
redis_conf_han
Redis Configuration file
 레디스 서버 교육 신청
레디스 서버 교육 신청
|
 레디스 정기점검/기술지원
레디스 정기점검/기술지원Redis Technical Support |
 레디스 엔터프라이즈 서버
레디스 엔터프라이즈 서버Redis Enterprise Server |
|---|
REDIS.CONF
이 문서는 버전 5.0.2를 기준으로 작성되었습니다.레디스 서버를 시작할 때 첫 번째 인수로 redis.conf 파일을 지정하세요.
src/redis-server redis.conf
단위: 메모리 크기를 지정할 때는 1k 5GB 4M 등의 일반적인 형식으로 사용할 수 있습니다.
단위는 대소문자를 구분하지 않으므로 1GB 1Gb 1gB는 모두 동일합니다.
1k => 1000 bytes
1kb => 1024 bytes
1m => 1000000 bytes
1mb => 1024*1024 bytes
1g => 1000000000 bytes
1gb => 1024*1024*1024 bytes
INCLUDES
INCLUDE
Conf 파일은 하나 이상의 다른 conf 파일을 포함할 수 있습니다.
여러 레디스 서버에 공통으로 적용할 표준이 있을 경우 유용하게 사용할 수 있습니다.
Include 파일에 또 다른 파일을 포함(include)할 수 있습니다.
레디스 서버는 지시자(directive)가 중복될 경우 마지막 것을 적용합니다.
공통사항을 적용하고 싶으면 include 파일을 마지막에 놓습니다.
공통사항 적용 후 개별 내용을 적용하고 싶으면 include 파일을 본 redis.conf 파일의 앞쪽에 놓습니다.
Include 파일은 "CONFIG REWRITE" 명령으로 다시 쓰지 않습니다.
지시자를 사용했을 경우에는 rewrite 하면 그 위치에 다시 씁니다.
사용하지 않았을 경우에는 본 redis.conf 파일의 마지막에 쓰여집니다.
즉, include 파일 다음에 쓰여지므로 redis.conf 파일을 확인할 필요가 있습니다.
센티널을 사용할 경우 장애조치 등으로 구성이 변경될 경우 센티널이 "CONFIG REWRITE" 명령을 실행합니다.
# include /path/to/local.conf
# include /path/to/other.conf
more info
MODULES
LOADMODULE
레디스 서버가 시작할 때 모듈을 로드합니다. 모듈을 로드할 수 없으면 레디스 서버는 시작하지 못합니다. loadmodule 지시자를 여러 개 사용할 수 있습니다.
# loadmodule /path/to/my_module.so
# loadmodule /path/to/other_module.so
NETWORK
BIND
Bind로 하나 또는 여러 개의 IP를 지정할 수 있습니다. 이 경우 지정한 IP로만 레디스 서버에 접속할 수 있습니다. Bind 지시자를 지정하지 않으면 서버에서 사용 가능한 모든 네트워크 인터페이스로 접속을 허용합니다.
bind 192.168.1.100 127.0.0.1
bind 127.0.0.1 ::1 -> 로칼 접속만 허용할 경우, ::1은 IPv6
bind * -::* -> 모든 접속을 허용할 경우 설정(Redis 6.2부터 가능), IPv4: *, IPv6: ::*
Redis 6.2 변경 사항
지정한 IP를 사용할 수 없는 경우 레디스 서버는 시작하지 않습니다.
예를 들어, bind 192.168.1.100를 지정했는데, IP 192.168.1.100가 서버에 없는 경우
(ifconfig로 확인할 수 없는 경우) 레디스 서버는
redis.log에 다음과 같은 에러 로그를 남깁니다.
"Warning: Could not create server TCP listening socket 192.168.1.100:6379: bind: Cannot assign requested address"
지정한 IP가 서버에 없는 경우에도 레디스 서버를 시작하게 하려면 IP 앞에 '-'을 붙이세요.
- 예 1: bind -192.168.1.100 -> 첫 번째 IP로 지정, 추천하지 않음.
사용할 수 없는 IP로 시작했을 경우 복제 설정(replicaof ip port)이나 엔터프라이즈 버전에서 동기화 설정(startsync ip port)이 되지 않고 에러가 발생합니다. 이 경우 에러의 원인을 방화벽(firewall) 설정이 문제인 것으로 오해할 수 있습니다. - 예 2: bind 192.168.1.101 -192.168.1.100 -> 두 번째 IP로 지정
현재는 사용할 수 없으나 failover 등의 목적으로 VIP를 사용하는 경우 위와 같이 두 번째 IP로 지정할 수 있습니다.
주의 사항
레디스 서버가 인터넷에 직접 연결된 서버에서 실행 중이면
꼭 bind 지시자를 사용하십시요.
로칼(local)에서만 접속하게 하려면 127.0.0.1을 사용하세요.
bind 127.0.0.1 more info
PROTECTED-MODE
보호(protected) 모드가 활성화(yes)되면 bind나 password가 설정되어 있지 않으면 로칼 접속만 허용합니다.
protected-mode yes more info
PORT
지정한 포트로 레디스 서버에 접속을 허용합니다. 기본 포트는 6379입니다.
port 6379 more info
TCP-BACKLOG
클라이런트 초당 연결수를 지정합니다. 리눅스 커널 파라미터인 /proc/sys/net/core/somaxconn과 tcp_max_syn_backlog 값을 설정하세요.
tcp-backlog 511 more info
UNIXSOCKET
들어오는 연결을 수신 대기하는데 사용될 유닉스 소켓의 경로를 지정하십시오. 기본값이 없으므로 레디스 서버는 지정되지 않은 경우 유닉스 소켓에서 수신 대기하지 않습니다.
# unixsocket /tmp/redis.sock
# unixsocketperm 700
TLS/SSL
기본적으로 TLS/SSL은 비활성화되어 있습니다.
이를 활성화하기 위해 "tls-port" 구성 지시문을 사용하여 TLS 수신 포트를 정의할 수 있습니다.
기본 포트에서 TLS를 활성화하려면 다음을 사용하십시오.
port 0
tls-port 6379
연결된 클라이언트, 마스터 또는 클러스터 피어에 대한 서버 인증에 사용할 X.509 인증서 및 개인 키를 구성합니다.
이러한 파일은 PEM 형식이어야합니다.
tls-cert-file redis.crt
tls-key-file redis.key
일반적으로 Redis는 서버 기능(연결 수락)과 클라이언트 기능(마스터에서 복제, 클러스터 버스 연결 설정 등)에
동일한 인증서를 사용합니다.
때때로 인증서는 클라이언트 전용 또는 서버 전용 인증서로 지정하는 속성과 함께 발급됩니다.
이 경우 들어오는(서버) 및 나가는(클라이언트) 연결에 서로 다른 인증서를 사용하는 것이 좋습니다.
이를 수행하려면 다음 지시문을 사용하십시오.
tls-client-cert-file client.crt
tls-client-key-file client.key
DH(Diffie-Hellman) 키 교환을 사용하도록 DH 매개 변수 파일을 구성하십시오.
tls-dh-params-file redis.dh
TLS/SSL 클라이언트 및 피어를 인증하도록 CA 인증서 번들 또는 디렉터리를 구성합니다.
Redis는 이들 중 하나 이상의 명시적인 구성이 필요하며 시스템 전체 구성을 암시적으로 사용하지 않습니다.
tls-ca-cert-file ca.crt
tls-ca-cert-dir /etc/ssl/certs
기본적으로 TLS 포트의 클라이언트(복제 서버 포함)는 유효한 클라이언트 측 인증서를 사용하여 인증해야 합니다.
'no'를 지정하면 클라이언트 인증서가 필요하지 않으며 허용되지 않습니다.
'optional'을 지정하면 클라이언트 인증서가 허용되고 제공된 경우 유효해야 하지만 필수는 아닙니다.
tls-auth-clients no
tls-auth-clients optional
기본적으로 Redis 복제본은 마스터와의 TLS 연결 설정을 시도하지 않습니다.
다음 지시문을 사용하여 복제 링크에서 TLS를 활성화합니다.
tls-replication yes
기본적으로 Redis 클러스터 버스는 일반 TCP 연결을 사용합니다.
버스 프로토콜에 대해 TLS를 활성화하려면 다음 지시문을 사용하십시오.
tls-cluster yes
기본적으로 TLSv1.2 및 TLSv1.3만 활성화되어 있으며 공격 표면을 줄이기 위해
공식적으로 사용되지 않는 이전 버전은 비활성화된 상태로 유지하는 것이 좋습니다.
지원할 TLS 버전을 명시적으로 지정할 수 있습니다.
허용되는 값은 대소 문자를 구분하지 않으며
"TLSv1", "TLSv1.1", "TLSv1.2", "TLSv1.3"(OpenSSL> = 1.1.1) 또는 임의의 조합을 포함합니다.
TLSv1.2와 TLSv1.3만 활성화하려면 다음을 사용하십시오.
tls-protocols "TLSv1.2 TLSv1.3"
허용된 암호를 구성합니다.
이 문자열의 구문에 대한 자세한 내용은 ciphers(1ssl) manpage를 참조하십시오.
참고: 이 구성은 <= TLSv1.2에만 적용됩니다.
tls-ciphers DEFAULT:!MEDIUM
허용된 TLSv1.3 암호 그룹을 구성합니다.
이 문자열의 구문, 특히 TLSv1.3 ciphersuite에 대한 자세한 내용은 ciphers(1ssl) manpage를 참조하십시오.
tls-ciphersuites TLS_CHACHA20_POLY1305_SHA256
암호를 선택할 때 클라이언트 기본 설정 대신 서버의 기본 설정을 사용하도록 합니다.
기본적으로 서버는 클라이언트의 기본 설정을 따릅니다.
tls-prefer-server-ciphers yes
기본적으로 TLS 세션 캐싱은 이를 지원하는 클라이언트에서 더 빠르고 저렴한 재연결을 허용하도록 활성화됩니다.
캐싱을 비활성화하려면 다음 지시문을 사용하십시오.
tls-session-caching no
캐시된 기본 TLS 세션 수를 변경합니다.
0 값은 캐시를 무제한 크기로 설정합니다.
기본 크기는 20480입니다.
tls-session-cache-size 5000
캐시된 TLS 세션의 기본 시간 제한을 변경합니다.
기본 시간 제한은 300 초입니다.
tls-session-cache-timeout 60
GENERAL
DAEMONIZE
레디스 서버는 디폴트로 데몬으로 실행되지 않습니다. 운영(production) 환경에서는 yes로 설정하세요. 레디스 서버는 데몬으로 실행될 때 /var/run/redis.pid 파일에 pid를 씁니다.
daemonize no recommend yes more info
SUPERVISED
Systemd 또는 upstart로 레디스 서버를 시작했을 경우 레디스 서버는 supervision tree와 상호작용할 수 있습니다.
- supervised no
- supervised upstart
- supervised systemd
- supervised auto
supervised no more info
PIDFILE
PID 파일이 지정되어 있으면 레디스 서버가 시작할 때 pid 파일을 만들고
레디스 서버의 프로세스 ID를 기록하고, 종료할 때 파일을 지웁니다.
레디스 서버가 데몬으로 실행되지 않고 pid 파일이 지정되어 있지 않으면 pid 파일을 만들지 않습니다.
레디스 서버가 데몬으로 실행되었는데 pid 파일이 지정되어 있지 않으면 기본으로 "/var/run/redis.pid"
파일에 기록합니다.
레디스 서버가 pid 파일을 만들지 못해도 레디스 서버는 정상적으로 실행됩니다.
(에러가 발생하지 않습니다).
"/var/run"에 pid 파일을 만들지 못하는 일반적인 이유는 해당 디렉토리 권한 때문입니다.
레디스 서버는 시작할 때 지정한 포트가 사용중인지 여부를 체크합니다.
PID 파일로 체크하지 않습니다.
pidfile /var/run/redis_6379.pid more info
DIR
작업 디렉토리(working directory)를 지정합니다.
이 디렉토리에는 log, rdb, appendonly, nodes.conf 파일이 위치합니다.
Log 파일과 data 파일을 구분하고자 할 경우 아래 log-dir, data-dir을 이용합니다.
dir ./
LOG-DIR
Log directory를 지정합니다. Log dir에는 redis.log, stat.log, slowlog.log, latency.log 파일이 위치합니다.
지정하지 않으면 위에서 설정한 working dir에 위치합니다.
이 기능은 Enterprise 버전에서 사용할 수 있습니다.
log-dir "/redis/log/"
DATA-DIR
Data directory를 지정합니다. Data dir에는 appendonly.aof, dump.rdb 파일이 위치합니다.
지정하지 않으면 위에서 설정한 working dir에 위치합니다.
이 기능은 Enterprise 버전에서 사용할 수 있습니다.
data-dir "/redis/data/"
LOGLEVEL
로그 레벨을 지정하세요.
- debug: '.' 많은 로그가 남습니다. 개발/테스트 용도로 사용합니다.
- verbose: '-' 디버그 레벨보다는 덜하지만 여전히 많은 로그가 남습니다.
- notice: '*' 운영(production)환경에 적합합니다.
- warning: '#' 중요하거나 심각한 메시지만 로깅합니다.
레디스 서버 5.0.2 기준으로 소스에 debug 26, verbose 20, notice 87, warning 277 곳 있습니다.
loglevel notice more info
LOGFILE
로그 파일을 지정하세요. 파일을 지정하지 않으면 로그가 표준 출력으로 나갑니다. 파일을 지정하지 않고 데몬으로 실행하면 로그는 "/dev/null"로 보내집니다.
logfile "" recommend redis.log more info
SYSLOG-ENABLED
시스템 로그 작성기에 로깅을 사용하려면 'syslog-enabled'를 yes로 설정하고 필요에 따라 다른 syslog 매개 변수를 수정하세요.
# syslog-enabled no
SYSLOG-IDENT
Syslog ID를 지정하십시요.
# syslog-ident redis
SYSLOG-FACILITY
Syslog 기능을 지정하십시요. USER 또는 LOCAL0-LOCAL7 사이어야합니다.
# syslog-facility local0
CRASH-LOG-ENABLED
레디스 서버 비정상 종료 시 코어 덤프를 남기지 않으려면 no를 지정하세요.
기본값은 yes입니다.
서버 데이터 구조: server.crashlog_enabled
# crash-log-enabled no
CRASH-MEMCHECK-ENABLED
코어 덤프 생성 시 메모리 검사를 비활성화하려면 no를 선택하세요.
기본값은 yes입니다.
서버 데이터 구조: server.memcheck_enabled
# crash-memcheck-enabled no
DATABASES
데이터베이스 개수를 지정합니다. 기본적으로 0~15번 DB가 있고, 지정하지 않으면 0번 DB를 사용합니다. SELECT dbid로 사용하는 DB를 지정할 수 있습니다.
databases 16 more info
ALWAYS-SHOW-LOGO
레디스 서버가 시작될 때 ASCII 로고를 보여줍니다.
버전 6.2부터 기본값이 yes에서 no로 변경되었습니다.
always-show-logo yes
SET-PROC-TITLE
기본적으로 Redis는 일부 런타임 정보를 제공하기 위해 프로세스 제목('top'및 'ps'에 표시됨)을 수정할 수 있습니다. 다음을 no로 설정하여 이를 비활성화하고 프로세스 이름을 실행된 상태로 둘 수 있습니다.
set-proc-title yes
PROC-TITLE-TEMPLATE
프로세스 제목을 변경할 때 Redis는 다음 템플릿을 사용하여 수정된 제목을 구성합니다.
템플릿 변수는 중괄호로 지정됩니다. 다음 변수가 지원됩니다.
{title} Name of process as executed if parent, or type of child process.
{listen-addr} Bind address or '*' followed by TCP or TLS port listening on, or Unix socket if only that's available.
{server-mode} Special mode, i.e. "[sentinel]" or "[cluster]".
{port} TCP port listening on, or 0.
{tls-port} TLS port listening on, or 0.
{unixsocket} Unix domain socket listening on, or "".
{config-file} Name of configuration file used.
proc-title-template "{title} {listen-addr} {server-mode}"
소스: server.c static sds redisProcTitleGetVariable(const sds varname, void *arg)
SNAPSHOTTING
Simplest persistence mode
SAVE
메모리에 있는 전체 데이터를 디스크에 저장합니다.
save <seconds> <changes>
지정된 시간(초) 동안 지정된 개수 이상의 키가 변경되면 DB(메모리)에 있는
전체 데이터를 디스크에 저장합니다.
SAVE 기능을 사용하지 않으려면 아래 save를 모두 주석(comment)처리하거나
SAVE "" 하면 됩니다.
버전 6.2 부터 이 기능이 디폴트로 비활성화되었습니다.
이벤트마다 메모리에 있는 데이터 전체를 디스크로 쓰는 것은 문제를 발생시킬 수 있습니다.
디폴트로 비활성화한 것은 당연한 조치입니다.
메모리에 있는 데이터를 디스크에 보관하려면 appendonly를 yes로 설정해 주세요.
900초(15분) 동안 적어도 1개 이상의 키가 변경되면 저장합니다.
300초(5분) 동안 적어도 10개 이상의 키가 변경되면 저장합니다.
60초(1분) 동안 적어도 10000개 이상의 키가 변경되면 저장합니다.
# save 900 1
# save 300 10
# save 60 10000 recommend save ""
more info
STOP-WRITES-ON-BGSAVE-ERROR
RDB 스냅샷(save 기능)이 활성화되어 있는 상태에서 BGSAVE가 실패하면
레디스 서버는 쓰기 명령을 받아들이지 않습니다.
이렇게 하면 데이터가 디스크에 제대로 유지되지 않는다는 것을 관리자가 알 수 있습니다.
그렇지 않으면 아무도 눈치 채지 못할 수도 있고 재앙이 발생할 가능성이 있습니다.
백그라운드 저장 프로세스가 다시 시작해서 성공하면
레디스 서버는 자동으로 다시 쓰기를 허용합니다.
레디스 서버에 대한 적절한 모니터링을 하고 있으면
이 기능을 사용하지 않도록 설정하여 디스크, 사용 권한 등에 문제가 있는
경우에도 레디스가 정상적으로 작동 할 수 있도록 할 수 있습니다.
stop-writes-on-bgsave-error yes recommend no more info
RDBCOMPRESSION
Rdb 파일을 저장할 때 LZF 압축을 사용합니다. 압축할 때 CPU를 좀 더 사용합니다.
rdbcompression yes more info
RDBCHECKSUM
체크섬(checksum)은 rdb 파일이 손상되었는지 확인하는 기능입니다.
RDB 버전 5부터 CRC64 체크섬을 파일 끝에 붙칩니다.
이 기능을 사용하면 rdb 파일을 저장하거나 로드할 때 약 10% 정도의 성능 저하가 있습니다.
체크섬을 사용하지 않은 파일에는 체크섬이 없다는 것을 표시하는 코드가 있습니다.
rdbchecksum yes more info
SANITIZE-DUMP-PAYLOAD
RDB 또는 RESTORE 페이로드를 로드할 때 ziplist 및 listpack 등에 대한 전체 위생 검사를
활성화하거나 비활성화합니다.
검사를 하면 나중에 명령을 처리하는 동안 어설션 또는 충돌 가능성이 줄어 듭니다.
선택:
- no - 위생 검사를 수행하지 않습니다.
- yes - 항상 완전한 위생 검사를 수행합니다.
- clients - 사용자 연결에 대해서만 전체 위생을 수행합니다.
제외: RDB 파일, 마스터 연결에서 수신한 RESTORE 명령, skip-sanitize-payload ACL 플래그가 있는 클라이언트 연결.
- 기본값은 'clients'여야 하지만 현재 MIGRATE를 통한 클러스터 리샤딩에 영향을 미치므로 기본적으로 일시적으로 'no'로 설정됩니다.
# sanitize-dump-payload no
RDB-DEL-SYNC-FILES
복제(전체 동기화)에 사용된 RDB 파일을 삭제합니다.
이 옵션은 AOF와 RDB가 모두 비활성화된 상태에서만 작동합니다.
기본적으로 이 옵션은 비활성화되어 있습니다.
규제(regulations) 또는 기타 보안 문제로 디스크에 데이터를 남기지 않을 경우 사용합니다.
동일한 효과를 얻는 대안(때로는 더 나은) 방법은 마스터와 복제본에서
디스크 없는 복제를 사용하는 것입니다.
디스크 없는 복제에 관련해서 마스터는 repl-diskless-sync, 복제본은 repl-diskless-load 파라미터를 참고하세요.
이 기능은 save 옵션을 사용하지 않았는데도 rdb 파일이 디스크에 남아있어
헷갈리는 것을 방지하기도 합니다.
rdb-del-sync-files no
DBFILENAME
RDB 파일 이름을 지정합니다.
dbfilename dump.rdb more info
RDB-SAVE-INCREMENTAL-FSYNC
RDB 파일을 저장할 때, 이 옵션이 활성화되면 매 32mb 마다 fsync를 수행합니다. 이는 디스크 I/O 경합을 피하는 방법입니다.
rdb-save-incremental-fsync yes more info
APPEND ONLY MODE
Advanced persistence mode
APPENDONLY
레디스는 기본적으로 데이터셋을 비동기로 디스크에 저장합니다.
이 방식은 많은 애플리케이션에 좋은 방식입니다.
그러나 레디스 프로세스가 죽거나 전원이 나가면 얼마동안의
데이터를 잃어버릴 수 있습니다.
Append only(추가 전용) 파일은 데이터 지속성을 유지하는 좋은 선택입니다.
디폴트 데이터 저장 정책을 사용한다면
머신에 전원이 나가는 일이 발생해도 최대 1초의 데이터만 유실됩니다.
AOF와 RDB를 같이 사용해도 문제가 없습니다.
AOF가 활성화되어 있으면 레디스 서버 시작 시 AOF 파일에 데이터를 로드합니다.
appendonly no more info
Persistence에 대한 전반적인 내용은 여기를 보세요.
APPENDFILENAME
AOF 파일명을 지정합니다.
appendfilename "appendonly.aof" more info
APPENDFSYNC
이 파라미터는 AOF 데이터를 실제로 디스크에 저장하는 방식을 설정합니다.
실제로 디스크에 저장하는 것은 fsync() 시스템 function을 호출하며, 세가지 방식을 제공합니다.
- always: 매 쓰기 명령이 실행될 때마다 fsync()를 실행합니다. 성능이 매우 떨어지지만 안전합니다.
- everysec: 1초 동안의 데이터를 모아서 별도의 쓰레드가 fsync()를 실행합니다. 성능과 데이터 안전성 면에서 올바른 선택입니다.
- no: 레디스가 fsync()를 실행하지 않습니다. OS가 주기적(30초)으로 fsync()를 실행해서 데이터를 디스크에 저장합니다. 성능은 좋을 수 있지만 데이터 유실의 가능성이 있습니다.
# appendfsync always
appendfsync everysec
# appendfsync no
http://antirez.com/post/redis-persistence-demystified.html
AUTO-AOF-REWRITE-PERCENTAGE, AUTO-AOF-REWRITE-MIN-SIZE
AOF 파일 자동 재작성(rewrite)
레디스는 AOF 파일이 설정한 퍼센트로 커지면 내부적으로 BGREWRITEAOF를 실행해서
자동으로 다시 씁니다.
레디스는 마지막 재작성 후의 파일 크기(base size)를 기억하고 있습니다.
처음에는 레디스가 시작했을 때 AOF 파일 크기를 기억합니다.
Base size와 현재 파일 크기를 비교합니다.
현재 파일 크기가 설정한 퍼센트보다 커지면 재작성합니다.
재작성 기능을 비활성화(disable)하려면 퍼센트를 0으로 설정합니다.
또한 재작성하는 최소 크기를 지정할 수 있습니다.
이것은 작은 파일이 자주 재작성되는 것을 막을 수 있습니다.
AOF Rewrite로 인한 메모리 사용량, CPU 사용률, 명령 실행에 미치는 영향(effect)은
AOF Rewrite effect를 보세요.
[2025년 8월 23일 업데이트]
auto-aof-rewrite-percentage 100
more info
auto-aof-rewrite-min-size 64mb
more info
AUTO-AOF-REWRITE-SPEC-TIME New
지정한 시간(hh24:mm)에 AOF를 rewrite 합니다.
서버 부하(load)가 적은 시간을 지정해서 사용하세요.
auto-aof-rewrite-percentage 보다
이 파라미터를 사용하는 것을 권장합니다.
사용하지 않으려면 주석(comment)처리하세요.
이 기능은 Enterprise 버전에서 사용할 수 있습니다.
auto-aof-rewrite-spec-time 03:00
NO-APPENDFSYNC-ON-REWRITE
AOF 재작성이나 RDB 파일 저장 중에는 많은 디스크 I/O가 발생합니다.
이때 fsync()가 실행되면 경합으로 지연이 발생할 수 있습니다.
AOF fsync is taking too long
이 옵션을 yes로 설정하면 AOF/RDB 파일 저장 중에는 fsync()를 실행하지 않습니다.
이것은 "appendfsync no"로 설정한 것과 같은 효과를 냅니다.
no-appendfsync-on-rewrite no recommend yes more info
AOF-REWRITE-INCREMENTAL-FSYNC
AOF 파일을 재작성(rewrite)할 때, 이 옵션이 활성화되면 매 32mb 마다 fsync를 수행합니다. 대량 디스트 I/O로 인한 문제를 줄이는 방법입니다.
aof-rewrite-incremental-fsync yes more info
AOF-LOAD-TRUNCATED
레디스 시작 시 AOF 파일을 메모리로 로드할 때 AOF 파일 끝이 잘린(truncated)것을 발견할 수 있습니다. 레디스가 실행중에 크레시(crash), 특히 ext4 파일시스템을 data=ordered 옵션없이 마운트된 경우(레디스가 크레시 되었지만 운영체제가 여전히 올바르게 동작하는 경우 발생하지 않습니다) 발생할 수 있습니다.
- Yes: 레디스는 가능한 많은 데이터를 로드하고 관리자에게 알리기 위해 관련 내용을 로그에 남깁니다. 레디스는 정상적으로 시작합니다.
- No: 레디스는 오류를 남기고 중단합니다. 이 경우 "redis-check-aof"유틸리티를 사용하여 AOF 파일을 수정해야합니다.
AOF 파일이 중간에 손상된 경우 레디스는 오류를 남기고 중단합니다.
aof-load-truncated yes more info
AOF-USE-RDB-PREAMBLE
AOF 파일을 재작성할 때, RDB 파일 형식(format)으로 작성합니다. 이 방식은 원래 AOF 파일 형식보다 재작성과 로딩 속도가 빠릅니다. 재작성 후에는 원래 AOF 형식으로 쓰여집니다.
[RDB file][AOF tail]
레디스는 AOF 파일이 "REDIS"로 시작하면 RDB 파일 형식으로 인식하고 로딩합니다.
aof-use-rdb-preamble yes more info
SECURITY
REQUIREPASS
Password를 설정합니다.
Password 설정 후에는 다른 명령을 실행하지 전에 "AUTH <PASSWORD>" 명령을
실행해야 합니다.
이 기능은 신뢰할 수 없는 사용자들이 접근할 수 있는 환경에서 유용합니다.
이 지시자는 하위 버전 호환성을 위해서 주석(comment)처리합니다.
왜냐하면 대부분의 사용자들에 auth를 필요로 하지 않기 때문입니다.
경고: 레디스는 auth를 초당 약 15만번 수행할 수 있습니다.
그러므로 강력한 암호를 설정하십시요.
# requirepass foobared
RENAME-COMMAND
여러 사용자가 접속할 수 있는 환경에서 관리자 명령은 레디스 서버에 치명적인 영향을 줄 수 있습니다. CONFIG 같은 명령을 추축하기 어려운 이름으로 변경할 수 있습니다.
rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
명령을 사용할 수 없게 빈 문자열로 지정할 수도 있습니다.
# rename-command CONFIG "" more info
주의: 명령어 변경은 AOF 파일 기록이나 복제 서버에 전송시 문제가 될 수도 있습니다.
오직 레디스 시작 시 redis.conf 파일에서만 적용됩니다.
CLIENTS
MAXCLIENTS
레디스 서버에 연결할 수 있는 최대 클라이언트 개수를 설정합니다. 기본으로 10000입니다. 레디스 서버가 내부적으로 32개를 사용하므로 이를 감안하십시요. 최대치에 도달하면 새로 접속하는 클라이언트는 "max number of clients reached" 에러 메시지를 받습니다.
# maxclients 10000 more info
TIMEOUT
일정 시간 사용하지 않는 클라이언트 연결을 닫습니다. 0으로 설정하면 비활성화됩니다. clientsCron()
timeout 0 more info
TCP-KEEPALIVE
통신이 없는 클라이언트에게 설정된 시간(초)마다 SO_KEEPALIVE를 사용해서
TCP ACKs를 보냅니다.
이것은 두 가지 이유에서 유용합니다.
1) 죽은 클라이언트 발견
2) 중간에 있는 네트워트 장비 관점에서 연결상태를 유지합니다.
연결을 닫기 위해서는 지정된 시간의 두 배가 필요합니다.
이 기간은 커널 설정에 따라 다를 수 있습니다.
버전 3.2.1 부터 기본값을 300으로 설정했습니다.
tcp-keepalive 300 more info
CLIENT-OUTPUT-BUFFER-LIMIT
클라이언트 출력 버퍼 제한은 어떤 이유로 든 서버에서 데이터를 빨리 읽지 않는
클라이언트의 연결을 강제로 해제하는 데 사용됩니다.
clientsCron()
제한은 세 종류의 클라이언에게 각각 다르게 설정할 수 있습니다.
normal -> 일반 클라이언트(MONITOR 클라이언트 포함)
replica -> 복제 클라이언트
pubsub -> Pub/Sub 클라이언트
사용법(syntax)은 다음과 같습니다.
client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds>
클라이언트는 하드 제한(hard limit)에 도달하면 즉시 연결이 해제됩니다.
또는
소프트 제한(soft limit)에 도달해서 설정한 시간이 지나면 연결이 해제됩니다.
예를 들어, 하드 제한이 32mb이고 소프트 제한이 16mb/10초인 경우
출력 버퍼가 32mb에 도달하면 즉시 연결이 해제되고
16mb로 10초가 지나면 연결이 해제됩니다.
일반 클라이언트는 요청한 데이터를 가져가기 때문에 일반적으로 제한이 필요없습니다.
복제 클라이언트나 Pub/Sub 클라이언트는 Push 방식이기 때문에
디폴트로 제한을 설정합니다.
기능을 비활성화하려면 0으로 설정하세요.
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
CLIENT-QUERY-BUFFER-LIMIT
클라이언트 쿼리 버퍼는 새로 들어오는 명령을 저장합니다. 쿼리 버퍼 제한은 디폴트로 1gb입니다. 큰 multi/exec 같이 특별한 경우 여기에서 설정할 수 있습니다.
# client-query-buffer-limit 1gb
PROTO-MAX-BULK-LEN
레디스 프로토콜에서 대량 요청 크기는 디폴트로 512mb입니다. 여기서 변경할 수 있습니다.
# proto-max-bulk-len 512mb
이 지시자는 버전 4.0.7 부터(2018년 1월) 도입되었습니다.
MEMORY MANAGEMENT
MAXMEMORY
레디스 서버가 사용할 수 있는 메모리 한계치를 설정할 수 있습니다. 메모리 한계에 도달하면 입력을 받지 않을지 아니면 기존에 키 중에서 어떤 키를 삭제할지를 정책(maxmemory-policy)으로 정할 수 있습니다.
'noeviction' 정책은 키를 지우지 않습니다. 이 경우 SET 같은 '쓰기' 명령은 에러를 리턴받습니다. 하지만 GET 같은 '조회' 명령은 계속 실행할 수 있습니다.
이 옵션은 레디스를 LRU 또는 LFU 케시 서버로 사용할 때나 인스턴스의 메모리 사용에 제한을 설정할 때 유용합니다.
# maxmemory <bytes>
MAXMEMORY POLICY
MAXMEMORY 정책: 설정한 메모리 한계치까지 사용했을 때 어떻게 할지를 정합니다.
- volatile-lru -> 만료 시간이 설정된 키중에서 근사 LRU로 삭제할 키를 정한다.
- allkeys-lru -> 모든 키중에서 근사 LRU로 삭제할 키를 정한다.
- volatile-lfu -> 만료 시간이 설정된 키중에서 근사 LFU로 삭제할 키를 정한다.
- allkeys-lfu -> 모든 키중에서 근사 LFU로 삭제할 키를 정한다.
- volatile-random -> 만료 시간이 설정된 키중에서 임의(random)로 삭제할 키를 정한다.
- allkeys-random -> 모든 키중에서 임의로 삭제할 키를 정한다.
- volatile-ttl -> 만료시간이 가장 가까운 키 순으로 삭제한다.
- noeviction -> 키를 삭제하지 않는다. 쓰기 명령에 에러를 리턴한다.
LRU: Least Recently Used
LFU: Least Frequently Used
LRU, LFU, TTL은 근사 임의 알고리즘으로 구현되어 있습니다.
퇴출할(eviction) 적당한 키가 없으면 레디스 서버는 에러를 리턴합니다.
# maxmemory-policy noeviction
MAXMEMORY-SAMPLES
LRU, LFU, 최소 TTL 알고리즘은 정밀하지 않습니다.
하지만 메모리를 절약하기 위한 적절한 알고리즘입니다.
레디스는 5개의 키를 검사해서 그 중 하나를 선택합니다.
샘플 사이즈를 변경할 수 있습니다.
기본값이 5가 적당하고, 10은 보다 정밀하며, 3은 빠르지만 정밀하지 않습니다.
# maxmemory-samples 5
REPLICA-IGNORE-MAXMEMORY
레디스 버전 5부터 복제 서버는 maxmemory 설정을 무시합니다.
(마스터로 승격하면 설정이 적용됩니다)
이것은 마스터가 키를 삭제하고 복제 서버로 DEL 명령으로 전달되기 때문입니다.
이 방식이 마스터와 복제간 동일성을 유지합니다.
복제 서버가 마스터와 다른 maxmemory 값을 가지고 있거나
복제 서버에 쓰기 허용을 했을 경우 문제가 발생할 수 있습니다.
# replica-ignore-maxmemory yes
LFU-LOG-FACTOR, LFU-DECAY-TIME
Maxmemory-policy를 LFU 알고리즘으로 선택했을 때
LFU 값을 수집하고 이 파라미터를 적용할 수 있습니다.
Object freq <key> 로 LFU를 확인할 수 있습니다.
LFU는 1 바이트를 사용하므로 0~255까지 값을 가질 수 있습니다.
계산 방법은 다음과 같습니다.
- 0과 1 사이에 임의의 값을 구합니다. double R = (double)rand()/RAND_MAX;
- 확률 P를 구합니다. double P = 1.0/(baseval*server.lfu_log_factor+1);
- R < P 이면 증가시킵니다. if (R < P) counter++;
이 표는 아래 명령을 실행했을 때 얻은 데이터입니다.
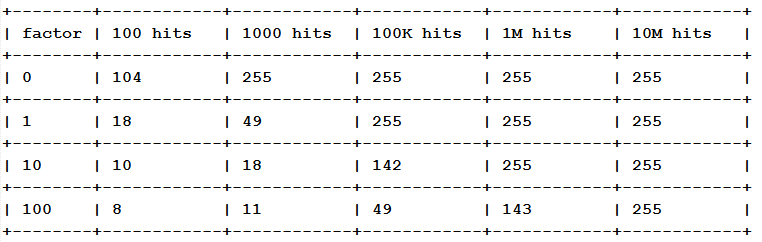 redis-benchmark -n 1000000 incr foo
redis-benchmark -n 1000000 incr foo
redis-cli object freq foo
새 키의 초기값은 5입니다.
Decay-time은 값을 감소시키는 시간(분)입니다.
# lfu-log-factor 10
# lfu-decay-time 1
REPLICATION
REPLICAOF
Master-Replica 복제.
Replicaof 지시자(명령)을 사용해서 레디스 서버의 복제본을 만들 수 있습니다.
- 복제는 비동기이지만 지정한 수의 복제가 실행되지 못하면 마스터 서버가 더 이상 데이터를 받아들이지 않게 설정할 수 있습니다.
- 마스터와 복제 서버간 짧은 시간 연결이 끊겼을 경우 부분 재동기를 할 수 있습니다. 복제 백로그 크기(replication backlog size)를 조정해서 부준 재동기 시간을 간접적으로 조정할 수 있습니다.
- 복제는 자동으로 사용자의 개입이 필요하지 않습니다. 복제 서버가 마스터에 재 연결되면 자동으로 복제를 수행합니다.
# replicaof <masterip> <masterport>
more info
버전 4까지는 slaveof를 사용했고, 5부터 replicaof를 사용합니다.
MASTERAUTH
이 서버가 복제이고 마스터 서버에 password를 설정했을 경우 마스터 서버의 password를 여기에 적습니다. Masterauth가 없으면 마스터 서버는 복제 요청을 거부합니다.
# masterauth <master-password>
MASTERUSER
Redis ACL(Redis 버전 6 이상)을 사용하고 기본 사용자가 복제에 필요한 PSYNC 명령과/또는 기타 명령을 실행할 수 없는 경우에는 충분하지 않습니다. 이 경우 복제에 사용할 특수 사용자를 구성하고 다음과 같이 masteruser 구성을 지정하는 것이 좋습니다.
# masteruser <username>
REPLICA-READ-ONLY
복제 서버에 조회 전용 여부를 설정합니다.
복제 서버에 임시 데이터를 저장하는데 사용할 수도 있습니다만,
복제 서버는 마스터와 재동기화를 하면 임시로 저장된 데이터는 지워집니다.
쓰기를 허용했을 경우 잘못된 클라이언트 구성으로 복제 서버를 마스터로 오인하여
쓰기를 할 수 도 있습니다.
레디스 서버 2.6부터 복제 서버는 디폴트로 조회 전용입니다.
주의: 조회 전용 모드가 인터넷의 신뢰할 수 없는 클라이언트에 방어하도록
설계된 것은 아닙니다. 단지, 잘못된 사용을 막기 위한 보호 장치입니다.
조회 전용이지만 CONFIG, DEBUG 같은 명령으로 복제 서버에 손상을 입힐 수 있습니다.
이를 방지하기 위해서 제한적으로 'rename-command'로 보안을 향상시킬 수 있습니다.
replica-read-only yes more info
REPL-BACKLOG-SIZE
복제 백로그(replication backlog)는 마스터와 복제 서버간 연결이 끊어졌을 때
복제 서버에 보낸 데이터를 잠시 동안 저장하는 버퍼입니다.
복제 서버가 다시 연결되었을 때 부분 동기화를 합니다.
복제 백로그가 클 수록 부분 동기화를 할 수 있는 시간이 길어집니다.
이 백로그는 복제 서버가 접속했을 때 할당됩니다.
repl-backlog-size 1mb recommend 64mb more info
CLONE-BACKLOG-SIZE
Enterprise 서버 Active-Active 동기화 시에 사용됩니다.
서버간 동기화 시 보낸 데이터를 잠시 동안 저장하는 버퍼입니다.
서버간 연결이 잠시 끊어졌다가 다시 연결되었을 때
이 버퍼에 저장된 것으로 동기화를 합니다.
이 백로그가 클 수록 부분 동기화를 할 수 있는 시간이 길어집니다.
이 백로그는 동기화 서버가 접속했을 때 할당됩니다.
Enterprise 서버에서는 동기화를 사용하기 때문에 위에 설명한 repl-backlog-size는 일반적인
상황에서는 사용하지 않습니다.
기본 값은 128mb입니다.
이 파라미터는 Enterprise 7.2.0부터 사용 가능합니다.
clone-backlog-size 128mb
REPL-BACKLOG-TTL
마스터는 복제 서버와 연결 해재된 후 일정시간이 지나면 백로그 메모리를 해제(free)합니다.
복제 서버는 백로그를 해제하지 않습니다. 왜냐하면 나중에 마스터로 승격했을 때
다른 복제 서버와 부분 동기화를 하기 위해서 입니다.
따라서 복제 서버는 항상 데이터를 백로그에 쌓아놓습니다.
more info
0로 설정하면 백로그 버퍼를 해제하지 않습니다.
# repl-backlog-ttl 3600
REPL-PING-REPLICA-PERIOD
복제 서버는 미리 설정된 간격마다 마스터 서버에 PING일 보냅니다.
이것은 repl-timeout을 정하는데 사용됩니다.
디폴트는 10초이고, 변경할 수 있습니다.
# repl-ping-replica-period 10
REPL-TIMEOUT
아래 조건에 따라 복제 타임아웃이 설정됩니다.
- 복제 서버 관점: 마스터로 부터 데이터가 timeout 시간 동안 오지 않거나 ping에 응답이 없을 때
- 복제 서버 관점: 동기화(sync) 중 마지막 전송 받은 시간이 timemout 시간을 초과할 때
- 마스터 서버 관점: 복제 서버로 replconf에 대한 응답(ack)가 timemout 시간 동안 없을 때
repl-ping-replica-period 보다 길게 설정해야 합니다. 그렇지 않으면 매번 타임아웃이 됩니다.
# repl-timeout 60 more info
REPLICA-SERVE-STALE-DATA
복제 서버가 마스터와의 연결이 끊겼을 때 (repl-timeout 시간이 지났거나, 마스터 서버가 실제로 다운되었을 경우) 복제 서버는 설정에 따라 동작합니다.
- yes: 클라이언트의 요청에 응답합니다.
-
no 일 때: 클라이언트가 요청하면
"(error) MASTERDOWN Link with MASTER is down and replica-serve-stale-data is set to 'no'." 에러를 리턴합니다.
단 다음 명령은 정상응답합니다.
INFO, replicaOF, AUTH, PING, SHUTDOWN, REPLCONF, ROLE, CONFIG, SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE, PUBLISH, PUBSUB, COMMAND, LATENCY.
replica-serve-stale-data yes
REPLICA-PRIORITY
마스터가 다운되었을 때 센티널이 복제 서버 중 하나를 선택해서
마스터로 승격시킬때 사용되는 첫번째 조건이다.
낮은 숫자에 우선권이 부여됩니다.
예를 들어 10, 100, 25가 있으면 센티널은 replica-priority가 10인 복제노드를
선택합니다.
그러나 특별하 우선순위인 0은 마스터로 승격되지 않습니다.
Info replication 명령으로 확인할 수 있습니다.
replica-priority 100 more info
REPL-DISKLESS-SYNC
전체 데이터 동기화(Full Sync) 방식 선택: 디스크 또는 소켓(socket)
버전 3.0부터 사용 가능, default no (3.0 ~ 6.x), yes (7.0 ~ )
- 디스크 방식: 마스터는 데이터를 rdb 파일로 디스크에 저장한 다음 복제 서버에 전송합니다.
- Socket(diskless) 방식: 마스터는 데이터를 복제 서버 소켓에 직접 씁니다. 마스터 서버는 디스크를 사용하지 않습니다. 하지만 복제 서버는 소켓 데이터를 받아서 디스크에 rdb 파일로 저장한 다음 로드합니다.
디스크 방식 동기화는 rdb 파일을 생성하는 동안 다른 복제 서버의 요청을 받아서
파일 작성이 완료되면 파일을 여러 복제 서버에 전송합니다.
소켓 방식은 한번 데이터 전송이 시작되면 다른 복제 서버의 요청은 첫번째
요청한 복제 서버에 전송이 완료되면 시작합니다.
소겟 방식은 여러 복제 서버의 요청을 병렬로 한번에 처리하기 위해
일정 시간(초) 동안 요청을 기다리게 설정할 수 있습니다.
네트워크가 빠르고 디스크는 느린 경우 소켓 방식이 더 유리할 수 있습니다.
repl-diskless-sync no recommend yes more info
REPL-DISKLESS-SYNC-DELAY
소켓 복제의 경우 여러 복제 요청을 한번에 처리할 수 있도록
전송 시작 시간을 늦출 수 있습니다.
전송이 시작되면 이후 들어온 요청은 먼저 요청이 완료된 후 시작할 수 있습니다.
대기 시간은 기본적으로 5초입니다.
0으로 설정하면 즉시 전송합니다.
repl-diskless-sync-delay 5 recommend 0 more info
REPL-DISKLESS-LOAD
버전 6.0부터 사용 가능, default disabled
경고: RDB 디스크 없는 로드는 실험적입니다.
이 설정에서 복제본은 RDB를 디스크에 즉시 저장하지 않으므로
장애 조치 중에 데이터가 손실될 수 있습니다.
RDB 디스크 없는 로드 + I/O 읽기를 처리하지 않는 Redis 모듈은
마스터와의 초기 동기화 단계에서 I/O 오류가 발생하는 경우 Redis가 중단되도록 할 수도 있습니다.
무엇을 하고 있는지 알고 있는 경우에만 사용하십시오.
복제 서버(Replica)는 소켓에서 직접 복제 링크에서 읽은 RDB를 로드하거나
RDB를 파일에 저장하고 마스터에서 완전히 수신한 후 해당 파일을 읽을 수 있습니다.
대부분의 경우 디스크는 네트워크보다 느리며 RDB 파일을 저장하고 로드하면
복제 시간이 늘어날 수 있습니다(또한 마스터의 Copy on Write 메모리 및 저장 버퍼도 증가).
그러나 소켓에서 직접 RDB 파일을 구문 분석하는 것은 전체 rdb를 받기 전에
현재 데이터베이스의 내용을 플러시해야 함을 의미 할 수 있습니다.
이러한 이유로 다음과 같은 옵션이 있습니다.
- disabled - 디스크 없는 로드를 사용하지 않음(먼저 rdb 파일을 디스크에 저장)
- on-empty-db - 완전히 안전한 경우에만 디스크 없는 로드를 사용합니다.
- swapdb - 소켓에서 직접 데이터를 구문 분석하는 동안 RAM에 현재 db 내용의 사본을 보관합니다. 메모리가 충분하지 않으면 메모리 부족으로 레디스 서버가 죽을 수 있습니다.
repl-diskless-load disabled
REPL-DISABLE-TCP-NODELAY
이것은 마스터와 복제 서버간 Full Sync가 수행될 경우 적용됩니다.
- yes: 데이터를 모아서 큰 패킷으로 전송합니다. 마스터와 복제 서버간 여러 네트워크 장비가 있는 경우 또는 대역폭(bandwidth)이 작고 원거리인 경우 유리할 수 있습니다. 리눅스 커널의 디폴트 구성을 사용할 경우 복제 서버로 데이터를 보내는데 최대 40ms의 지연이 발생할 수 있습니다.
- no: 기본 설정입니다. Yes보다 대역폭을 좀 더 사용합니다.
repl-disable-tcp-nodelay no more info
MIN-REPLICAS-TO-WRITE, MIN-REPLICAS-MAX-LAG
- min-replicas-to-write: 복제가 성공적으로 수행되어야하는 최소한의 복제 노드 수를 설정합니다. 복제 노드가 설정한 수 보다 적으면 마스터는 쓰기 명령을 수행하지 못하고 에러를 리턴합니다.
- min-replicas-max-lag: 복제가 성공적으로 수행되어야하는 시간(초)를 설정합니다. 이 시간은 마스터가 복제 노드에 1초마다 보내는 replconf의 ack로 확인합니다. Repl-timeout으로 확인하는 것이 아닙니다.
복제 노드로 부터 Ack를 받어서 응답하는 것은 아닙니다. 설정에 만족하는 min_slaves_good_slaves 값을 체크합니다. min_slaves_good_slaves 값은 info replication 명령으로 확인할 수 있습니다.
# min-replicas-to-write 3
more info
# min-replicas-max-lag 10
more info
둘 중 하나만 0으로 설정해도 이 기능은 비활성화됩니다.
디폴트 값은 min-replicas-to-write가 0이고
min-replicas-max-lag는 10입니다.
REPLICA-ANNOUNCE-IP, REPLICA-ANNOUNCE-PORT
레디스 마스터는 연결된 복제 서버의 주소를 announce-ip/port로 보여줍니다.
예를 들어, "info replication" 또는 "role" 명령을 실행하면
복제(slave) 노드 주소로 announce-ip/port를 보여줍니다.
레디스 센티널도 복제 서버를 찾는데 announce-ip/port를 사용합니다.
포트 포워딩(port forwarding)을 사용하면 해당 IP:Port로 연결할 수 있습니다.
# replica-announce-ip 5.5.5.5
# replica-announce-port 1234
KEYS TRACKING
TRACKING-TABLE-MAX-KEYS
Redis는 클라이언트 측 값 캐싱에 대한 서버 지원 지원을 구현합니다.
이것은 키 이름으로 색인된 기수 키를 사용하여 클라이언트가 어떤 키를 가지고 있는지
기억하는 무효화 테이블을 사용하여 구현됩니다.
차례로 이것은 무효화 메시지를 클라이언트에 보내기 위해 사용됩니다.
기능에 대해 자세히 알아 보려면이 페이지를 확인하십시오.
Server-assisted Client side caching
클라이언트에 대해 추적이 활성화되면 모든 읽기 전용 쿼리가 캐시된 것으로 간주됩니다.
이렇게 하면 Redis가 무효화 테이블에 정보를 저장하게 됩니다.
키가 수정되면 이러한 정보가 삭제되고 무효화 메시지가 클라이언트에 전송됩니다.
그러나 워크로드가 읽기에 크게 좌우되는 경우 Redis는 많은 클라이언트가 가져온 키를
추적하기 위해 점점 더 많은 메모리를 사용할 수 있습니다.
이러한 이유로 무효화 테이블의 최대 채우기 값을 구성할 수 있습니다.
기본적으로 1M의 키로 설정되며,이 제한에 도달하면 Redis는 메모리를 회수하기
위해 수정되지 않은 경우에도 무효화 테이블의 키를 제거하기 시작합니다.
그러면 클라이언트가 캐시된 값을 무효화하게 됩니다.
기본적으로 테이블 최대 크기는 누가 무엇을 캐시했는지에
대한 정보를 추적하기 위해 서버 측에서 사용하려는 메모리와 캐시된
객체를 메모리에 유지하는 클라이언트의 능력 사이의 균형입니다.
값을 0으로 설정하면 제한이 없음을 의미하며 Redis는 무효화 테이블에 필요한 만큼의 키를 유지합니다.
INFO stats섹션에서 주어진 순간에 무효화 테이블의 키 수에 대한 정보를 찾을 수 있습니다.
참고: 브로드 캐스팅 모드에서 키 추적을 사용하면 서버 측에서 메모리가 사용되지 않으므로
이 설정은 쓸모가 없습니다.
tracking-table-max-keys 1000000
LAZY FREEING
이 기능은 버전 4.0에 도입되었습니다.
레디스에서 키(데이터)를 삭제하는 방식은 두 가지가 있습니다.
- DEL: 명령이 실행되면 바로 데이터를 지웁니다. 키의 데이터 타입이 스트링(string)이거나 리스트(list), 셋(set)같은 데이터 타입도 맴버수가 적으면 삭제하는데 짧은 시간이 걸리기 때문에 문제 되지 않습니다. 하지만 맴버수가 수백만, 수천만 개라면 삭제하는데 수 초, 수십 초가 걸릴 수 있습니다. 데이터를 지우는 동안 새 명령을 실행할 수 없습니다. 이것을 블락킹(blocking) 오퍼레이션이라고 합니다.
- UNLINK: 명령이 실행되면 일단 키는 지우고 남은 맴버는 별도 쓰레드인 LAZY_FREE에서 삭제합니다. 바로 새 명령을 실행할 수 있습니다. 이것을 넌 블락킹(non blocking) 오퍼레이션이라고 합니다.
여기 네 가지 파라미터는 서버에서 키(데이터)를 삭제하는 작업으로 넌 블락킹 오퍼레이션으로 처리할지 여부를 설정합니다.
LAZYFREE-LAZY-EVICTION
Yes로 설정하면 maxmemory 정책으로 키를 삭제할 때 UNLINK를 사용합니다.
lazyfree-lazy-eviction no recommend yes
LAZYFREE-LAZY-EXPIRE
Yes로 설정하면 만료된(expired) 키를 삭제할 때 UNLINK를 사용합니다.
lazyfree-lazy-expire no recommend yes
LAZYFREE-LAZY-SERVER-DEL
RENAME 명령을 사용하면 기존 키와 값을 삭제하고 키 이름을 변경합니다.
RENAME A B 일 때 B가 백만개의 멤머를 가지고 있는 셋(Set)이었다면
B를 삭제하는데 시간이 걸릴 것입니다.
Yes로 설정하면 이 경우에도 UNLINK 명령을 사용합니다.
SUNIONSTORE 같은 명령도 해당됩니다.
lazyfree-lazy-server-del no recommend yes
LAZYFREE-LAZY-USER-DEL
Yes로 설정하면 DEL 명령이 내부적으로 UNLINK 명령으로 동작합니다. UNLINK 명령은 비동기로(async)로 키를 삭제해서 응답이 빠릅니다.
lazyfree-lazy-user-del no recommend yes 6.0부터 사용 가능
REPLICA-LAZY-FLUSH
전체 동기화(Full Sync)할 때 복제 서버는 자신이 기존에 가지고 있는 모든 데이터를 지웁니다.
Yes로 설정하면 Flushall async로 지웁니다.
No: Flushing old data 시간을 보세요.
Yes
replica-lazy-flush no recommend yes
THREADED I/O
Redis is mostly single threaded, however there are certain threaded operations such as UNLINK,
slow I/O accesses and other things that are performed on side threads.
Redis는 대부분 단일 스레드이지만 UNLINK, 느린 I/O 액세스 및 측면 스레드에서 수행되는 기타 작업과 같은 특정 스레드 작업이 있습니다.
Now it is also possible to handle Redis clients socket reads and writes in different I/O threads.
Since especially writing is so slow, normally Redis users use pipelining in order to speed up
the Redis performances per core, and spawn multiple instances in order to scale more.
Using I/O threads it is possible to easily speedup two times Redis without resorting to pipelining nor sharding of the instance.
이제 다양한 I/O 스레드에서 Redis 클라이언트 소켓 읽기 및 쓰기를 처리하는 것도 가능합니다.
특히 쓰기 속도가 너무 느리기 때문에 일반적으로 Redis 사용자는 코어당 Redis 성능 속도를 높이기 위해
파이프라인을 사용하고 더 많은 확장을 위해 여러 인스턴스를 생성합니다.
I/O 스레드를 사용하면 인스턴스의 파이프라인이나 샤딩에 의존하지 않고도 Redis 속도를 두 배로 쉽게 높일 수 있습니다.
By default threading is disabled, we suggest enabling it only in machines that have at least 4 or more cores,
leaving at least one spare core.
Using more than 8 threads is unlikely to help much.
We also recommend using threaded I/O only if you actually have performance problems,
with Redis instances being able to use a quite big percentage of CPU time,
otherwise there is no point in using this feature.
기본적으로 스레딩은 비활성화되어 있으므로 코어가 4개 이상인 시스템에서만 활성화하고
예비 코어를 하나 이상 남겨 두는 것이 좋습니다.
8개 이상의 스레드를 사용하는 것은 별 도움이 되지 않습니다.
또한 실제로 성능 문제가 있는 경우에만 스레드 I/O를 사용하는 것이 좋습니다.
Redis 인스턴스는 CPU 시간의 상당 부분을 사용할 수 있습니다.
그렇지 않으면 이 기능을 사용할 필요가 없습니다.
So for instance if you have a four cores boxes, try to use 2 or 3 I/O threads, if you have a 8 cores,
try to use 6 threads. In order to enable I/O threads use the following configuration directive:
예를 들어 코어 상자가 4개라면 2개 또는 3개의 I/O 스레드를 사용해 보고,
코어가 8개라면 스레드 6개를 사용해 보세요.
I/O 스레드를 활성화하려면 다음 구성 지시문을 사용하십시오.
io-threads 4
Setting io-threads to 1 will just use the main thread as usual.
When I/O threads are enabled, we only use threads for writes, that is to thread the write(2) syscall and transfer the client buffers to the socket.
However it is also possible to enable threading of reads and protocol parsing using the following configuration directive, by setting it to yes:
io-threads를 1로 설정하면 평소처럼 메인 스레드만 사용됩니다.
I/O 스레드가 활성화되면 쓰기용 스레드만 사용합니다. 즉, write(2) 시스템 호출을 스레드하고 클라이언트 버퍼를 소켓으로 전송하는 것입니다.
그러나 다음 구성 지시문을 yes로 설정하여 읽기 스레딩 및 프로토콜 구문 분석을 활성화할 수도 있습니다.
io-threads-do-reads no
Usually threading reads doesn't help much.
일반적으로 스레딩 읽기는 별로 도움이 되지 않습니다.
NOTE 1: This configuration directive cannot be changed at runtime via CONFIG SET.
Also, this feature currently does not work when SSL is enabled.
참고 1: 이 구성 지시문은 CONFIG SET을 통해 런타임에 변경할 수 없습니다.
또한 SSL이 활성화된 경우 현재 이 기능이 작동하지 않습니다.
NOTE 2: If you want to test the Redis speedup using redis-benchmark, make sure you also run the benchmark itself in threaded mode,
using the --threads option to match the number of Redis threads, otherwise you'll not be able to notice the improvements.
참고 2: redis-benchmark를 사용하여 Redis 속도 향상을 테스트하려면 Redis 스레드 수와 일치하도록 --threads 옵션을 사용하여
스레드 모드에서도 벤치마크 자체를 실행해야 합니다. 그렇지 않으면 수행할 수 없습니다. 개선 사항을 확인하십시오.
LUA SCRIPTING
LUA-TIME-LIMIT
루아 스트립트(Lua script) 최대 실행 시간(ms)
루아 스크립트가 최대 실행 시간까지도 끝나지 않으면 로그를 남기고
새 쿼리(query)에 에러를 리턴합니다.
최대 실행 시간을 초과하면 SCRIPT KILL과 SHUTDOWN NOSAVE 명령만 사용할 수 있습니다.
실행 시간 제한을 두지 않으려면 0이나 음수로 설정하세요.
lua-time-limit 5000
SLOW LOG
SLOWLOG-LOG-SLOWER-THAN
레디스 슬로우 로그(Slow log)는 설정한 실행 시간을 초과하는 쿼리들을
기록에 남기는 시스템입니다.
실행 시간(execution time)은 서버 내에서 처리 시간만 포함합니다.
클라이언트와 통신하거나 응답을 보내는 등의 시간은 제외합니다.
슬로우 로그는 2개의 파라미터를 설정할 수 있습니다.
첫 번째 파라미터는 마이크로초(microsecond)로 실행 시간을 설정합니다.
두 번째 파라미터는 기록을 몇 개나 남길지를 설정합니다.
오래된 기록은 새것으로 대체됩니다.
1000000 us(microseconds)는 1초를 나타냅니다.
음수로 설정하면 슬로우 로그를 비활성화합니다.
0으로 설정하면 모든 명령을 로그합니다.
디폴트는 10000us(10ms)입니다.
slowlog-log-slower-than 10000 more info
SLOWLOG-MAX-LEN
이 값에 제한은 없습니다. 단지, 해당하는 만큼 메모리를 사용합니다. SLOWLOG RESET 명령으로 로그를 지울 수 있습니다.
slowlog-max-len 128
SLOWLOG-LOG-FILE
Slowlog log file을 지정합니다. 디폴트는 slowlog.log 입니다.
Comment 처리하면 디폴트가 적용됩니다.
지정하지 않으려면 ""를 사용하세요. 그러면 redis.log 파일에 기록됩니다.
이 기능은 Enterprise 버전에서 사용할 수 있습니다.
slowlog-log-file "slowlog.log"
SLOWLOG-INTERVAL-TIME
Slowlog 기록 시간(interval)을 초로 지정합니다. 디폴트는 60초(1분)입니다.
1초부터 지정할 수 있고, 0을 지정하면 기록하지 않습니다.
Slowlog 내용이 없으면 기록 시간이 되어도 기록하지 않습니다.
이 기능은 Enterprise 버전에서 사용할 수 있습니다.
slowlog-interval-time 60
LATENCY MONITOR
LATENCY-MONITOR-THRESHOLD
Latency Monitor는 레디스 내부 처리 시간을 모니터할 수 있습니다.
특히 AOF 관련 여러 가지 내부 처리 시간을 알아볼 수 있습니다.
Latency 명령으로 이런 정보를 그래프나 리포트로 사용자에게 제공합니다.
설정된 시간(millisecond) 이상으로 수행되는 오퍼레이션을 기록합니다.
0으로 설정하면 이 기능이 비활성화됩니다.
디폴트값은 0입니다. 응답시간 이슈가 발생하면 사용하세요.
레디스 서버 운영중에 "CONFIG SET latency-monitor-threshold <milliseconds>"
명령으로 설정할 수 있습니다.
latency-monitor-threshold 0 more info
LATENCY-LOG-FILE
Latency log file을 지정합니다. 디폴트는 latency.log 입니다.
Comment 처리하면 디폴트가 적용됩니다.
지정하지 않으려면 ""를 사용하세요. 그러면 redis.log 파일에 기록됩니다.
이 기능은 Enterprise 버전에서 사용할 수 있습니다.
latency-log-file "latency.log"
LATENCY-INTERVAL-TIME
Latency 기록 시간(interval)을 초로 지정합니다. 디폴트는 60초(1분)입니다.
1초부터 지정할 수 있고, 0을 지정하면 기록하지 않습니다.
Latency 내용이 없으면 기록 시간이 되어도 기록하지 않습니다.
latency-interval-time 60
EVENT NOTIFICATION
NOTIFY-KEYSPACE-EVENTS
레디스는 키 변경 이벤트를 Pub/Sub 클라이언트에게 알릴 수 있습니다.
http://redis.io/topics/notifications
PUBLISH __keyspace@0__:key del
PUBLISH __keyevent@0__:del key
이벤트를 선택해서 받을 수 있습니다.
- K Keyspace events, publish prefix "__keyspace@<db>__:".
- E Keyevent events, publish prefix "__keyevent@<db>__:".
- g 공통 명령: del, expire, rename, ...
- $ 스트링(String) 명령
- l 리스트(List) 명령
- s 셋(Set) 명령
- h 해시(Hash) 명령
- z 소트 셋(Sorted set) 명령
- x 만료(Expired) 이벤트 (키가 만료될 때마다 생성되는 이벤트)
- e 퇴출(Evicted) 이벤트 (최대메모리 정책으로 키가 삭제될 때 생성되는 이벤트)
- A 모든 이벤트(g$lshzxe), "AKE"로 지정하면 모든 이벤트를 받는다.
"notify-keyspace-events"는 여러개 문자로 구성할 수 있습니다.
빈 문자열(empty string)은 이 기능을 비활성화합니다.
이 기능은 어느 정도의 오버헤드(overhead)가 있습니다.
notify-keyspace-events ""
REDIS CLUSTER
CLUSTER-ENABLED
클러스터 모드 사용 여부
# cluster-enabled yes more info
CLUSTER-CONFIG-FILE
모든 클러스터 노드는 클러스터 구성 파일을 가지고 있습니다. 이 파일은 레디스가 생성하고 업데이트합니다. 따라서 수기로 수정하지 않습니다. 클러스터 구성 파일 이름이 다른 클러스터 노드와 중복되지 않도록 주의해주세요.
# cluster-config-file nodes-6379.conf more info
CLUSTER-NODE-TIMEOUT
클러스터 노드 타임아웃은 밀리초(millisecond)로 지정하며, 이 시간 동안 연결이 끊기면 다운된 것으로 간주합니다. 대부분의 다른 내부 시간 제한이 이 타임아웃 시간의 배수입니다.
# cluster-node-timeout 15000 recommend 3000 more info
CLUSTER-REPLICA-VALIDITY-FACTOR
마지막 교신 시간이 아래 계산식의 결과보다 큰 경우 (복제 데이터가 너무 오래되었다고 판단하는 기준) 마스터로 승격되지 못합니다.
(cluster-node-timeout * cluster-replica-validity-factor) + repl-ping-replica-period
예를 들어,
cluster-node-timeout이 30초이고,
cluster-replica-validity-factor가 10이고,
repl-ping-replica-period가 10초이면,
복제 노드는 마스터와 마지막 교신 시간 310초보다 크면 마스터로 승격되지 못합니다.
이 값(cluster-replica-validity-factor)을 크게 잡으면
너무 오래된 데이터를 가진 복제 노드가 마스터가 될 수 있고,
너무 작게 잡으면 복제 노드가 마스터로 승격되지 못할 수도 있습니다.
비활성화하려면 0으로 설정합니다.
# cluster-replica-validity-factor 10 more info
CLUSTER-MIGRATION-BARRIER
클러스터는 가능한 마스터 당 이 값 이상의 복제 노드를 가지도록 노력합니다.
마스터 A는 복제 노드가 없고, 마스터 B는 복제 노드가 2개 있다면
마스터 B에 있는 복제 노드 1개를 마스터 A의 복제 노드로 이전 시킵니다.
이 기능을 사용하지 않으려면 매우 큰 값으로 설정하세요.
운영 환경에서는 0으로 설정하는 것은 권장하지 않습니다.
# cluster-migration-barrier 1 more info
CLUSTER-REQUIRE-FULL-COVERAGE
마스터 노드 다운 시 클러스터 전체를 사용하지 못하게 할지, 다운된 노드를 제외한 나머지 노드들은 정상 운영 할지를 정합니다.
- Yes: 마스터 노드 다운 시 클러스터가 다운됩니다.
- No: 마스터 노드가 다운 되더라도 나머지 마스터 노드들은 정상 운영합니다. 하지만 이 경우에도, 반 이상의 마스터 노드가 다운되면 클러스터가 다운됩니다.
# cluster-require-full-coverage yes recommend no more info
CLUSTER-REPLICA-NO-FAILOVER
이 옵션은 복제 노드가 마스터로 승격되지 않도록 합니다.
여러 데이터 센터가 있을 때 다른 데이터 센터의 복제 노드가
마스터로 승격되는 것을 막을 때 유용하게 사용할 수 있습니다.
메뉴얼(cluster failover)로는 가능합니다.
# cluster-replica-no-failover no
CLUSTER DOCKER/NAT support
CLUSTER-ANNOUNCE-IP/PORT/BUS-PORT
일반적으로 도커(docker) 사용 시 이 기능을 사용합니다.
포트 포워딩(port forwarding) 또는 NAT(Network Address Translation)로
announce-ip/port에 연결합니다.
이 재지정(remap)옵션을 사용하면 cluster bus port를 설정할 수 있습니다.
즉, 고정된 포트(client port + 10000)가 아닐 수 있습니다.
cluster bus port를 지정하지 않으면 고정된 포트가 사용됩니다.
# cluster-announce-ip 10.1.1.5
# cluster-announce-port 6379
# cluster-announce-bus-port 6380
ADVANCED CONFIG
LIST-MAX-ZIPLIST-SIZE
리스트도 메모리를 절약하기 위한 데이터 구조를 사용합니다. 내부 리스트 노드당 노드 크기나 노드당 엔티리수를 지정합니다. -5에서 -1까지는 노드 크기를 나타냅니다.
-5: max size: 64 Kb
-4: max size: 32 Kb
-3: max size: 16 Kb
-2: max size: 8 Kb <-- 디폴트
-1: max size: 4 Kb
양수는 노드당 엔트리수를 나타냅니다. 일반적으로 높은 성능을 내기 위해서 -2나 -1을 사용합니다. 하지만 경우에 따라 적절한 값으로 설정할 수 있습니다.
list-max-ziplist-size -2 more info
LIST-COMPRESS-DEPTH
리스트는 데이터 압축이 가능합니다.
이 값은 리스트 양쪽 끝을 기준으로 압축하지 않을 노드를 나타냅니다.
리스트의 앞과 뒤 노드는 빠르게 PUSH/POP 오퍼레이션을 처리하기 위해서 압축하지 않습니다.
- 0: 모든 노드를 압축하지 않습니다.
- 1:
앞, 뒤 양쪽 노드 하나씩 압축하지 않고
가운데 노드 모두를 압축합니다.
[head]->node->node->...->node->[tail] - 2:
양쪽 노드 두 개씩 압축하지 않고 가운데 노드는 압축합니다.
[head]->[next] ->node->node->...->node-> [prev]->[tail] - 3: [head]->[next]->[next] ->node->node->...->node-> [prev]->[prev]->[tail]
- 4,5,...
list-compress-depth 0 recommend 1 more info
SET-MAX-INTSET-ENTRIES
셋(Set)은 모든 원소가 10진 숫자로만 구성된 문자열일 때 특별히 메모리 절약 데이터 구조를 사용합니다. 이 값은 메모리 절약 데이터 구조를 사용할 원소수를 설정합니다.
set-max-intset-entries 512 more info
ZSET-MAX-ZIPLIST-ENTRIES, ZSET-MAX-ZIPLIST-VALUE
Sorted Set도 멤버 수가 설정한 수 이하이거나 값(value)이 작을 경우 메모리 절약을 위한 특별한 데이터 구조를 사용합니다.
zset-max-ziplist-entries 128
more info
zset-max-ziplist-value 64
more info
HASH-MAX-ZIPLIST-ENTRIES, HASH-MAX-ZIPLIST-VALUE
해시는 필드수가 적거나 값의 크기가 적을 때는 메모리 절약을 위한 데이터 구조를 사용합니다. 아래 지시자로 필드수와 값의 크기를 조정할 수 있습니다.
hash-max-ziplist-entries 512
more info
hash-max-ziplist-value 64
more info
HLL-SPARSE-MAX-BYTES
hll-sparse-max-bytes 3000 more info
STREAM-NODE-MAX-BYTES, STREAM-NODE-MAX-ENTRIES
스트림 메크로 노드의 크기와 아이템 수를 설정합니다. 스트림 데이터 구조는 노드에 여러 아이템을 넣는 기수 트리(radis tree)입니다. 두 값이 다 있을 경우(0이 아닐 경우)는 and 조건이지만 하나가 0이면 다른 하나의 값만 적용됩니다.
stream-node-max-bytes 4096
more info
stream-node-max-entries 100
ACTIVEREHASHING
재해싱(Rehashing)은 메인 해시 테이블이 확장되었을 때 키들을 확장된 해시 테이블로 옮기는 작업입니다. 기본적으로 재해싱 작업은 100밀리초마다 1밀리초씩 수행합니다. Activerehashing이 yes이면 재해싱 작업에 1밀리초를 더 할당해서 100밀리초마다 2밀리초씩 수행합니다. 이것은 기존 해시 테이블이 사용하는 메모리를 좀 더 빨리 해제하는데 도움이 됩니다.
activerehashing yes
activerehashing은 버전 2부터(2010년) 도입되었다.
HZ
레디스는 내부적으로 타임아웃된 클라이언트 연결 해제, 만료된 키 삭제와 같은
많은 백그라운드 작업을 수행합니다.
모든 작업이 동일한 빈도로 수행되는 것은 아니지만,
레디스는 지정된 "hz" 값에 따라 수행할 작업을 확인합니다.
디폴트 값은 10입니다.
1에서 500사이 값을 지정할 수 있습니다.
일반적으로 100이상은 권장하지 않습니다.
대부분의 사용자는 디폴트 값인 10을 권장합니다.
hz 10
DYNAMIC-HZ
일반적으로 연결된 클라이언트의 수에 비례하는 HZ 값을 갖는 것이 유용합니다.
예를 들어 응답 시간 급증을 방지하기 위해 백그라운드 작업 호출마다
처리되는 클라이언트가 너무 많지 않게 하는 것이 좋습니다.
기본 HZ를 보수적으로 10을 사용하기 때문에,
레디스는 디폴트로 많은 클라이언트가 연결될 때 적응형(adaptive) HZ를 사용합니다.
동적(dynamic) hz가 활성화되면, 더 많은 클라이언트가 연결되면
필요에 따라 기본 hz의 배수가 사용됩니다.
CONFIG_DEFAULT_HZ 10
CONFIG_MAX_HZ 500
MAX_CLIENTS_PER_CLOCK_TICK 200
client수가 2000을 초과하면 hz를 20으로 조정합니다.
client수가 4000을 초과하면 hz를 40으로 조정합니다.
hz는 최대 500까지 조정될 수 있습니다.
dynamic-hz yes
ACTIVE DEFRAGMENTATION
ACTIVEDEFRAG
이 기능은 실험적입니다만, 운영환경에서도 스트레스 테스트를 거쳤으며,
여러 엔지니어가 수작업으로 테스트했습니다.
활성 조각모음이란?
온라인 활성 조각모음을 사용하면 레디스가 메모리 할당과 해제 사이에
남은 공간을 압축(compact)하여 메모리를 회수할 수 있습니다.
단편화는 모든 할당자(그러나 다행스럽게도 Jemalloc에서는 그리 중요하지 않음)
및 특정 작업 부하에서 발생하는 자연스러운 과정입니다.
일반적으로 서버를 다시 시작해야 조각화를 줄이거나
모든 데이터를 버리고 다시 만들 수 있습니다.
그러나 Oran Agra가 Redis 4.0 용으로 구현한이 기능 덕분에
이 프로세스는 서버가 실행되는 동안 런타임에 "최신"방식으로 발생할 수 있습니다.
기본적으로 조각화가 특정 레벨을 초과하면 Redis는 특정 Jemalloc 기능을 이용하여
인접한 메모리 영역에서 값의 새로운 복사본을 생성하기 시작합니다
(할당이 조각화를 일으키는지를 이해하고 할당을 할당하기 위해 더 나은 곳에서),
동시에 데이터의 이전 복사본을 릴리스 할 것입니다.
모든 키에 대해 점진적으로 반복되는 이 프로세스로 인해 단편화가 정상 값으로
다시 떨어집니다.
이해해야 할 중요한 사항:
- 이 기능은 기본적으로 사용할 수 없으며 레디스 소스 코드로 제공되는 Jemalloc을 사용하도록 레디스를 컴파일 한 경우에만 작동합니다. 이것은 Linux 빌드의 기본값입니다.
- 단편화 문제가 없는 경우 이 기능을 활성화하지 않아도됩니다.
- 단편화가 발생하면 "CONFIG SET activedefrag yes"명령을 사용하여 필요할 때 이 기능을 활성화 할 수 있습니다.
구성 매개 변수는 조각모음 프로세스의 동작을 미세 조정할 수 있습니다.
# activedefrag yes
ACTIVE-DEFRAG-IGNORE-BYTES
조각모음을 시작하기 위한 최소량: allocator_frag_bytes = active - allocated (info memory)
설정한 값보다 작으면 조각모음을 하지 않습니다.
# active-defrag-ignore-bytes 100mb
ACTIVE-DEFRAG-THRESHOLD-LOWER
조각모음을 시작할 최소 조각화 비율: allocator_frag_ratio = active / allocated
10 보다 작으면 조각모음을 하지 않습니다.
100mb 이상이고 10 이상이어야 조각모음을 시작합니다.
# active-defrag-threshold-lower 10
ACTIVE-DEFRAG-THRESHOLD-UPPER
# active-defrag-threshold-upper 100
ACTIVE-DEFRAG-CYCLE-MIN
- INTERPOLATE(보간법) cpu_pct = ( (cycle-min) + ((frag_pct)-(threshold-lower)) * ((cycle-max)-(cycle-min)) / ((threshold-upper)-(threshold-lower)) )
- 3.89 = ( (5) + ((10)-(10)) * ((75)-(10)) / ((100)-(10)) )
- cycle-min <= cpu_pct <= cycle-max
- timelimit = 1000000 * cpu_pct / hz / 100
- 5000 us = 1000000 * 5 / 10 / 100
- 1초에 5ms를 조각모음에 사용합니다.
- 버전 5.x까지 min 5, max 75 였는데, 버전 6.0부터 min 1, max 25로 변경되었습니다.
# active-defrag-cycle-min 1
ACTIVE-DEFRAG-CYCLE-MAX
# active-defrag-cycle-max 25
ACTIVE-DEFRAG-MAX-SCAN-FIELDS
List/Set/ZSet/Hash/Stream의 필드 수가 이 값보다 크면 이 키들은 모아서 나중에 조각모음합니다.
# active-defrag-max-scan-fields 1000
ENTERPRISE
SYNC-START-WAIT-TIME
Enterprise version 6.1.3에 추가되었습니다.
서버 시작 후 이 시간 동안은 다른 마스터 서버와 동기화를 위한 시간으로
일반 명령의 실행을 막습니다.
왜냐하면 동기화 전에 입력된 데이터(키)는 동기화를 하면 삭제됩니다.
서버 시작 후 첫 번째 마스터와 동기화를 시작해서 데이터를 받고
메모리를 올리는데 까지 걸리는 시간보다 크게 하세요.
해당 시간은 로그를 확인하세요.
디폴트는 60초입니다.
# sync-start-wait-time 60
USE-SQL
Enterprise version 7.2.0에 추가되었습니다.
내부적으로 redisDb.datatypes를 사용 여부를 정하는 parameter입니다.
- yes로 설정하면 datatypes에 skiplist를 구성하고 키 저장시 skiplist에 저장한다.
그러면 ls 명령에서 sort 키 리스트를 조회할 수 있고, sql을 사용할 수 있다. 하지만 메모리를 redis 원래 버전에 비해서 약 2배 정도 더 사용한다. aof 파일 로딩 시간도 더 걸린다. - no로 설정하면 위에서 설명한 기능을 사용할 수 없다. 하지만 메모리는 redis 원래 버전과 비슷하게 사용한다. aof 파일 로딩 시간이 빨라진다.
- sql를 사용하고 system 메모리가 충분하다면 yes로 설정한다. 그렇지 않고 redis 원래 기능에 active-active 이중화 기능을 사용할 목적이면 no로 설정한다.
- default no 이다.
# use-sql no
| << Server Data Structure | Redis.conf eng >> |
|---|
