를 들어, 여러 개의 해시 함수를 사용하는 multi-cuckoo hashing,
사이클 검출 메커니즘을 개선한 cuckoo+ hashing 등이 있습니다.
🟡 [20] Intel. PMDK: Persistent Memory Development Kit. 2018.
⬜️ libpmem 라이브러리 (pmem.io)
libpmem은 낮은 수준의 영구 메모리 지원을 제공합니다.
특히, pmem에 대한 변경 사항을 플러시하기 위한 영구 메모리 명령에 대한 지원이 제공됩니다.
이 라이브러리는 모든 저장소를 pmem으로 추적하고 내구성에 대한 변경 사항을 플러시해야 하는 소프트웨어용으로 제공됩니다.
대부분의 개발자는 "libpmemobj"와 같은 상위 수준 라이브러리가 훨씬 더 편리하다는 것을 알게 될 것입니다.
⬜️ libpmemobj 라이브러리 (pmem.io)
"libpmemobj"는 영구 메모리 파일을 유연한 객체 저장소로 변환하여 트랜잭션, 메모리 관리, 잠금, 목록 및 기타 여러 기능을 지원합니다.
⬜️ PMDK: 영구 메모리 개발 키트 (github)
소스, 컴파일(make)
🟡 구현된 소스(open-source)
구현된 소스(open-source):
Dash: Scalable Hashing on Persistent Memory
Persistent memory friendly hashing index. 영구 메모리 친화적 해싱 인덱스.
Fully open-sourced under MIT license. MIT 라이선스에 따라 완전히 오픈 소스로 제공됩니다.
⬜️ What's included - 내용
- Dash EH - Proposed Dash Extendible Hashing - Dash EH - Dash 확장 가능 해싱
- Dash LH - Proposed Dash Linear Hashing - Dash LH - Dash 선형 해싱
- CCEH - PMDK patched CCEH variant used in our benchmark - CCEH - 벤치마크에서 사용된 PMDK 패치 CCEH 변형
- Level Hashing - PMDK patched level hashing variant used in our benchmark - 레벨 해싱 - 벤치마크에서 사용된 PMDK 패치 레벨 해싱 변형
- Mini benchmark framework - 미니 벤치마크 프레임워크
- Example program - 예제 프로그램 - Dash를 애플리케이션에 통합하는 방법
⬜️ Building
Dependencies - 종속성
Linux 커널 5.5.3과 GCC 9.2에서 빌드를 테스트했습니다.
우리는 맞춤형(customized) PMDK에서 "MAP_FIXED_NOREPLACE"를 사용하므로
Linux 커널 버전이 4.17 이상, glibc 버전이 2.29 이상인지 확인해야 합니다.
외부 종속성은 맞춤형 "PMDK"와 "epoch manager"이며, 이 역시 오픈 소스입니다.
⬜️ Compiling
"build" 디렉토리에서 컴파일한다고 가정합니다.
⬜️ Running benchmark - 벤치마크 실행
논문에서 언급했듯이, 24개의 물리적 CPU 코어를 가진 단일 NUMA 노드에서 테스트를 실행합니다.
"스레드 ID" == "코어 ID"라고 가정하여 스레드를 물리적 코어에 고정합니다
(예: 듀얼 소켓 시스템의 경우, 코어 0~23은 소켓 0에, 코어 24~47은 소켓 1에 위치한다고 가정).
벤치마크를 실행하려면 build 디렉터리에 있는 test_pmem 실행 파일을 사용합니다.
이 파일은 다음 인수를 지원합니다.
해시 테이블의 벤치마크 예시와 간단한 테스트에 대한 스크립트 "run.sh"도 확인해 보세요.
⬜️ Example program - 예제 프로그램
Dash를 애플리케이션에 통합하는 방법을 알아보려면 src 아래를 example.cpp 확인하세요.
실행 파일은 "build" 디렉터리 "example"에 있습니다.
또한 올바른 빌드를 위해 종속성(사용자 정의 PMDK 및 Epoch 관리자)을 연결하는 방법도 CMakeLists.txt 확인하세요.
⬜️ Miscellaneous - 기타
mmap 테스트 환경에서 잠재적 버그를 발견했습니다.
"MAP_SHARED_VALIDATE"는 "MAP_FIXED_NOREPLACE"와 호환되지 않습니다(Linux 4.17부터).
안전한 메모리 매핑을 보장하기 위해 원래의 "PMDK"를 수정하여 "MAP_SHARED_VALIDATE" 대신 "MAP_SHARED"를 사용하게 했습니다.
이는 이전 버전과 기능은 동일하지만 플래그 검증이 추가로 추가되었습니다.
🟡 컴파일(make)
⬜️ VM IP:192.168.56.101(노트북): CentOS-9 Stream: Kernel 5.14.0_x86_64, gcc 11.4.1 glibc 2.34
⬜️ 설치한 것들: 미리 설치한 것들과 make로 컴파일(1차~9차)하면서 에러가 발생할 때마다 설치한 패키지들이다.
- [설치]# dnf install git
[확인]# git --version -> git version 2.43.5 /usr/bin/git - [설치]# dnf install cmake
[확인]# cmake --version -> cmake version 3.26.5 /usr/bin/cmake - [설치]# dnf install gcc
[확인]# gcc --version -> gcc (GCC) 11.5.0 20240719 (Red Hat 11.5.0-2) /usr/lib64/ccache/gcc - [설치]# dnf install gcc-c++
[확인]# g++ --version -> g++ (GCC) 11.5.0 20240719 (Red Hat 11.5.0-2) /usr/lib64/ccache/g++
[확인2]# dnf list installed | grep gcc-c++ -> gcc-c++.x86_64 11.5.0-2.el9 @appstream
[확인3]# rpm -qa | grep gcc-c++ -> gcc-c++-11.5.0-2.el9.x86_64 - [설치]# dnf install ndctl -> https://chatgpt.com/s/t_68f58869c48c8191868e42ccc918b6bd
[확인]# ndctl --version -> 71.1
[확인]# ndctl list -> (NVDIMM 장치 목록을 조회) 없으므로 조회되지 않는다. - [설치]# dnf install ndctl-devel
[확인]# pkg-config --list-all | grep ndctl - [설치]# dnf install daxctl -> https://chatgpt.com/s/t_68f589f501988191b6deb117370565d3
[확인]# daxctl --version -> 71.1 - [설치]# dnf install daxctl-devel
[확인]# pkg-config --list-all | grep daxctl - [준비]# dnf install epel-release
[준비]# dnf update
[설치]# dnf install pandoc -> Pandoc은 다양한 문서 형식 간의 변환을 지원하는 강력한 도구입니다.
[확인]# pandoc --version -> pandoc 2.14.0.3 - [설치]# dnf install m4 -> m4는 매크로 프로세서(macros processor)로, 텍스트 변환과 코드 생성을 자동화하기 위해 사용되는 도구입니다.
[확인]# m4 --version -> m4 (GNU M4) 1.4.19 - [설치]# dnf install autoconf -> autoconf는 GNU 빌드 시스템의 일부로, 소프트웨어 패키지의 컴파일 및 설치를 자동화하는 데 사용됩니다.
[확인]# autoconf --version -> autoconf (GNU Autoconf) 2.69 - [설치]# dnf install libfabric -> libfabric-1.18.0-1.el9.x86_64, libpsm2-11.2.230-1.el9.x86_64, librdmacm-48.0-1.el9.x86_64
- [설치]# dnf install gflags-devel -> /usr/include/gflags/ 디렉터리에 설치됩니다.
⬜️ git에서 받고 컴파일하기
- $ git clone https://github.com/baotonglu/dash.git
- $ cd dash
- dash$ mkdir build && cd build
- build$ cmake -DCMAKE_BUILD_TYPE=Release -DUSE_PMEM=ON ..
- source 수정 - 1
pmdk source 중 2개 파일의 incloude 문을 수정한다.
🔹 build/pmdk/src/PMDK/src/common/os_dimm_ndctl.c:47:#include <ndctl/libdaxctl.h> -> <daxctl/libdaxctl.h>
🔹 build/pmdk/src/PMDK/src/tools/daxio/daxio.c:53:#include <ndctl/libdaxctl.h> -> <daxctl/libdaxctl.h>
📍 이유: "ndctl-devel"와 "daxctl-devel"를 설치하면 libdaxctl.h 파일이 /usr/include/daxctl/ 아래에 위치하는데, 소스에는 ndctl 아래로 잘못되어 있다. 개발 당시에는 "libdaxctl.h" 파일을 "ndctl" 디렉토리로 복사해서 사용한 것으로 추정된다.
🚩 해당 파일 위치
[/usr/include/daxctl]# libdaxctl.h
[/usr/include/ndctl]# libndctl.h, ndctl.h
📌 이렿게 수정하면 아래 "6차:make" 에러가 발생하지 않는다. - build$ make
위와 같이 설치하고 소스까지 수정했으면 아래에 있는 "1차~8차: make" 에러는 발생하지 않는다.
⬜️ 1차: make -> 상황 파악
⬜️ 2차: make -> ndctl 설치
[설치]# dnf install ndctl
[확인]# ndctl --version -> 71.1
[확인]# ndctl list -> (NVDIMM 장치 목록을 조회) 조회되지 않는다.
[설치]# dnf install ndctl-devel
[확인]# pkg-config --list-all | grep ndctl
⬜️ 3차: make -> daxctl 설치
[설치]# dnf install daxctl
[확인]# daxctl --version -> 71.1
[설치]# dnf install daxctl-devel
[확인]# pkg-config --list-all | grep daxctl
libfabric -> LIBFABRIC_MIN_VERSION := 1.4.2
libunwind
libndctl -> NDCTL_MIN_VERSION := 60.1
libdaxctl
⬜️ 4차: make -> pandoc, m4 설치
[설치]# dnf install pandoc -> pandoc 2.14.0.3
[설치]# dnf install m4 -> m4 (GNU M4) 1.4.19
⬜️ 5차: make -> autoconf 설치
[설치]# dnf install autoconf
⬜️ 6차: make -> "daxctl"에 있는 libdaxctl.h 파일을 ndctl 디렉터리로 복사
위 source 수정 - 1 참조
⬜️ 7차: make -> libfabric 설치
libfabric 이란 -> https://chatgpt.com/s/t_68f5a0fbccf88191be7d985be63abee1
◎ /dash/build/pmdk/src/PMDK-stamp/PMDK-build-out.log
redis@localhost PMDK-stamp]$ cat PMDK-build-out.log
◼️ libfabric -> 설치 완료.
[설치]# dnf install libfabric -> libfabric-1.18.0-1.el9.x86_64, libpsm2-11.2.230-1.el9.x86_64, librdmacm-48.0-1.el9.x86_64
-> PMDK-build-out.log -> 설치했으나 같은 에러(?) 발생
-> PMDK-build-err.log -> 아래 많은 에러 없어짐.
◎ [redis@localhost PMDK-stamp]$ cat PMDK-build-err.log
⬜️ 8차: make -> gflags-devel 설치
◼️ gflags/gflags.h는 Google Flags(gflags) 라이브러리에 포함된 헤더 파일입니다.
gflags는 C++ 및 C에서 명령줄 옵션을 처리하기 위한 라이브러리입니다.
이 라이브러리를 사용하면 프로그램이 명령줄 인자를 쉽게 파싱하고, 검증하며, 사용할 수 있습니다.
[설치]# dnf install gflags-devel -> /usr/include/gflags/ 디렉터리에 설치됩니다.
⬜️ 9차: build$ make -> No Error
⬜️ source 수정 - 2
📍dash/src/ex_finger.h 파일에서 "Allocator::Persist()" 38곳 중 25곳 주석 처리
이유: 원래 Persistent Memory를 사용해야 하는데, 없으므로 Disk를 사용했다.
"Allocator::Persist()"를 사용하면 성능이 매우 떨어저서 테스트하는 의미가 없다.
최종 목적이 "In Memory DB"를 테스트하는 것이므로 여기서는 주석 처리하고 테스트했다.
⬜️ source 수정 - 3
📍dash/src/test_pmem.cpp 파일에서 "if (!load_num)" 3곳 주석 처리
이유: 테스트를 원할하기 하기 위해서 "if (!load_num)" 부분 주석 처리
⬜️ source 수정 - 4
📍dash/src/test_pmem.cpp 파일
data file 생성 디렉토리
원래 코드: std::string pool_name = "/mnt/pmem0/"; -> 이 dir을 만들어서 사용해도 된다.
수정 코드: std::string pool_name = "data/"; -> dash dir 아래에 data dir을 만들어서 사용한다.
📝 pkg-config -> version 1.7.3
라이브러리의 컴파일·링크 옵션을 자동으로 알려주는 도구
https://chatgpt.com/s/t_68f64d96d3c4819189885a4f7db3c444
1) /usr/lib64/pkgconfig/*.pc
2) /usr/share/pkgconfig/*.pc
• pkg-config --list-all -> package-name + desc
• pkg-config --list-package-names -> package-name
• pkg-config --list-package-names | grep ndctl
📝 libndctl
libndctl은 NVDIMM(NON-Volatile Dual In-line Memory Module) 장치와
Persistent Memory(지속 메모리) 관리를 위한 라이브러리입니다.
이 라이브러리는 NVDIMM 장치의 상태를 모니터링하고, 구성 및 관리 작업을 수행하는 데 사용됩니다.
NVDIMM 장치 목록을 조회: ndctl list
/dash/build/pmdk/src/PMDK-stamp/PMDK-build-err.log
/dash/build/pmdk/src/PMDK/src/common.inc:384: *** libndctl(version >= 60.1) is missing -- see README. Stop.
NDCTL_MIN_VERSION := 60.1
ndctl 설명 -> https://chatgpt.com/s/t_68f58869c48c8191868e42ccc918b6bd
[설치]# dnf install ndctl
[확인]# ndctl --version -> 71.1
[확인]# ndctl list -> (NVDIMM 장치 목록을 조회) 조회되지 않는다.
[설치]# dnf install ndctl-devel
📝 libdaxctl
libdaxctl은 Linux 환경에서 NVDIMM (Non-Volatile Dual In-line Memory Module) 장치의 관리 및 제어를 위한
라이브러리입니다. 이 라이브러리는 특히 Persistent Memory 장치의 설정과 관리를 간편하게 할 수 있도록 설계되었습니다.
libdaxctl은 PMEM(DAX - Direct Access)을 지원하는 메모리 영역을 효율적으로 사용할 수 있게 도와줍니다.
• libdaxctl.so: 이 라이브러리는 C 프로그래밍 언어로 작성되었으며, NVDIMM 장치를 제어하기 위한 다양한 API를 제공합니다.
• daxctl 유틸리티: libdaxctl을 기반으로 만들어진 커맨드라인 도구로, 이를 통해 NVDIMM 장치를 쉽게 관리할 수 있습니다.
[설치]# dnf install daxctl
[확인]# daxctl --version -> 71.1
[설치]# dnf install daxctl-devel
[확인]# pkg-config --list-all | grep daxctl
📝 pandoc
Pandoc은 다양한 문서 형식 간의 변환을 지원하는 강력한 도구입니다.
주로 마크다운(Markdown) 문서를 다른 형식으로 변환하는 데 자주 사용되지만,
그 외에도 많은 문서 형식 간의 변환을 지원합니다.
EPEL (Extra Packages for Enterprise Linux) 리포지토리를 추가해야 할 수도 있습니다.
# dnf install epel-release
# dnf update
# dnf install pandoc
# dnf search pandoc
# dnf info pandoc
# pandoc --version -> pandoc 2.14.0.3
📝 m4
m4는 매크로 프로세서(macros processor)로, 텍스트 변환과 코드 생성을 자동화하기 위해 사용되는 도구입니다.
원래는 Unix 시스템에서 매크로 프로세싱을 수행하기 위해 개발되었지만, 다양한 플랫폼에서 사용되고 있습니다.
# dnf install m4
# dnf search m4
# dnf info m4
# m4 --version -> m4 (GNU M4) 1.4.19
📝 autoconf
autoconf는 GNU 빌드 시스템의 일부로, 소프트웨어 패키지의 컴파일 및 설치를 자동화하는 데 사용됩니다.
autoconf는 소스 코드 디렉토리에 configure 스크립트를 생성하여, 다양한 환경에서 소프트웨어를 쉽게 설정하고
빌드할 수 있도록 합니다.
# dnf install autoconf
# autoconf --version -> autoconf (GNU Autoconf) 2.69
📝 dnf
dnf는 Red Hat 계열의 리눅스 배포판(CentOS, Fedora, RHEL 등)에서 사용하는 패키지 관리 시스템입니다.
dnf는 yum(Yellowdog Updater, Modified)의 후속으로, 패키지 설치, 업데이트, 제거, 의존성 해결 등
다양한 패키지 관리 작업을 수행할 수 있습니다.
dnf는 yum에 비해 성능이 개선되고, 의존성 해결 능력이 향상되었으며, 여러 새로운 기능이 추가되었습니다.
# dnf install epel-release
# dnf update
# dnf install package_name
# dnf search package_name
# dnf info package_name
📝 make -j
리눅스에서 make 명령어의 -j 옵션은 병렬로 여러 작업을 동시에 실행하여 빌드 시간을 단축시키기 위해 사용됩니다.
이 옵션은 make가 동시에 실행할 수 있는 최대 작업 수를 지정합니다.
-j 옵션 뒤에 숫자를 지정하지 않으면 make는 시스템의 모든 가능한 코어를 사용하여 최대한 많은 작업을 병렬로
실행하려고 시도합니다. 이 경우 시스템 리소스를 과도하게 사용하여 성능 저하를 초래할 수 있습니다.
make -j4 -> 동시에 최대 4개의 작업을 병렬로 실행하도록 합니다.
최적의 -j 값 선택
최적의 -j 값은 시스템의 CPU 코어 수와 메모리 용량에 따라 다릅니다.
일반적으로 시스템의 논리적 코어 수(물리적 코어 수 * 하이퍼스레딩 비율)에 1~2를 더한 값이 추천됩니다.
make -j$(nproc)
$ echo $(nproc) -> 8
실행, 테스트
🟡 실행
⬜️ -i: dash-ex 전용 옵션 설명
pmem_ex.data 파일 생성 시 Segment, Bucket 생성
Directory안에 Segment 64개, Segment안에 64개 Bucket, Bucket안에 14개 레코드 -> 64*14=896
-i 2 -> 2개 세그먼트 생성(2*896) -> 1,792개 레코드 생성
-i 16 -> 16개 세그먼트 생성(16*896) -> 14,336개 레코드 생성
-i 256 -> 256개 세그먼트 생성(256*896) -> 229,376개 레코드 생성
-i 65536 -> 65536개 세그먼트 생성(65536*896) -> 58,720,256개 레코드 생성
세그먼트를 미리 생성하지 않으면 insert 시 "Segment Split"이 발생해서 입력 속도가 느리진다.
테스트 시에는 -i 65536을 지정, 약 5천8백만개의 레코드를 미리 생성해서 테스트했다.
⬜️ 테스트 옵션
[dash]$ ./build/test_pmem -index dash-ex -op insert -ps 5 -k fixed -t 1 -i 65536 -p 10000000
-index dash-ex: Dash-Extendible Hashing 테스트
-op insert: insert 테스트, pos: Positive Search(긍정(있는 키) 검색), neg: Negative Search(부정(없는 키) 검색), delete: Delete
-ps 5: 5GB 파일 생성
-t 1: thread 개수 지정
-i 65536: 세그먼트 개수 지정
-p 10000000: 테스트 횟수 지정
⬜️ 테스트 방법
1) 입력 테스트: $ ./build/test_pmem -index dash-ex -op insert -ps 5 -k fixed -t 1 -i 65536 -p 10000000
2) 긍정 검색 테스트: $ ./build/test_pmem -index dash-ex -op pos -ps 5 -k fixed -t 1 -i 65536 -p 10000000
3) 부정 검색 테스트: $ ./build/test_pmem -index dash-ex -op neg -ps 5 -k fixed -t 1 -i 65536 -p 10000000
4) 삭제 테스트: $ ./build/test_pmem -index dash-ex -op delete -ps 5 -k fixed -t 1 -i 65536 -p 10000000
1) 입력 -> 2) 긍정 검색 -> 3) 부정 검색 -> 4) 삭제 순으로 테스트한다.
입력 테스트를 연속해서 두번하면 "unique_check() duplicate_insert return" 키 중복 메시지가 발생해서 테스트에 방해된다.
삭제 테스트를 연속해서 두번하면 "키가 없다"는 메시지가 발생해서 테스트에 방해된다.
• -t 스레드 조정: -t 1, 2, 4
• -p 테스트 횟수 조정: "-t 1"이면 -p 10000000(1천만), "-t 2"이면 -p 20000000(2천만), "-t 4"이면 -p 40000000(4천만).
즉, 스레드 당 1천만번 테스트한다.
🟡 테스트 서버
- CPU: Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz, 8 cores
- Memory: 8GB
- OS: Rocky Linux 9.5
- Linux kernel version: 5.14.0 x86_64
- C++ compiler: g++ --version g++ (GCC) 11.5.0 20240719 (Red Hat 11.5.0-5)
🟡 dash-ex 테스트
✅ Thread 1 테스트
- Insert: 4,407,833 ops
- Pos_search: 7,890,142 ops
- Neg_search: 7,924,201 ops
- Delete: 5,575,729 ops
✅ Thread 2 테스트
- Insert: 7,375,059 ops
- Pos_search: 9,106,065 ops
- Neg_search: 9,094,469 ops
- Delete: 7,677,907 ops
✅ Thread 4 테스트
- Insert: 15,384,028 ops
- Pos_search: 16,983,948 ops
- Neg_search: 17,012,580 ops
- Delete: 15,163,939 ops
✅ Thread 8 테스트
- Insert: 20,324,602 ops
- Pos_search: 32,933,658 ops
- Neg_search: 33,233,905 ops
- Delete: 20,173,855 ops
테스트 요약
| 구분 | Thread 1 (ops) | Thread 2 (ops) | t1 대비 | Thread 4 (ops) | t2 대비 | Thread 8 (ops) | t4 대비 |
|---|---|---|---|---|---|---|---|
| Insert | 4,407,833 | 7,375,059 | 1.7 | 15,384,028 | 2.1 | 20,324,602 | 1.3 |
| Pos_search | 7,890,142 | 9,106,065 | 1.2 | 16,983,948 | 1.9 | 32,933,658 | 1.9 |
| Neg_search | 7,924,201 | 9,094,469 | 1.1 | 17,012,580 | 1.9 | 33,233,905 | 2.0 |
| Delete | 5,575,729 | 7,677,907 | 1.4 | 15,163,939 | 2.0 | 20,173,855 | 1.3 |
| AVG | 6,449,476 | 8,313,375 | 1.3 | 16,136,124 | 1.9 | 26,666,505 | 1.6 |
🟡 dash-ex 테스트 (노트북)
- H/W Model: LG노트북 gram 16ZD90RU-GX56K M/D: 2023.11.
- CPU: Intel i5-1335U(13th) 2.50GHz 코어:10, 논리 프로세서:12, L1 캐시: 928KB, L2: 6.5MB, L3: 12.0MB
- VM: Virtualbox
- Host OS: Windows 11 Pro
- Guest OS: CentOS 9
- Linux kernel version: 5.14.0 x86_64
- C++ compiler: g++ --version g++ (GCC) 11.5.0 20240719 (Red Hat 11.5.0-2)
📍 노트북에서 테스트는 서버에 비해서 성능이 떨어지고 값도 일정하지 않습니다.
✅ 스레드(thread) -t 1 테스트 2025년 10월 22일(수)
요약
⭕️ Insert -> 82,685 ops
⭕️ Pos_search -> 1,620,550 ops
⭕️ Neg_search -> 1,919,755 ops
⭕️ Delete -> 154,829 ops
✅ 스레드 -t 2 테스트(1차) 2025년 10월 21일(화)
✅ 스레드 -t 2 테스트(2차) 2025년 10월 22일(수)
✅ 스레드 -t 4 테스트(1차) 2025년 10월 21일(화)
✅ 스레드 -t 4 테스트(2차) 2025년 10월 22일(수)
✅ 스레드 -t 4 테스트(3차) 2025년 10월 23일(목)
테스트 요약
| 구분 | Thread 1 (ops) | Thread 2 (ops) | t1 대비 | Thread 4 (ops) | t1 대비 | t2 대비 |
|---|---|---|---|---|---|---|
| Insert | 82,685 | 437,533 | 5.3 | 1,871,743 | 22.6 | 4.3 |
| Pos_search | 1,620,550 | 2,466,466 | 1.5 | 5,303,668 | 3.3 | 2.2 |
| Neg_search | 1,919,755 | 2,553,324 | 1.3 | 5,309,617 | 2.8 | 2.1 |
| Delete | 154,829 | 507,321 | 3.3 | 2,051,731 | 13.3 | 4.0 |
✅ 스레드 -t 6 테스트: -p 50000000 -> 테스트 가능
✅ 스레드 -t 6 테스트: -p 60000000 -> 테스트 실패
⭕️ Insert -> 끝나지 않음
[dash]$ ./build/test_pmem -index dash-ex -op insert -ps 10 -k fixed -t 6 -i 131072 -p 60000000
이유: 스레드 6개 합계 CPU 50% 이하로 사용, CPU core별로 wa(I/O wait) 90% 이상 발생.
프로그램(알고리즘) 문제인지, 노트북 CPU 문제인지 알 수 없음.
🟡 dash-lh 테스트
✅ 스레드(thread) -t 1 테스트 2025년 10월 24일(금)
/mnt/vdi_9_1/pmem_lh.data
[dash]$ ./build/test_pmem -index dash-lh -op insert -ps 1 -k fixed -t 1 -p 10000 -> CPU 5%
Result(Insert) Threads = 1, Time = 33.350 s, throughput = 299.85 ops
📍 결과: 299.85 ops 속도 매우 느림 -> 테스트 중지
✅ Allocator::Persist() 주석 처리가 필요할 것으로 보임.
🟡 cceh 테스트
✅ 스레드(thread) -t 1 테스트 2025년 10월 24일(금)
/mnt/vdi_9_1/pmem_cceh.data
[dash]$ ./build/test_pmem -index cceh -op insert -ps 1 -k fixed -t 1 -p 100000 -> CPU 7%
Result(Insert) Threads = 1, Time = 73.368 s, throughput = 1362.99 ops
📍 결과: 1362.99 ops -> 속도 매우 느림 -> 테스트 중지
🟡 level 테스트
✅ 스레드(thread) -t 1 테스트 2025년 10월 24일(금)
/mnt/vdi_9_1/pmem_level.data
[dash]$ ./build/test_pmem -index level -op insert -ps 1 -k fixed -t 1 -p 10000 -> CPU 2%
Result(Insert) Threads = 1, Time = 62.661 s, throughput = 159.59 ops
📍 결과: 159.59 ops -> 속도 매우 느림 -> 테스트 중지
소스 source
🟡 src/test_pmem.cpp
⬜️ ./util/pair.h:const Value_t DEFAULT = reinterpret_cast
reinterpret_cast<>는 C++에서 제공하는 네 가지 캐스트 연산자 중 하나로,
포인터나 참조형 변수를 다른 타입으로 변환할 때 사용됩니다.
reinterpret_cast<>는 다른 캐스트 연산자들보다 덜 안전하며,
주로 하드웨어 관련 프로그래밍이나 시스템 프로그래밍에서 특정 용도로 사용됩니다.
일반적으로 필요한 경우가 아니면, 더 안전한 캐스트 연산자(static_cast, dynamic_cast, const_cast)를
사용하는 것이 좋습니다.
reinterpret_cast<>는 강력하지만 위험할 수 있는 도구이므로,
사용 시 반드시 타입 호환성과 프로그램의 안정성을 고려해야 합니다.
⬜️ DEFINE_string: Google의 gflags 라이브러리에서 사용되는 매크로로, 프로그램의 명령줄 인수를 정의할 때 사용됩니다.
gflags는 Google의 glog(logging) 라이브러리와 함께 자주 사용되며,
C++ 프로그램에서 명령줄 인수를 쉽게 처리할 수 있도록 도와줍니다.
<gflags/gflags.h>
sudo dnf install libgflags-dev
g++ -o your_program your_program.cpp -lgflags
🟡 src/allocator.h
• 초기화: {nullptr}
nullptr는 C++11에서 도입된 키워드로, 포인터가 어떤 유효한 메모리 주소도 가리키지 않는다는 것을 명확하게 나타냅니다.
이전에는 NULL을 사용했으나, nullptr는 타입이 명확히 지정되므로 더 안전하고 권장됩니다.
pm_pool_{nullptr};는 변수 pm_pool_을 nullptr로 초기화하여, 이 포인터가 현재 유효한 메모리 주소를 가리키지 않음을 명확히 합니다.
• build/pmdk/src/PMDK/src/examples/ex_common.h:#define CREATE_MODE_RW (S_IWUSR | S_IRUSR)
📍 pmemobj_persist()
🚩 struct pmemobjpool -> PMEMobjpool
🏴 PMEMobjpool *pmemobj_create_addr()
🟡 src/Hash.h
모든 해시 인덱스의 상위 함수: 해시 인덱스의 인터페이스를 정의하는 데 사용됩니다.
🟡 util/hash.h
⚛ JENKINS HASH FUNCTION
⚛ MurmurHash2 hash function
🟡 util/pair.h
🟡 util/utils.h
🟡 src/ex_finger.h
⬜️ template <class T> struct Directory
⬜️ template <class T> struct Table /* Segment */
⬜️ template <class T> struct Bucket
⬜️ template <class T> struct TlsTablePool /*thread local table allcoation pool*/
⬜️ template <class T> class Finger_EH : public Hash<T>
⬜️ class Finger_EH
🟡 src/lh_finger.h
